
Lec01 引入
Lec02 基础
Fully-Connected Layer (Linear Layer)
The output neuron is connected to all input neurons.
Convolution Layer
The output neuron is connected to input neurons in the receptive field.
1D conv, 2D conv, 还要在加上 channel 的维度
- feature map 特征图的大小变化(公式)
- Padding 填充,zero padding, others (reflection, replication, constant …)
- receptive field 感受野(公式)
- strided,在不增加深度的情况下增大感受野
- grouped conv, 减少计算量,初始版本,所有的 channel_i 和 channel_o 都是相连的,参数量会减少到原来的 g 倍(组数倍)
- depthsise conv, 分组卷积的极限情况,
- pooling layer,得到小的特征图,对高分辨率的图,max, average
Normalization Layer
- BN, CNN, HW B
- LN, atention, HW c
- IN, HW
- GN, HW g
Activation Function
- sigmoid, 易于量化quantize,梯度消失
- ReLU, 输入为正不会梯度消失,为负死了,易于实现稀疏性sparsify,不易量化
- ReLU6,最大为6的ReLU,相对易于量化
- Leaky ReLU,为负,失去稀疏性
- Swish,x / (1 + e&-x),硬件实现困难
- Hard Swish
- 0, <= -3
- x, >= 3
- x * (x + 3) / 6
Lab0
熟悉pytorch用法
| |
Lec03 - 04 剪枝
Pruning at different granularities
fine-grained / unstructured, 细粒度剪枝,灵活,剪枝比率高,不好并行化
coarse-grained / structured,
1. pattern-based,提供几种模式,模式旋转等方式,规律性
N2M,N:M sparsity,不如 2:4,M个为一组,至少有N个被置零。
需要用两位来表示非零,为了稀疏,需要花费额外的内存来存储索引
2. vector-level 行
3. Kernel-level 一块
4. channel-level,拿掉一整个通道,加速简单,剪枝率低。
设计不同层的稀疏度,uniform shrink 均匀压缩;xxx
如何得到最佳稀疏度分配?AMC
Pruning Criteria 剪枝标准
选最不重要的,heuristic 启发式
- magnitude-based pruning,基于权重大小,绝对值最小的
- scaling-based pruning,给每一个滤波器一个缩放参数,或者是channel,学n个参数就行,然后再去除靠近零的filter,因为Batch Normalization 中有缩放因子scaling factor,可以用来复用
- second-order-based pruning,泰勒展开 - 海森矩阵 - 近似
- neurons to prune,实际是去掉一行,一块核
- percentage-of-zero-based pruning,用ReLU的时候,会出现零,然后看激活值的零的占比,去掉占比最高的,需要运行,得到activation tensor
- regression-based pruning,
Finding pruning ratios
大部分都是假设层与层之间是独立的
- analyze the sensitivity of each layer,对每一层进行不同程度的剪枝,看准确率下降情况,设定降低5%~10%,画线对应过去,得到横坐标就是剪枝率
- automatic pruning,自动剪枝
- AMC: AutoML for Model Compression,RL
- NetAdapt, rule-based iterative/progressive method,设定减小的延迟latency,每一层看需要剪枝多少才能达成,后面进行short-term fine-tune,在能够得到一样的结果──减小设定的延迟的情况下,选择fine-tune后准确率最高的剪枝,不断迭代,最后整体进行 long-term fune-tune
Fine-tuning pruned neural networks
经验值,把学习率降低10~100倍
- iterative pruning,迭代剪枝,边剪枝边微调,为了70%,经过 30% - 50% - 70%
System & Hardware Support for Sparsity
EiE,权重稀疏 + 激活值稀疏?
对稀疏模型的硬件加速器设计
Tensor Core, M:N Weight Sparsity,相对规则,需要用2bit索引,乘法,用mask掩码
TorchSparsity & PointAcc,激活值稀疏,点云,稀疏卷积,不扩散,保持和输入的稀疏模式一致
自适应分组,MM & BMM
稀疏卷积硬件加速,归并排序找重叠部分
Lab1
实现 VGG 在 Cifar-10 模型的fine-grained pruning细颗粒剪枝与channel pruning通道剪枝。
同时应用了,sensitive敏感性排序,参数量排序等实际优化剪枝的方法
Lec05 量化
data type 数据类型,怎么样表示的
IEEE FP32 1符号 + 8指数 + 23尾数,single precision
IEEE FP16 1符号 + 5指数 + 10尾数,half precision
Google BF16 ,1符号 + 8指数 + 7尾数,Brain Float,有时 FP32 -> FP16 训练不稳定,可以换成 BF 16
Nvidia FP8 (E4M3),1符号 + 4指数 + 3尾数,hopper
Nvidia FP8 (E5M2),1符号 + 5指数 + 2尾数
指数(数值范围、动态跨度大小),尾数(精度)
Nvidia INF4,1符号 + 3尾数,BlackWell
FP4 (E1M2), (E2M1), (E3M0)
E1M2 和 INT8一致,但是浪费应该 +- 0
Quantization 量化
把输入从连续集合转换成离散数值集合的过程,之间的差异,称为量化误差,目标是最小化差异
存储、计算:浮点数,浮点数
K-Means-based Quantization,code book
概念
存储、计算:整数,浮点数
节省空间;计算量不变
存储的是代码本(k-means的质心)和分类的下标
N-bit quantization 量化,#parameters = M » 2^N
32 bit x M = 32 M bit; N bit x M = NM bit + 32bit x 2^N = NM + 2^(N+5) bit
where 2^(N+5) bit can be ignored
量化后微调 fine-tune
得到梯度矩阵,把原本权重的分组,用在梯度矩阵上,求和,在权重的code book上去对应颜色的减掉 (乘学习率)
这个图有点神奇的,两个结合,但是得到了更好的结果:

先 剪枝 后 量化,降低量化工作量,降低量化误差
低精度计算单元
经验值,Conv,在4bits后,才下降明显;FC,在2bits后才下降明显;所以4bits保持不错
其他的编码方式
Huffman Coding 哈夫曼编码
不同的权重出现的频率不同,变长编码策略
出现多的,用短编码
three-stage pipeline Deep compression
深度压缩三阶段流水线
- 剪枝,减少权重数量
- 量化,用k-means聚类算法,权重分组
- 编码,huffman coding,出现频率
Linear Quantization
概念
存储、计算:整数,整数
节省空间;减少计算量
原始参数权重 =>
(量化后的参数权重 - zero point (int) )* scale(float)
r(fp) = (q(int) - z(int)) * s(fp)
q_min max 是确定的,
s = (r_max - r_min) / (q_max - q_min)
z = round(q_min - r_min / S)
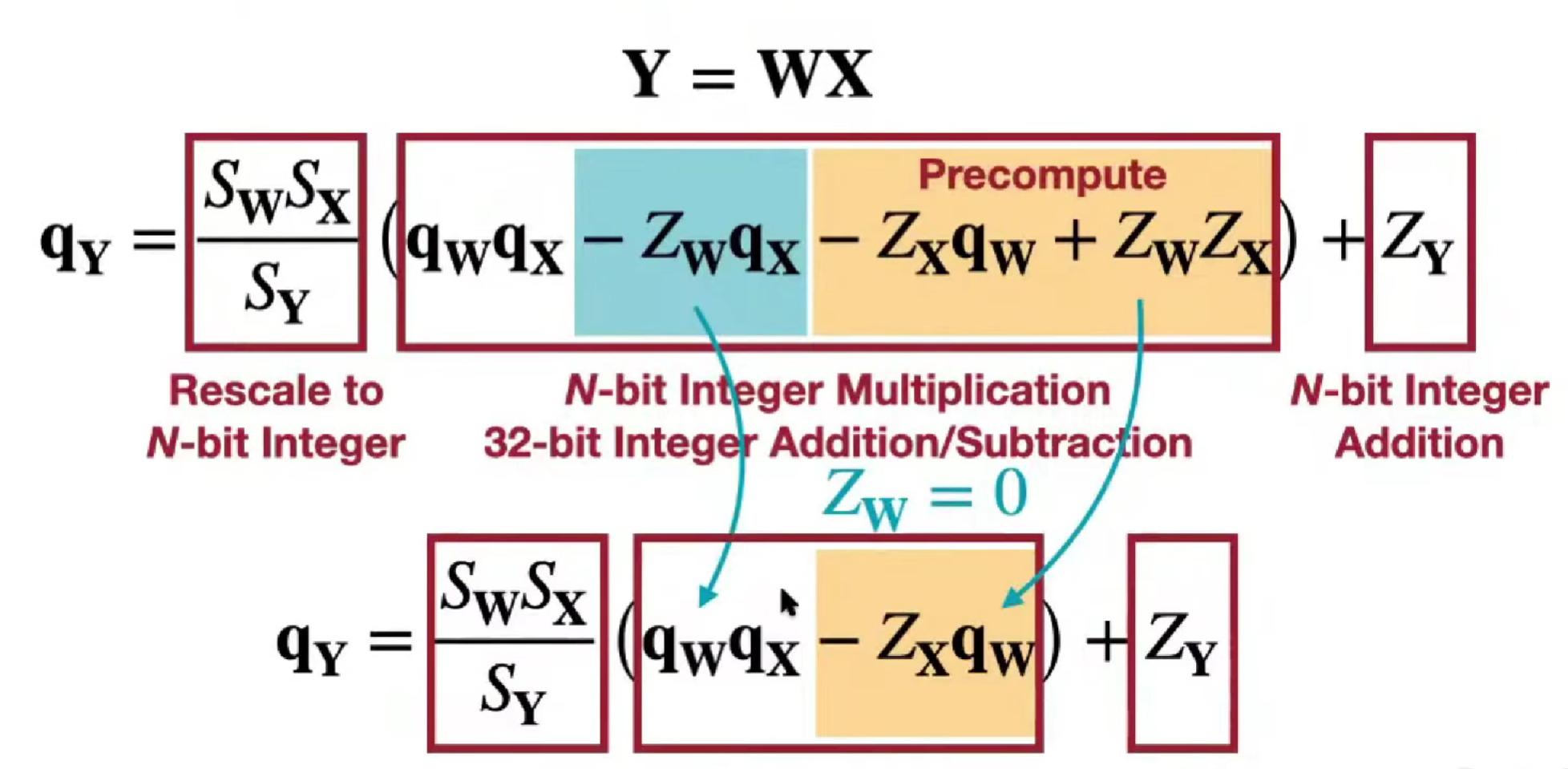
矩阵乘法运算
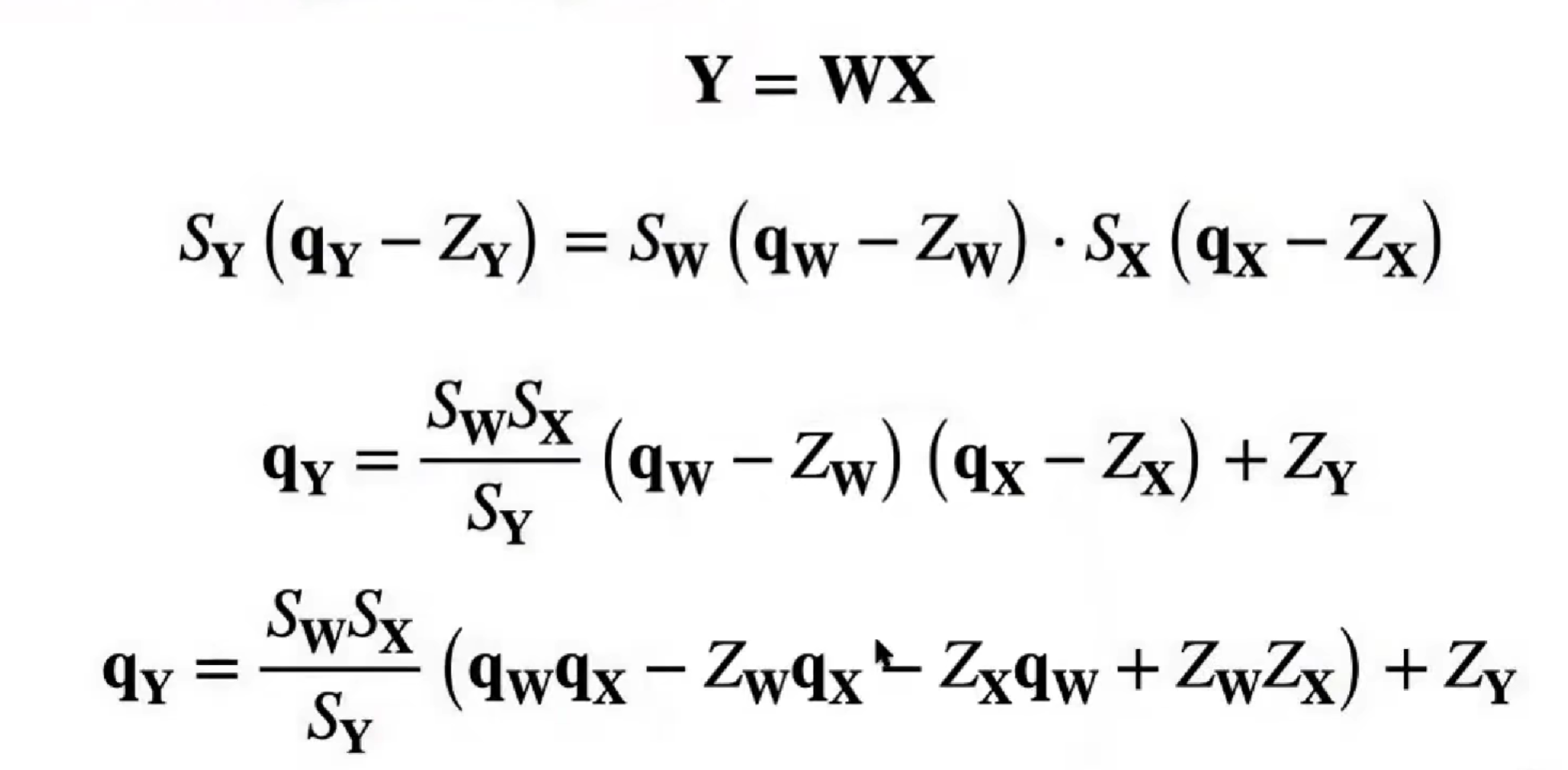
为了防止溢出,计算是需要类型转换
括号内后两项是常数(输入的零点,权重的量化值),包括括号外一项是常数,可以提前算
零点不变,量化权重不变
经验值,缩放因子在 (0, 1),权重w的分布,遵循正态分布,Z_w = 0,为什么(?)
当 Z = 0,S = r_min / (q_min - Z) = - |r|_max / 2^(N-1)
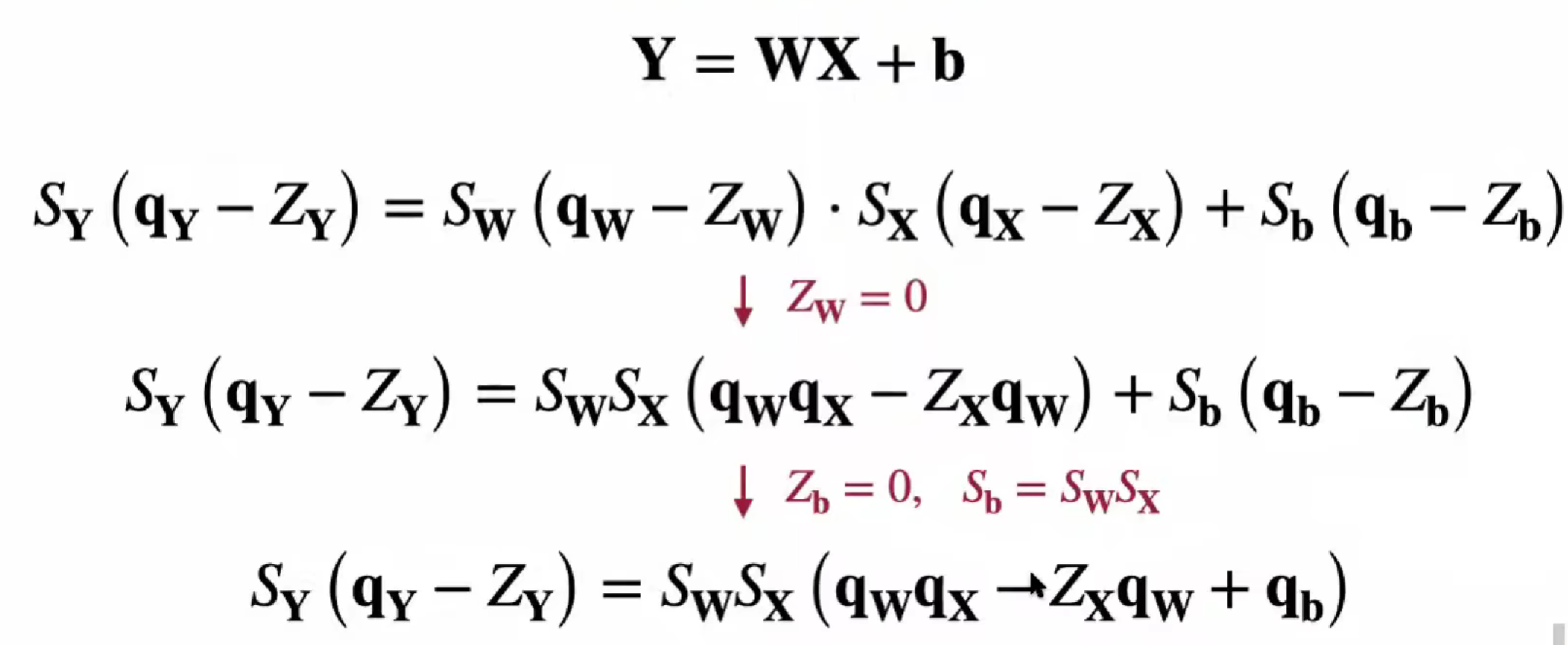

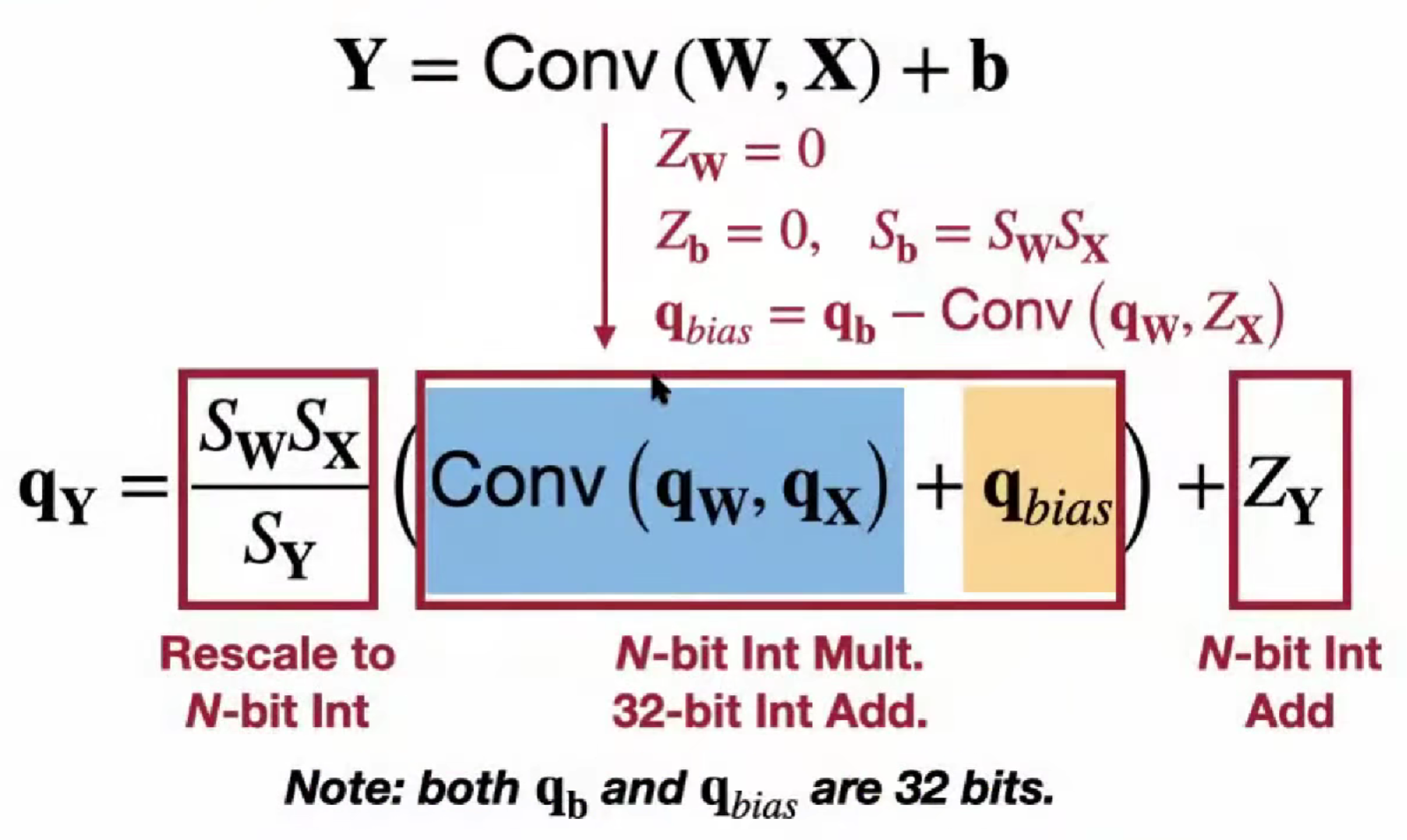
Lec06 量化提高结果
Post-Training Quantization (PTQ)
quantization granularity
Quantization-Aware Training (QAT)
更低的量化位数
- binary quantization
- ternary quantization
automatic mixed-precision quantization 混合精度量化
每一层不一定要一样的精度
Post-training Quantization
Quantization Granularity
Per-Tensor Quantization
对整个张量用一个缩放因子
大模型上效果好,小模型精度下降
原因:不同的channel的权重范围不一样
Per-Channel Quantization
更精细,误差更小,存储更多的值
Group Quantization,在4bit及以下,很重要
VS-Quant: Per-Vector Quantization
全局浮点缩放因子,局部整数缩放因子
Multi-level scaling scheme 多级缩放
Shared Micro-exponent(MX) data type
L0 和 datatype 是共享的

Dynamic Range Clipping 动态范围裁剪
收集激活值的统计信息,在部署模型之前
During Training 在训练的同时
Exponential Moving Averages (EMA)
维护 r_min, r_max,r(t) = alpha * r(t) + (1-alpha) * r(t-1),平滑维护动态范围
(必须参与在训练)
calibration batch 训练后
不过可以使用多训练一个batch,用calibration校准数据集,估算动态范围
可能不希望用真正的最大值
最小化 MSE 均方误差
假设是高斯分布或者拉普拉斯分布,最两端的地方数量其实少,有对应封闭解
但实际符合这样分布的输入数据很少
最小化损失的信息
使用 KL divergence散度来校准量化范围
Rounding 舍入
权重之间是相关的,舍入到最近的值不一定是最好的
Round-to-Nearest
AdaRound
引入可学习的 delta 然后再四舍五入
Quantization-Aware Training (QAT)
量化感知训练,fine-tuning 恢复精度
K-means-based 量化,fine-tuning,更新质心即可
线性量化?
Simulated quantization 模拟量化,fake quantization 伪量化
在训练的时候,维护一个全精度的参数权重,能累计非常小的梯度
再加上对激活值的量化的过程
增加这两个量化节点 Q(W), Q(Y)
训练好后,全精度参数权重就被抛弃
量化激活,阶跃的,梯度是0
Straight-Through Estimator (STE)
把weight-quantization node看成恒定函数 Y = X,传递梯度
Binary/Ternary Quantization
概念
Binary Weight Networks (BWN)
储存,计算:Binary/Ternary,Bit Operations
deterministic binarization 确定性二值化
stochastic binarization 随机性二值化
需要随机数生成硬件
精度下降大,量化误差大,再次引入缩放因子,1/n * |W|_1
啊?量化误差变化不大,精度能提升,从-21.2% 能到 0.2%?
激活值的二值化?
XNOR 同或,用他来代替乘法
默认值,0 是 -1,1 是 +2,起因也是有 XNOR 硬件计算快
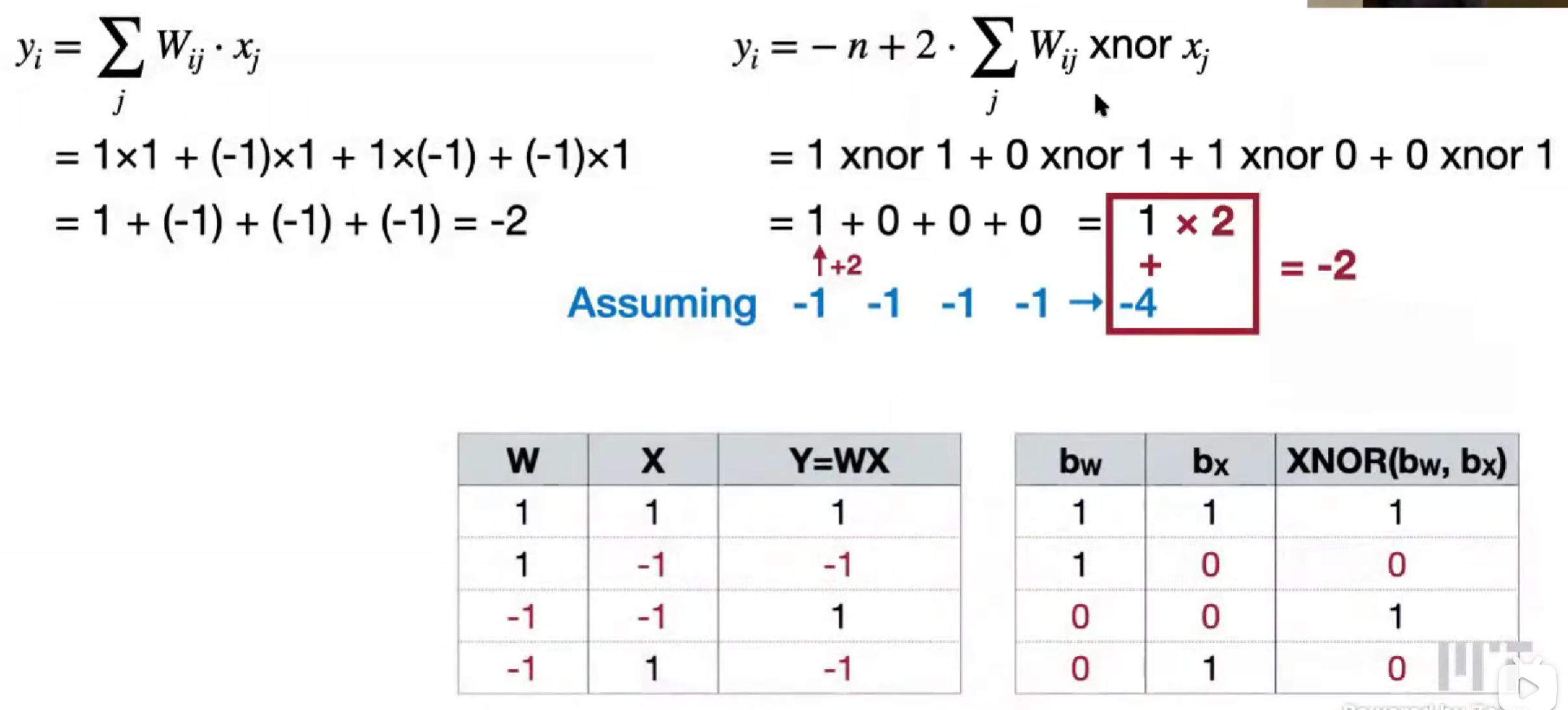
y = -n + popcount(W_i xnor x) « 1
Ternary Weight Networks (TWN)
和 delta 比较,得到 +1 -1 0,经验值,0.7 * E(W)
同样缩放系数
Trained Ternary Quantization (TTQ)
可以再引入,正缩放系数 Wp 与负缩放系数 Wn
降低精度的时候,内存是线性下降,计算量,模型表达能力,二次下降
Mixed-Precision Quantization
混合精度量化
设计的空间很大
Hardward-aware automated quantization with mixed precision (HAQ)
Lab2
K-means Quantization
QAT,简化,k-means直接用权重再更新
训练/微调的时候是伪量化,部署时才是真量化
Linear Quantization
Lec07 NAS 神经网络结构搜索
Neural Architecture Search (NAS)
不同于前面的训练、推理的优化,这是模型结构的优化
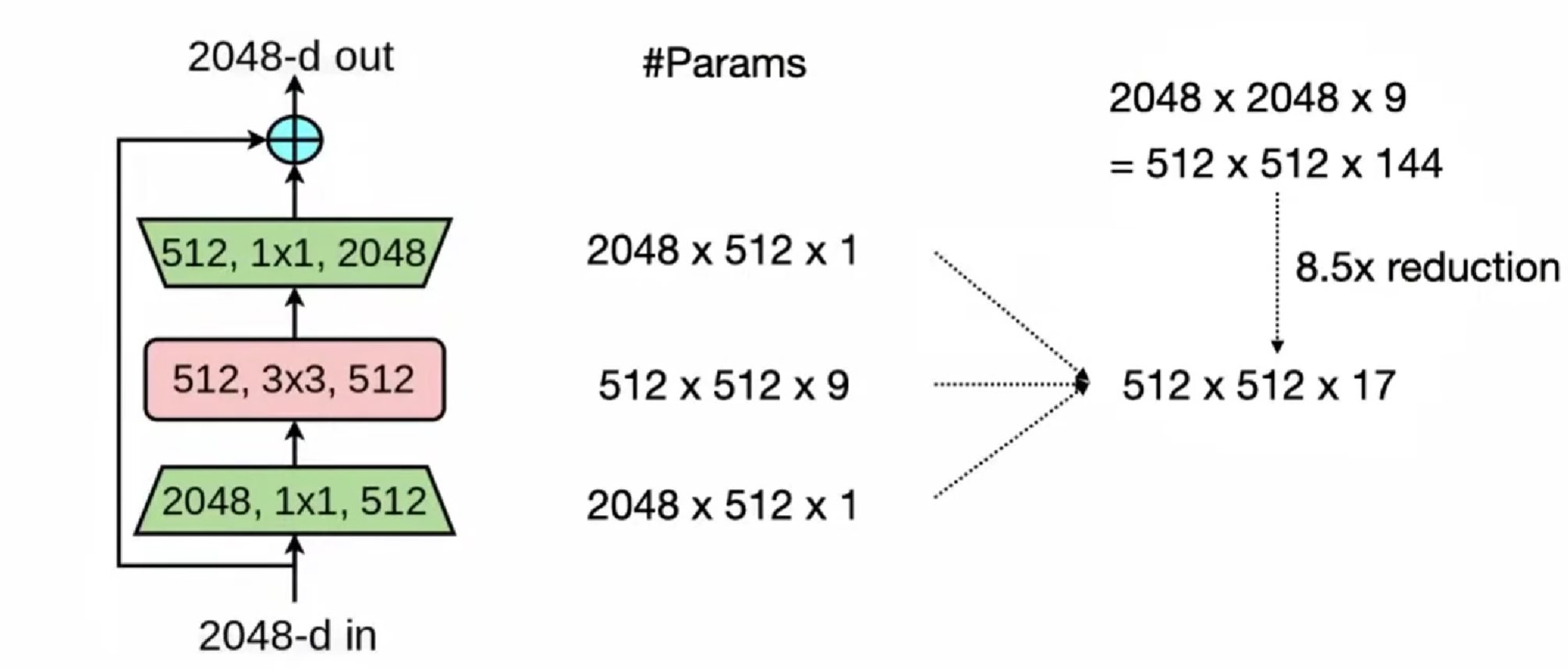
ResNet,1x1 卷积,bottleneck block
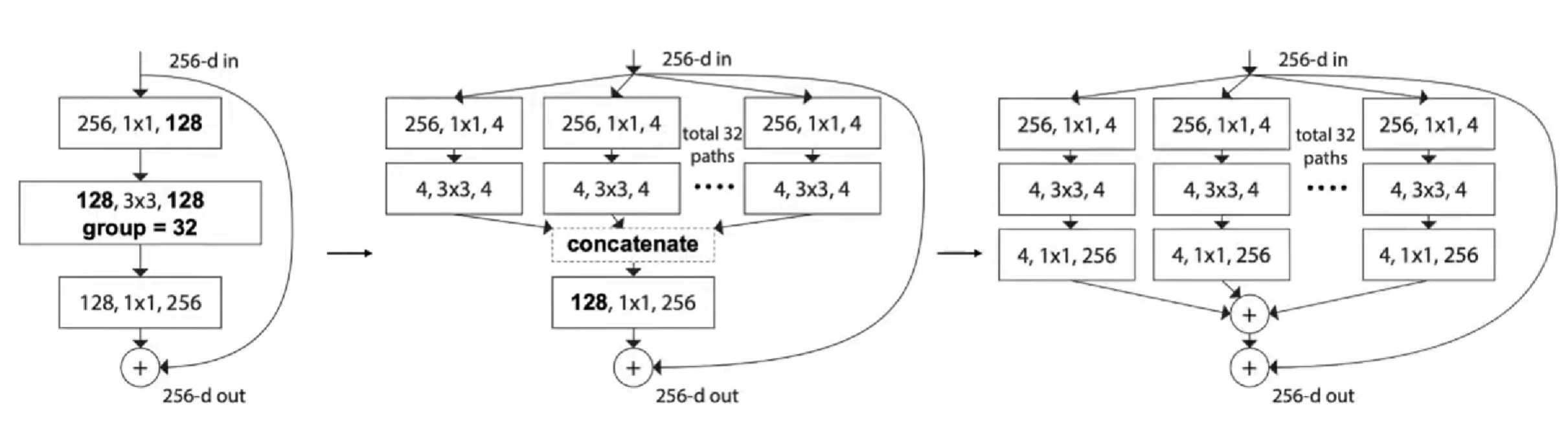
ResNeXt,1x1 分出来channel,分组卷积
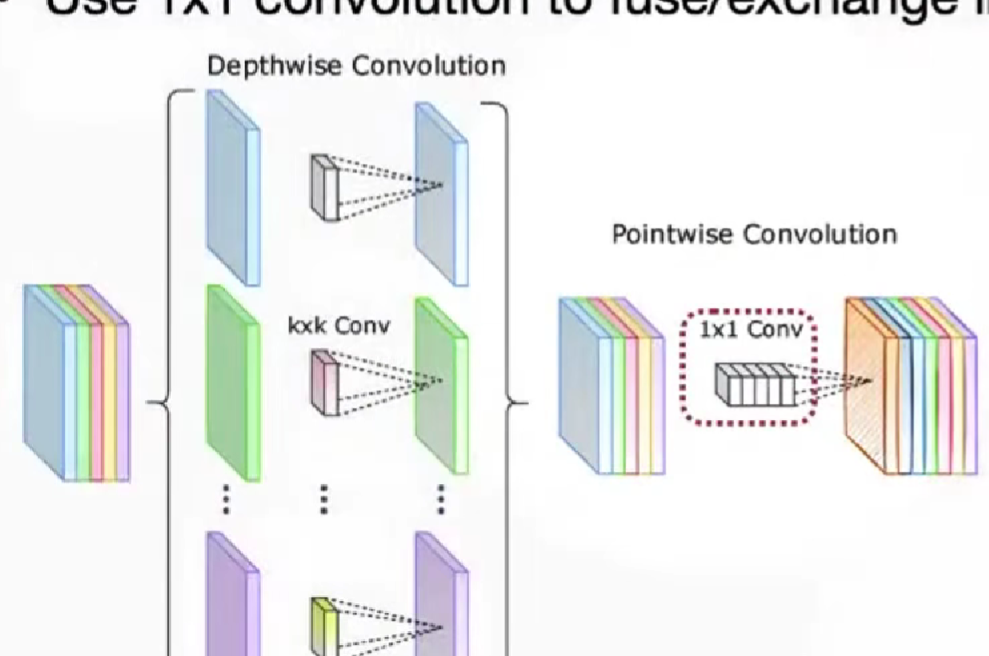
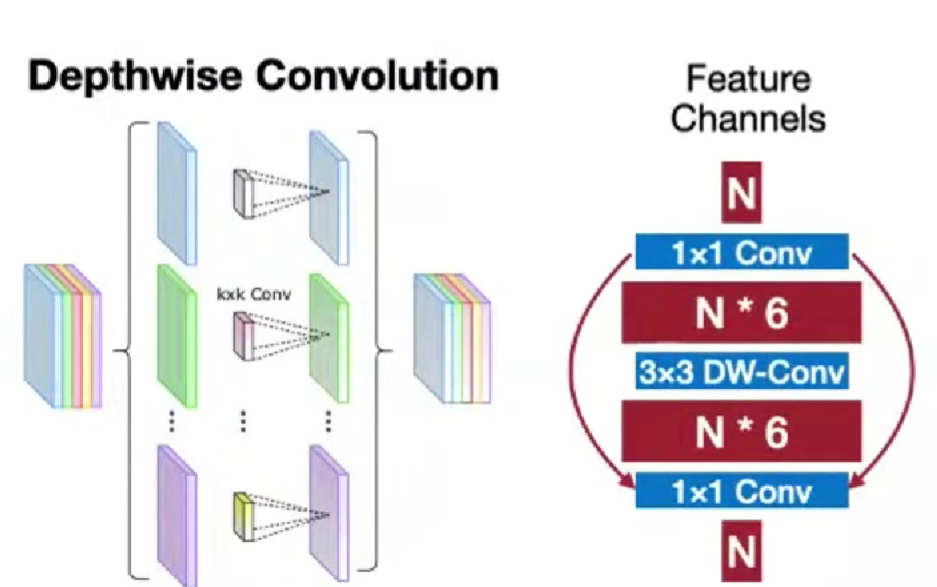
MobileNet: depthwise-separable block
空间信息depthwise和通道信息pointwise,分开区分
depthwise conv 表达能力弱
MobileNetV2: inverted bottleneck block
和bottleneck相反,中间增大
激活值的特性不好
可以用来减小模型大小和计算量,但激活内存不能(训练常常是激活内存为瓶颈)
ShuffleNet
混洗shuffle,促进不同通道的信息的流动
Transformer
Multi-Head Self-Attention (MHSA)
感受野一层就可以全了
Search Space
Cell-level search space
重复使用两种、
reduction cell 归约单元,降低分辨率
normal cell 普通单元
Network-level search space
- TinyML,内存更关键,在同样的内存限制下有更高FLOPs更好
搜索策略
Grid search 网格搜索
需要训练,根据各个指标剔除
compound scaling 复合缩放
Random search
同样的搜索空间,但是随机变化,快速评估
Reinforcement learning
决策序列
Gradient descent
指标考虑,计算选择概率
Evoluitionary search 进化算法
变异、交叉等
Performance Estimation Strategy
Train from scratch
成本高
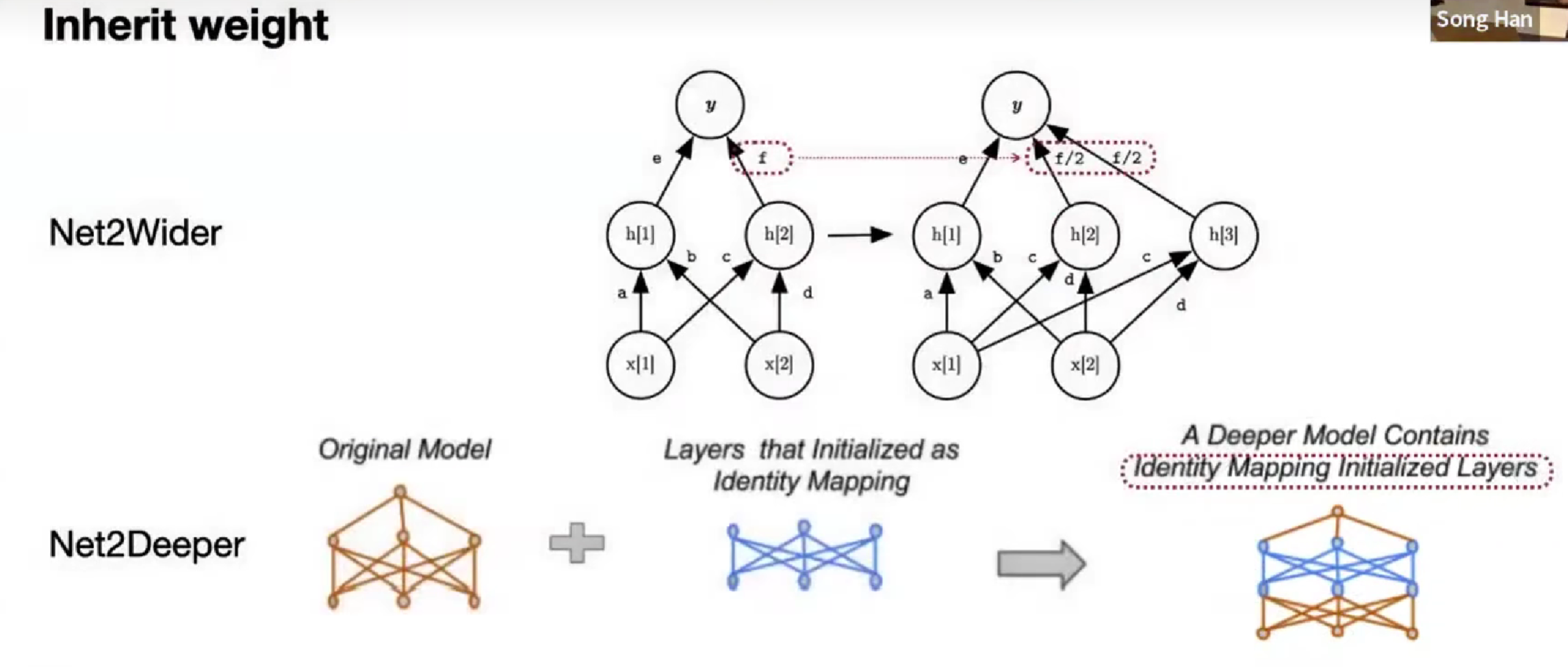
Inherit weight
从预训练的基础上,继承权重,拆分点,保持数学等价,改变深度、宽度
降低成本 net-to-net
Hypernetwork
用网络来预测网络参数,层作为node embedding
init embedding => final embedding 生成权重
用来降低训练成本
Lec08 NAS 更高效
定制模型
前面的 NAS 太贵,选择proxy task代理任务,如更小的数据集,更少的训练轮数,FLOPs,参数量等
但是proxy task的相关性可能也没这么好。
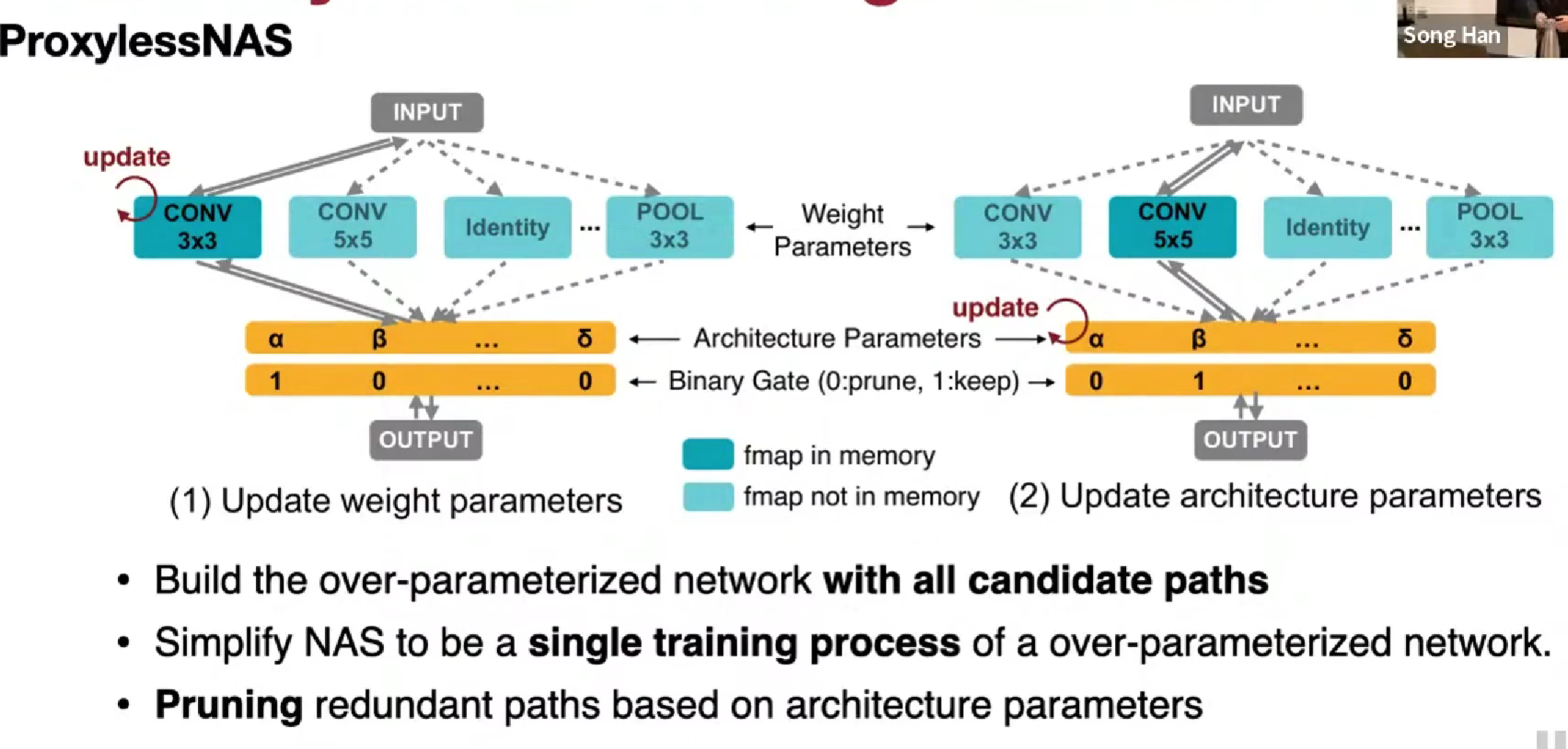
ProxylessNAS
路径级二值化,指走概率最高的路径
训练按概率,推理选概率最高
MACs 不等于真实硬件效率
需要用真实硬件,效率低?并行!太贵?用延迟预测模型『架构,延迟』,最简单的模型是查询表,算子和延迟(一层一层的测延迟,相加)
GPU会有 kernel fusion,两个kernel 可能会变成一个kernel 而变快
计算密集型的两个,通畅不能kernel fusion,如两个矩阵乘法
但矩阵乘法 + 非线性激活函数是可以的,计算密集型 + 内存密集型
GPU会在更浅、更宽的表现好,CPU在更深、更细的表现好(对自己设备来说)
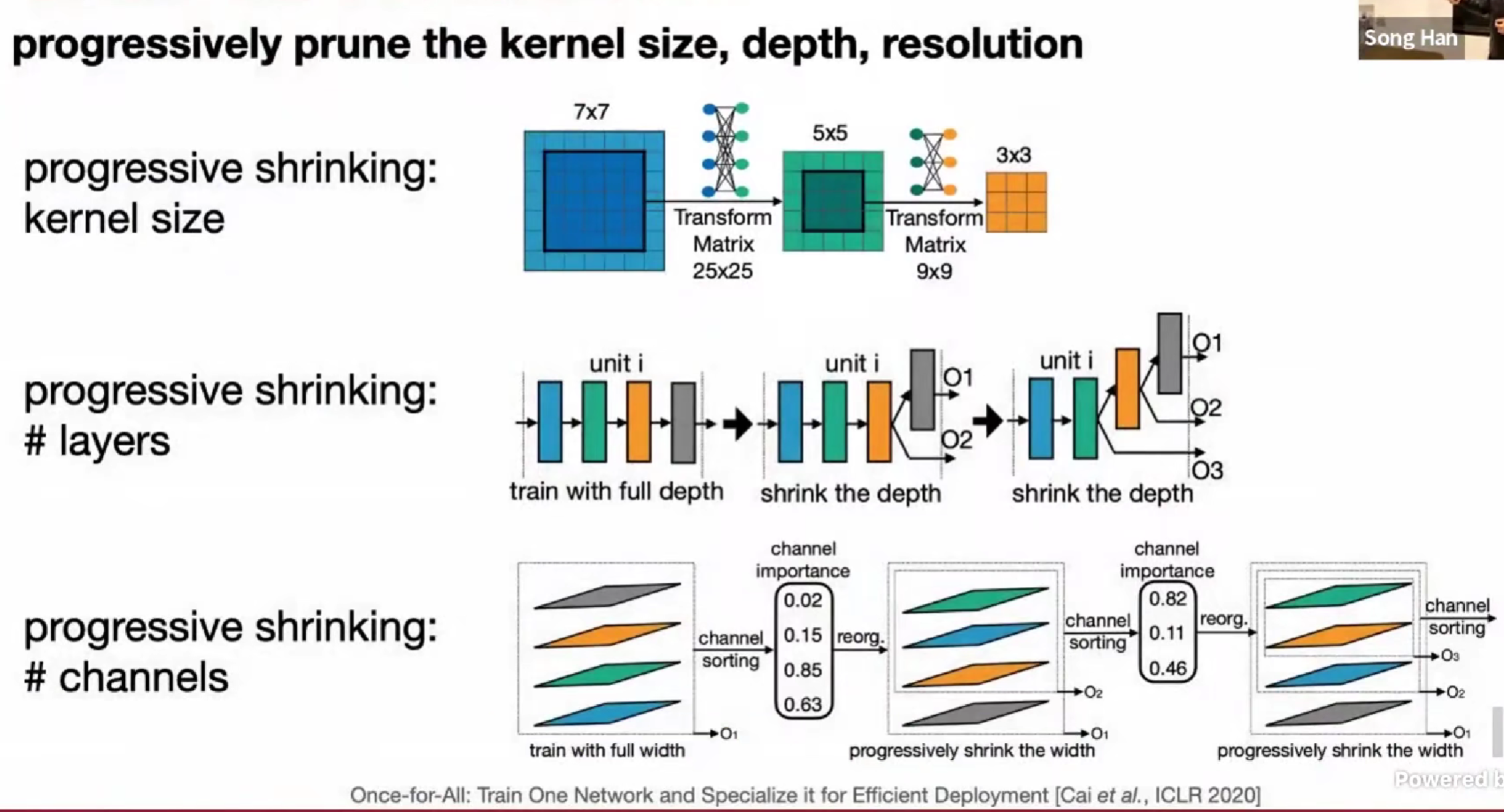
每个设备都要重新训练一个太贵,Once-For-All approach
同时训练多个模型?
用一个单一模型,包含许多子网络,稀疏激活
相比之前的重新训练,现在只需要在小型网络中抽取不同的subnetwork子网络就行了
设备不同,电量不同(适应不同能耗)等
共享参数,不同子网络之间相互干扰?elastic 弹性的
- 卷积核大小,不采用单独不同的卷积核大小,而是选择用变换矩阵处理,只用一个 7x7 的参数就好,小的参数都在7x7的内部
- 深度,shrink the depth 归约深度
- 通道,通过不同channel的magnitude幅值,对重要性进行排序,选择前 i 个通道
Roofline Analysis 屋顶线分析
折线图,X-获得一个字节的操作数,Y-GFLOPS 浮点算力
computation is cheap; memory is expensive.
内存瓶颈,计算瓶颈。
Zero-shot NAS
原本需要需要训练才知道评估acc准确率,变成只要看它的结构,推测是否能拿到高的准确率
ZenNAS, GradSign(感觉很直觉地开始套娃)
ZenNAS 启发式
random weights 随机权重,粗略估计,结果不错
随机初始化输入,符合正态分布
加入小的扰动
再把所有的权重,映射到正态分布
论文指出,z = log(f(x’) - f(x)),如果模型效果好,应该对模型输入感到敏感,也就是说两个输出的差值应该大
+ batch normalization variance 批归一化(另一种启发式)
对于不同的批次,方差大好
计算每层的方差均值,加起来,希望这个方差越大越好
这样,不同的输出,容易得到不同的结果
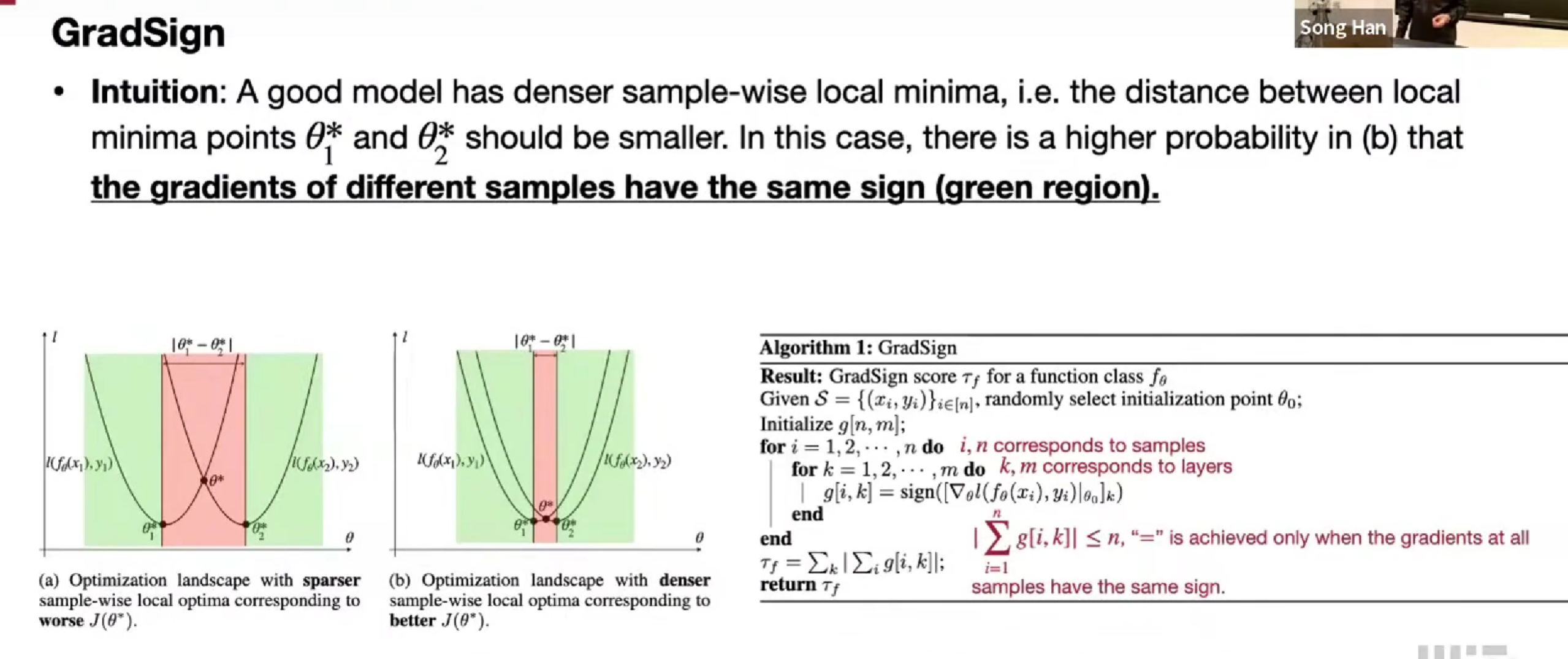
GradSign
好的模型会非常密集的sample-wise样本级局部最小值,两个局部最小值应该非常接近
在图中,绿色是梯度符号相同的部分,好的模型绿色部分应该更大,红色部分小
在初始点附近,随机选择些点,计数梯度符号相同的数量。
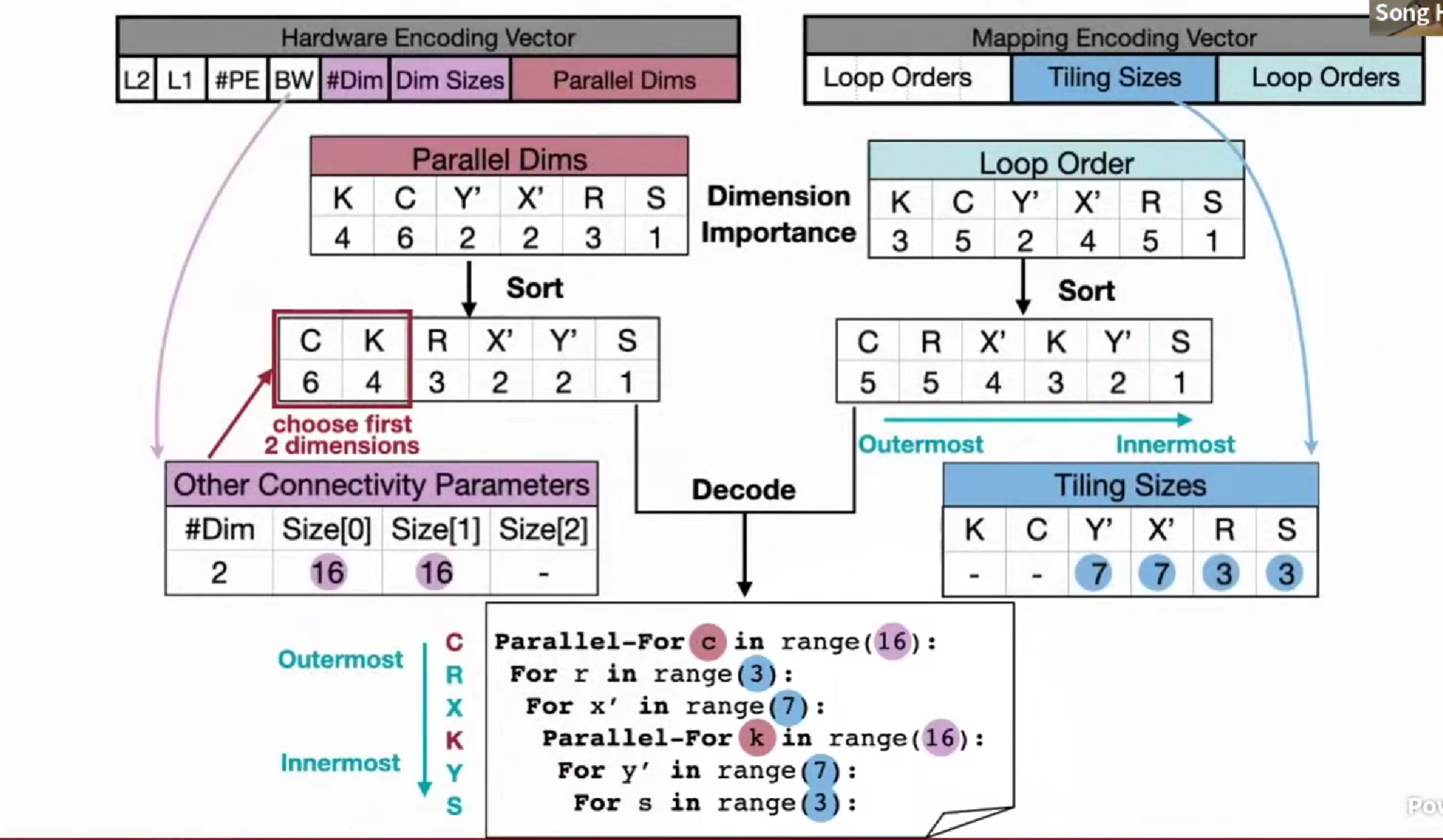
Neural-hardware achitecture co-search,设计硬件
不仅搜索神经网络架构,也搜索加速器架构
硬件结构上会有些「非数值参数」需要设计,如连接性
temporal mapping 时间映射
顺序处理
spatial parallelism 空间映射
空间并行处理
两种 embedding,选择并行维度与顺序维度,分别按照重要性排序
应用
Once-for-ALL for Transformer and NLP
- HAT
3D建模
GAN
小模型预览结果,大模型输出结果
Pose estimation
Quantum AI 量子
搜索最佳电路门
Lec09 知识蒸馏 KD
Temperature 温度,高的温度,不同的区别越小,smooth,T在softmax的x => x / T
匹配/对齐什么?
对齐中间权重 matching intermediate weights
难点,维度不一样低秩近似/全连接/
中间特征 intermediate future / activation matching
激活值,中间的结果,也是相似的
梯度 Gradients
计算权重梯度或计算激活值梯度匹配
表现好的模型的注意力图是相似的
稀疏模式 sparsity patterns
来源于激活函数 ReLU 例如。
Relational information
- 不同的层之间 C_in x C_out
- 不同样本之间,同一个模型,不同样本输入的不同输出之间的关系
online distillation 在线蒸馏
self-distillation
教师模型和学生模型架构一致
教师模型正常训练,学生模型用教师模型的交叉熵概率来训。
用前一步的作为教师模型,后一个以前一个为结果,
最后把所有模型ensemble,得一个更好的结果
Deep Mutual Learning 互学习 DML
两个不一定相同的模型架构,互为师生,N1训练时,N2指导,反之亦然。
真实标签的交叉熵误差 + KL散度 两者结果
不需要预先训练,教师模型不一定要比学生模型大。
Combined 前面两种方法结合 Be Your Own Teacher: deep supervision + distillation
用深层网络输出,作为浅层网络的教师,来自统一模型的不同部分。
蒸馏损失,在对真实标签的结果上,教师模型比学生模型的效果好时才能作为教师
物体识别,也可以看成(区域)分类
增强小模型的效果
容易过拟合,做数据增强 cut out, mixup, dropout
容易欠拟合,做网络增强,NetAug,基础模型扩展
Lec10 MCUnet TinyML
瓶颈
参数数量,峰值激活,与,内存
TinyNAS
Resolution 分辨率 和 Width Multipler 宽度调节因子
Automated search space optimization 自动搜索空间优化
分析满足限制的模型的FLOPs分布,在各自的搜索空间中,高FLOPs=>高模型能力=>更可能高ACC
在同样的内存限制下,能有更高的运算量的设计空间更好
Flash 存储权重,SRAM 存储激活值
(最好的配比)
Flash↑,宽度调节因子(通道数)↑,分辨率↓,否则在 SRAM 中存不下 分辨率 x 通道数
SRAM↑,宽度调节因子基本不变,分辨率↑
Resource-constrained model specialization 资源有限的模型特化
层的内存的峰值最小
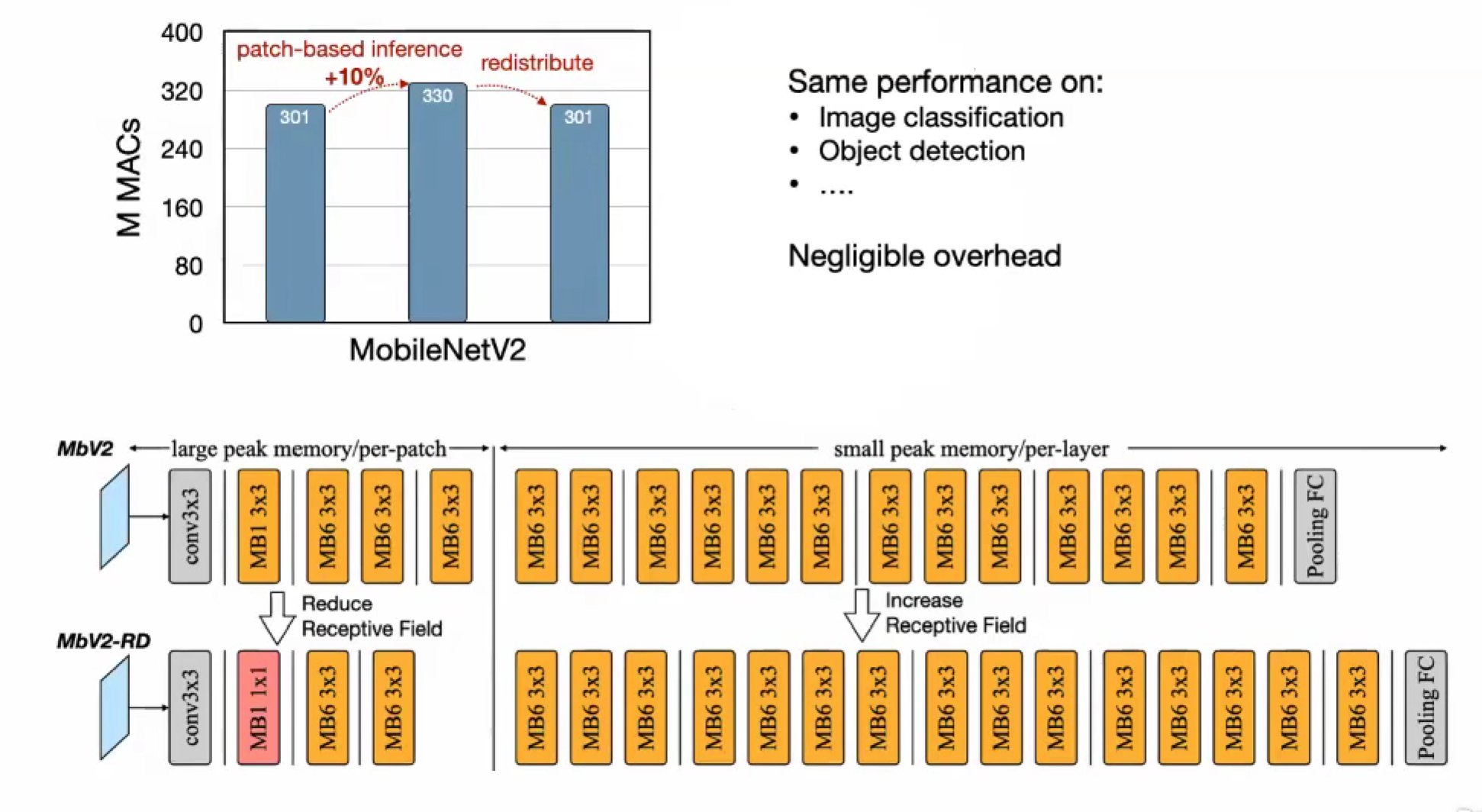
Patch-based Inference 分块
不再是 per-layer 整层输入输出,改为 per-patch,分成几部分输入输出
坏处,增加了latency延迟,限制了并行能力(不过微控制器的并行能力是弱的)
卷积的重复计算,感受野,多了重叠的部分。感受野扩展
可以调整(减小早期的感受野,1x1,减少分块阶段的卷积层),总的需要不一样,在后面增加回卷积层,消除影响
早期用 分块推理,后期降下来,是正常推理
再把这种分块推理的方式,放入搜索空间,推理调度
可以支持更大的输入分辨率
应用
Tiny Vision
classification, visual wake words,检测任务 分辨率敏感(相比分类),所以分块推理,能使得分辨率提高
on-device training
Tiny Audio
二维语音,(时间,频率)功率,conv,相邻的频率、时间关联
Tiny time series/anomaly detection 微型时间序列异常检测
异常事件、产品(autoencoder,符合正常分布,重建误差小,不符合,误差大)
VLA,多个任务
Lec11 TinyEngine
Loop optimization 循环优化
Loop reordering 循环重排
让访问内存更符合 cache line,连续访问
矩阵乘法 i, j, k => i, k, j,虽然输出访问变得不连续,但是还是会被cover掉
Loop tiling 循环分块
内存访问就 N*N => N*Tiling_size => Tiling_size * Tiling_size
内存局部性,降低缓存未命中
一般循环内层往外吧(?)
for ti, N block
for ti, ti + block
两层缓存?
设置第二层分块大小,多层次的分块 Tile2,和L2 cache 大小设计
Loop unrolling 循环展开
分支预测,for 条件判定,循环展开,减少分支;但会增加重复代码,增加二进制文件大小
SIMD (single instruction, multiple data) programming 单指令多数据
ISA (Instruction set architecture) 指令集架构
CISC (Complex Instruction Set Computer) 复杂指令集计算机
Intel x86
并行处理范式
Vector Register,向量寄存器
Vector Operation,向量运算
提高吞吐量,速度
RISC (Reduced Instruction Set Computer) 精简指令计算机
Arm, RISC-V

Multithreading 多线程
| |
OpenMP
编译器指令
| |
CUDA
MMA 矩阵累加
Inference Optimization
Image to Column (Im2col) convolution
In-place depth-wise convolution
NHWC for point-wise convolution, NCHW for depth-wise convolution
Winograd convolution

Lec12 Transfomer & LLM
Transformer 基础
…
Transfomer Design Variants 变体
Encoder-Decoder (T5)
Encoder-only (BERT, Bidirectional Encoder Representations from Transformers)
- Masked Language Model (MLM)
- Next Sentence Prediction (NSP)
Decoder-only (GPT, Generative Pre-trained Transformer)
- Next word prediction
Absolute/Relative Positional Encoding
绝对位置编码
嵌入输入中
贯穿整个Transfomer过程
相对位置编码
只在注意力机制的部分
能处理更长的上下文,train short, test long
ALiBi (Attention with Linear Biases)

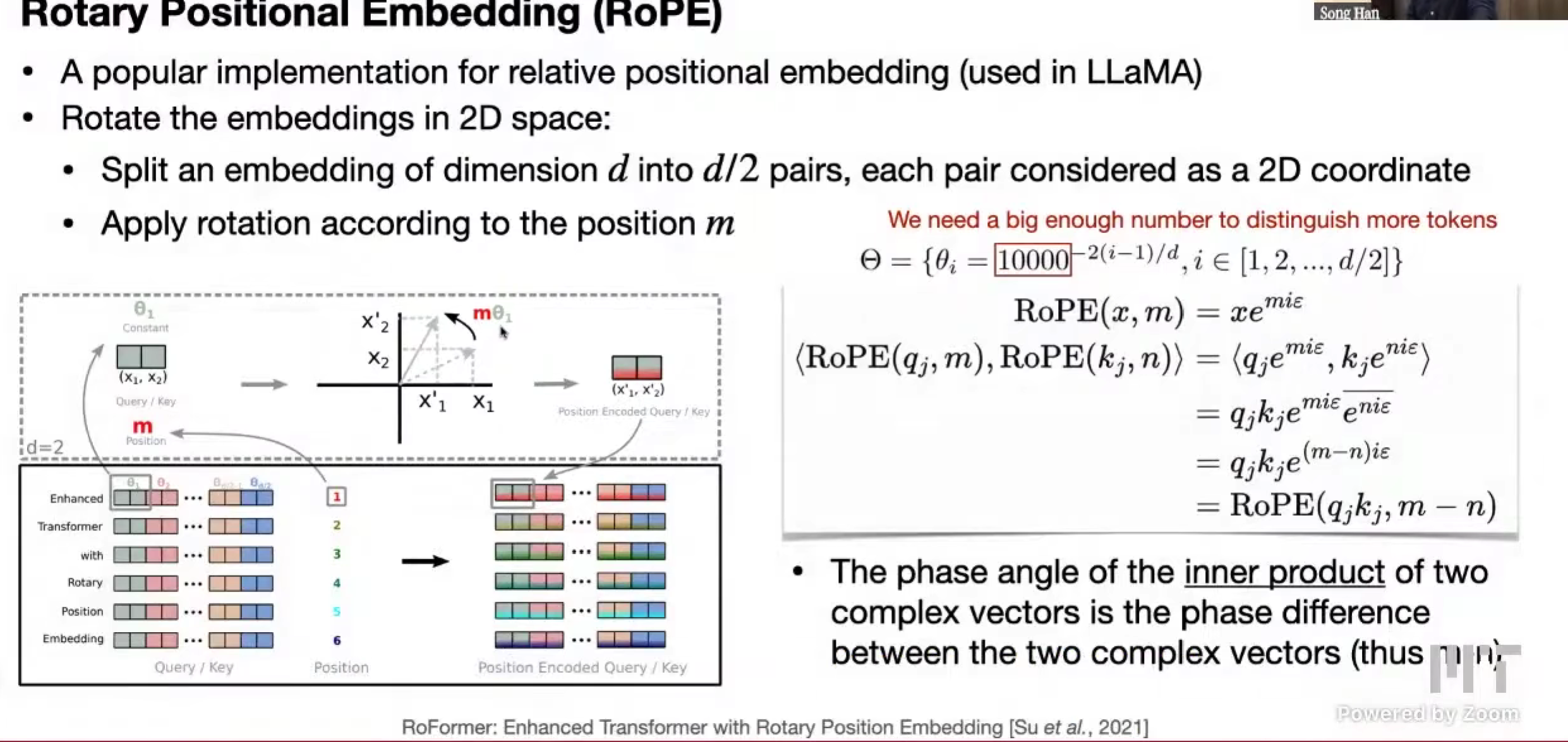
RoPE (Rotary Positional Embedding)
LLaMa
把长的嵌入转为二维的形式,(d1, d2)
interpolating 插值,当 m 翻倍,为了保持还能正常表示,theta / 2
KV cache optimization
需要 KV,才能在 Q 的时候,算出对应的 注意力
新token进来,没有 KV cache,则需要重算 KV???
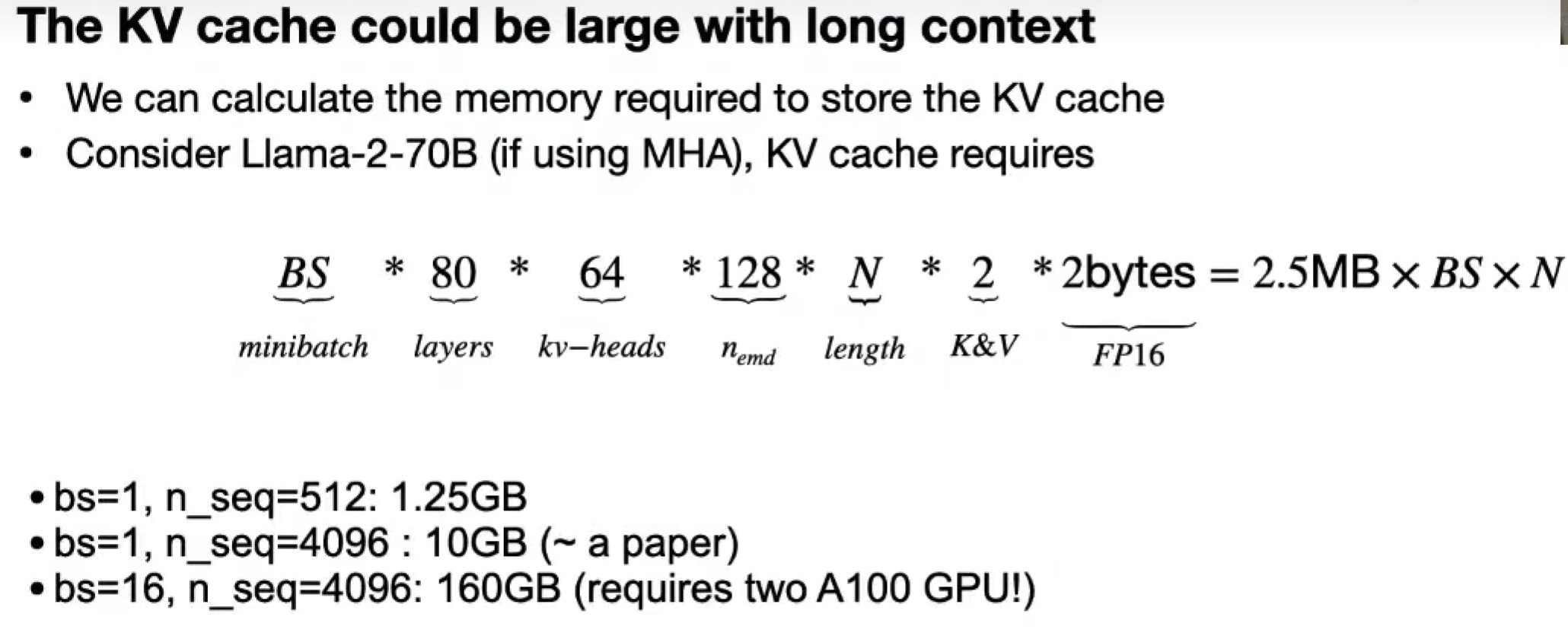
Multi-Head Attention (MHA)
n heads for query, n heads for key/value
KV cache 大小会乘以 n_kv,太大
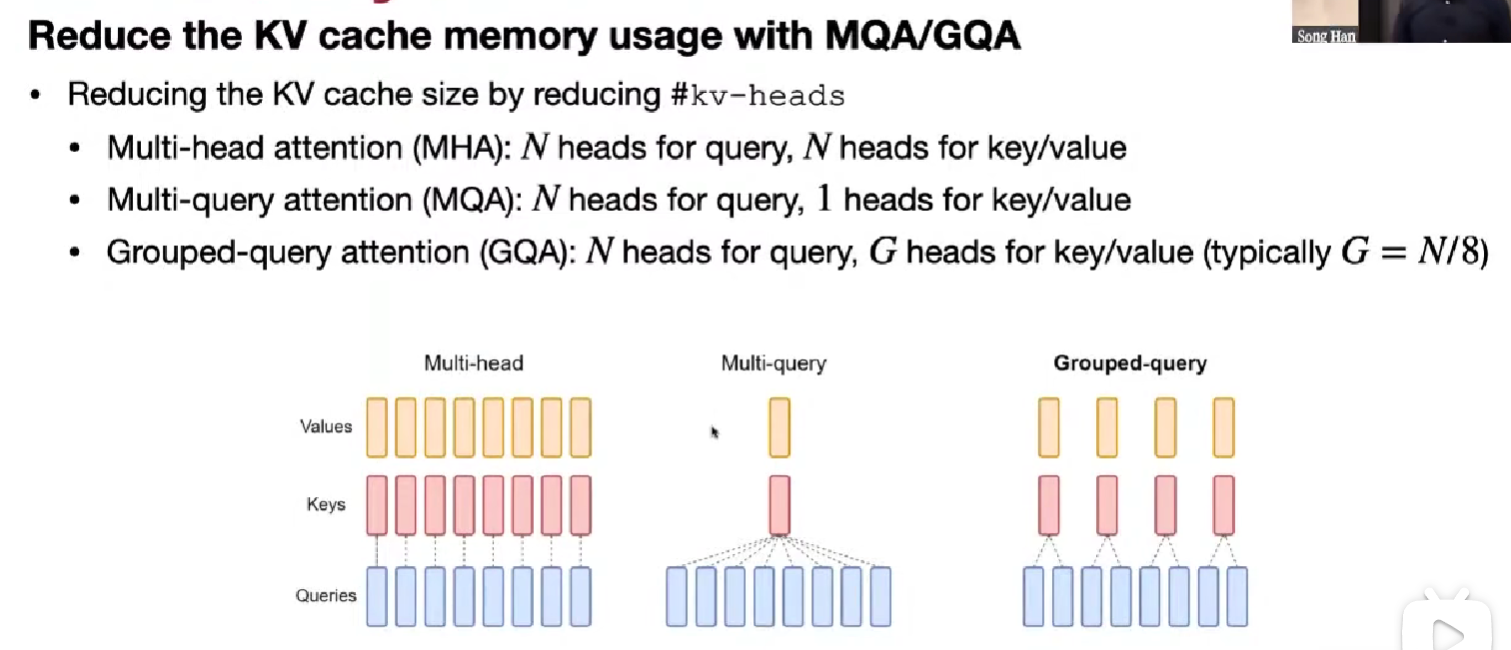
Multi-Query Attention (MQA)
n heads for query, 1 head for key/value
会大大削弱模型能力
Grouped-Query Attention (GQA)
折中
n heads for query, G heads for key/value (typically G = N/8)
在大模型下,准确率和 MHA 差不多
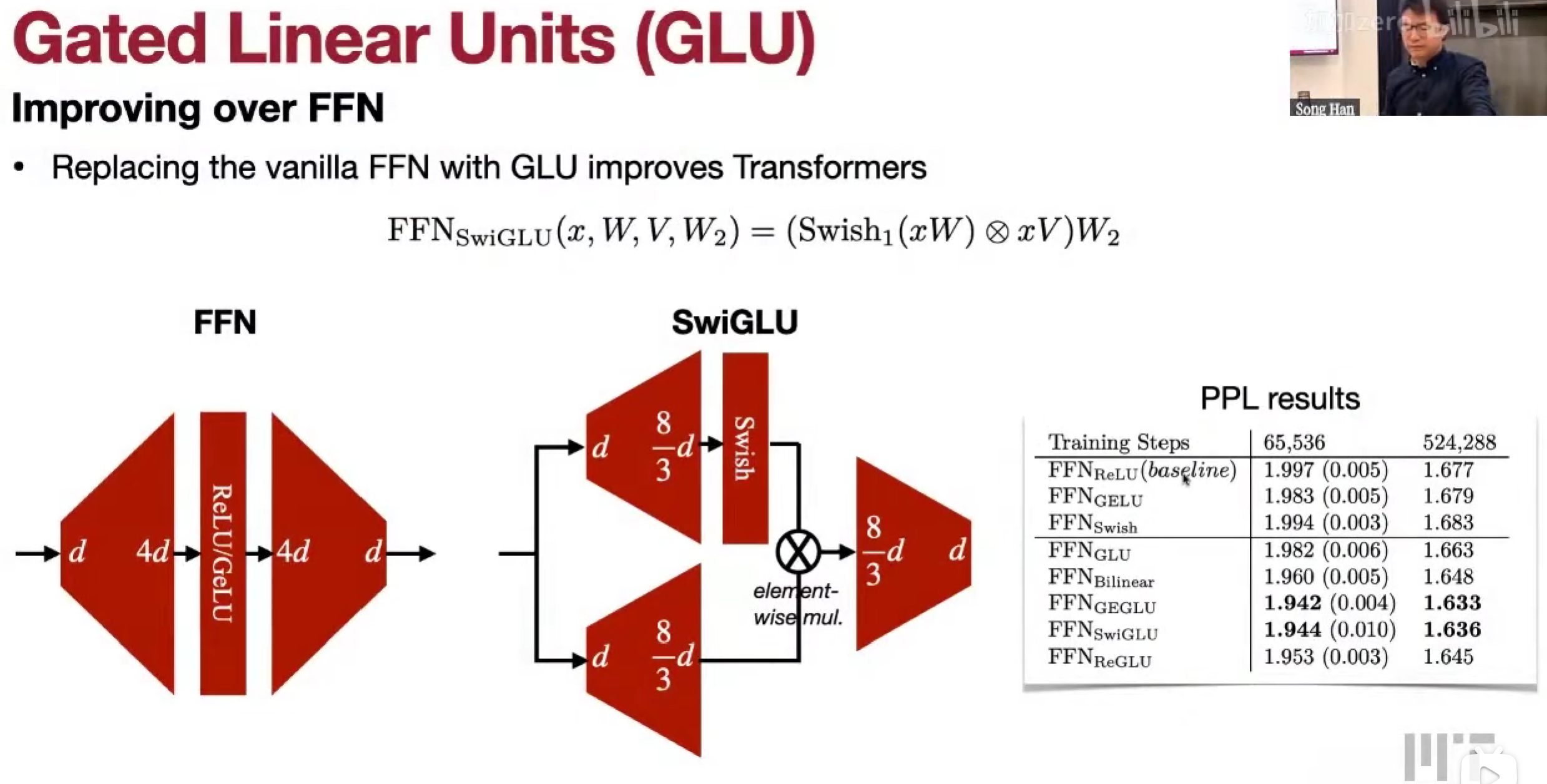
FFN => SwiGLU (Gated Linear Units)
LLM
LLaMa
LLaMa
Decoder-only, Pre-norm,SwiGLU(swish,gatedlinearunits), rotary positional embedding (RoPE)
7B model_d 4096, 32 heads
65B model_d 8192, 64 heads
LLaMa 2
上下文更长 2k => 4k
GQA 分组询问注意力
LLaMa 3
多语言 token
Mistral-7B
滑动窗口注意力机制,扩展上下文
数据和模型参数一起变大。
Lec13 LLM Deployment Techniques

Quantization
Weight-Activation Quantization: SmoothQuant
前面提到的哪些朴素的量化方法对LLM,其实效果不好
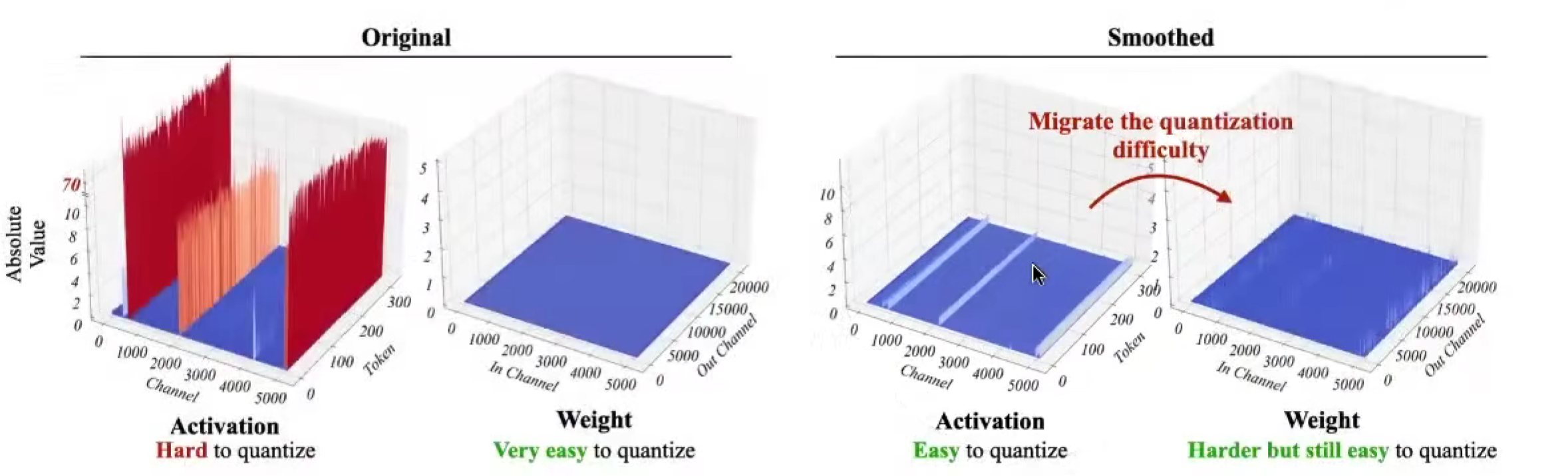
原因:outliers 异常值,某些激活值很大,破坏精度
激活值,个别异常高的channel,蓝色部分将被舍入零;
权重值,一般都比较小,ez。
取舍,smooth bond:
考虑到权重和激活值是线性矩阵运算,所以,比如激活值乘 0.1,权重乘 10,结果不变。
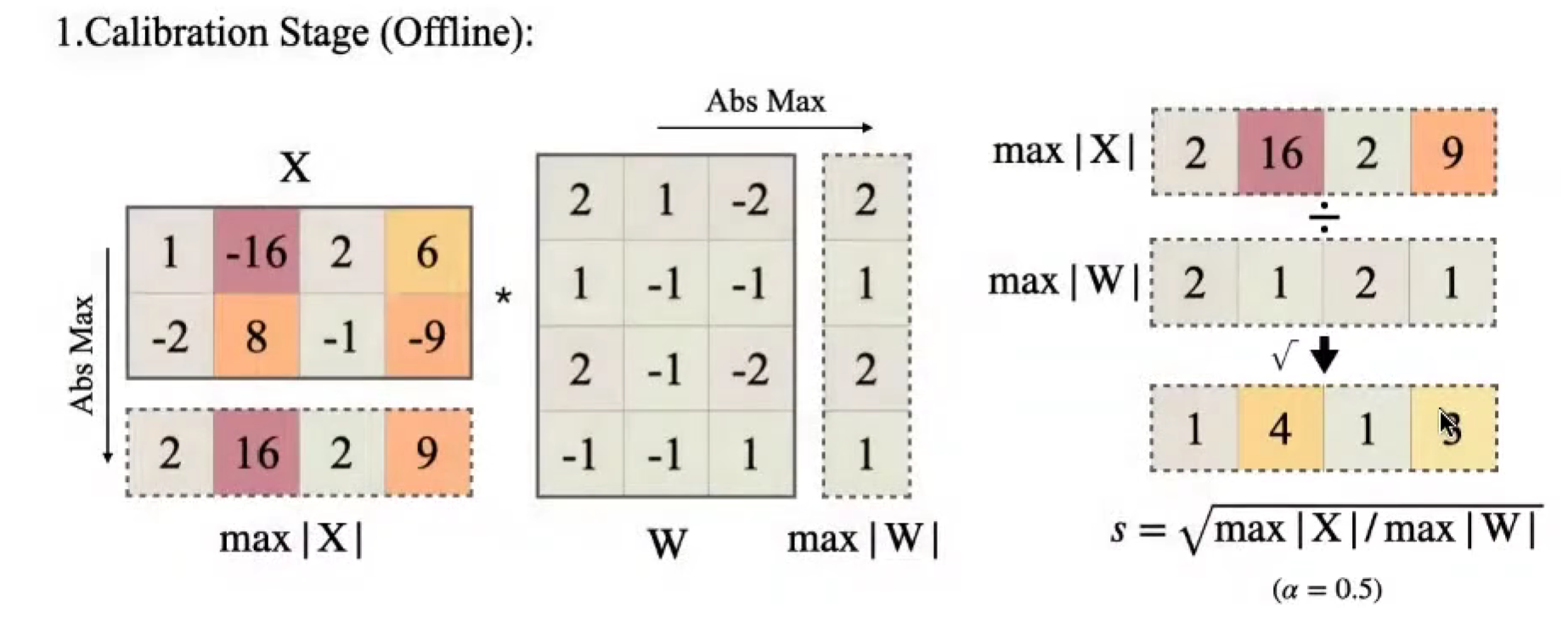
Calibration Stage
找到激活值 col_max,找到权重 row_max,相除得到缩放因子 s = \sqrt(col_max / row_max)
Smoothing Stage
应用缩放因子
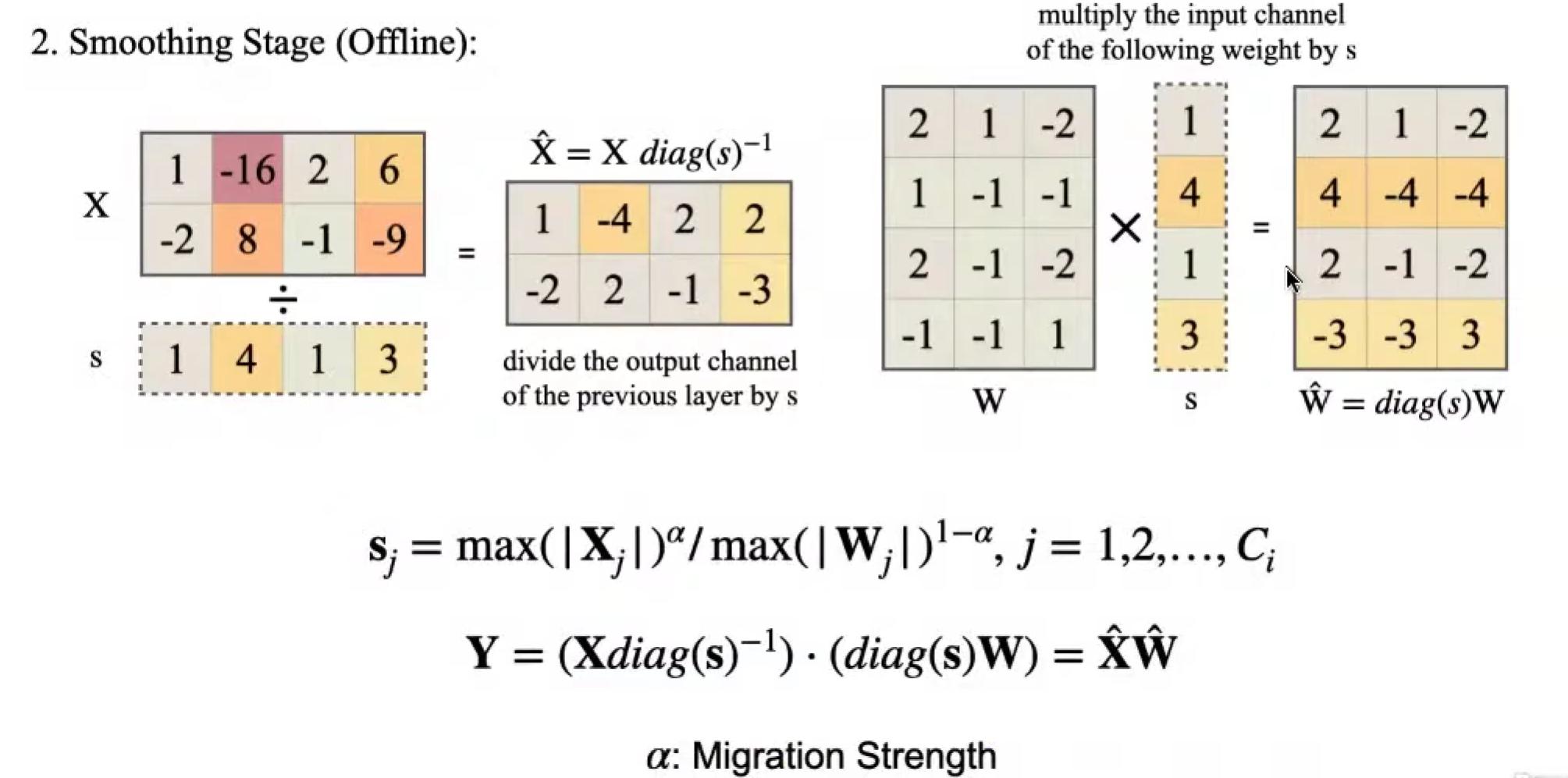
Inference (deployed model) 部署
没有再缩放,编译的时候处理了(fuse 到前一层)
为什么单节点比分布式好,communication overhead
Weight-Only Quantization: AWQ and TinyChat
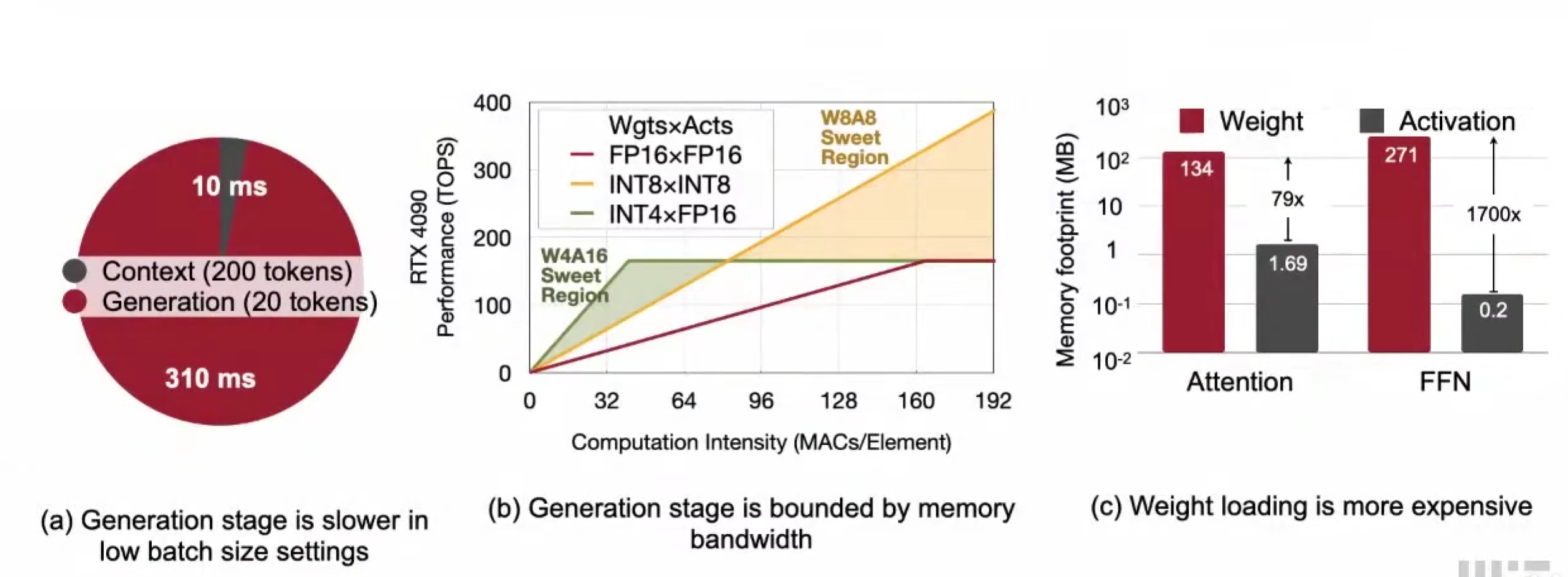
W4A16 for Single-batch single user server
单用户,就是 batchsize 是 1,计算瓶颈是 weight
weight在边缘设备的LLM推理中的影响
- 上下文与生成阶段,生成阶段是瓶颈
- 生成阶段受限于内存通讯
- weight的占用内存的大小,比activation大多了
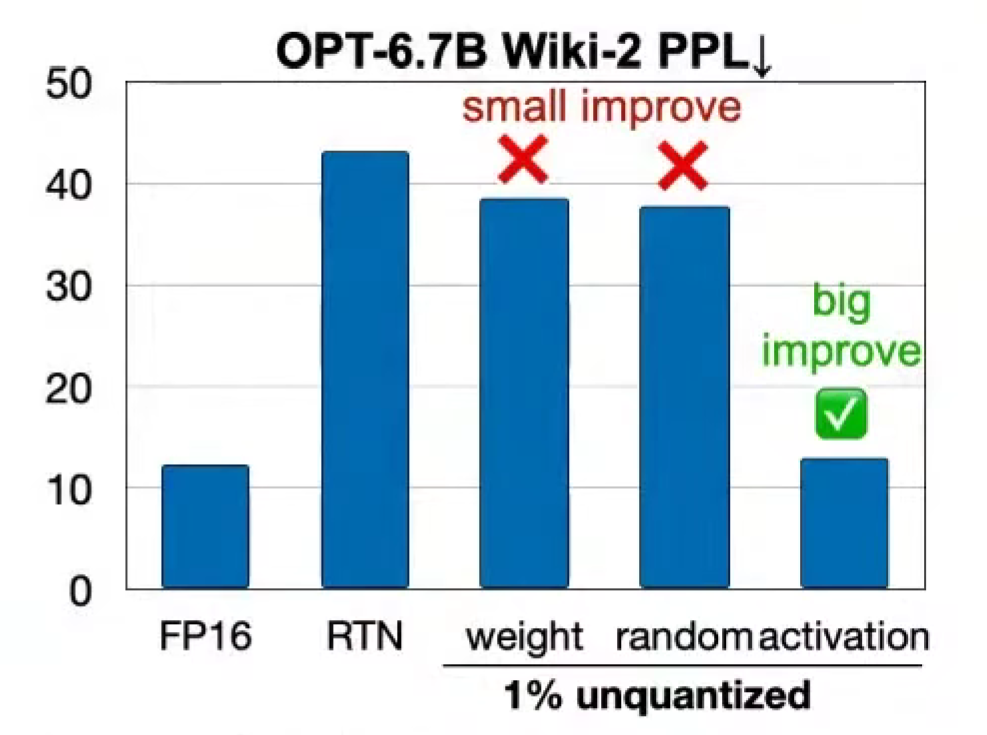
AWQ: Activation-aware Weight Quantization
传统 RTN(Round To Nearest)FP16 => INT3,clip(),降低很多。
???
只要保留一行,即1%channel,的关键权重,幻觉显著下降!
怎么找出这 1% 呢?
在量化权重的过程中,不关注权重的情况,而是关注激活值的情况!
因为下一层的激活值,是由权重与上一层的激活值相乘得出,所以,激活值大的,保留,
也是前面说的少量的异常值outlier
但是同个张量中出现fp16 和 int8,很难实现,会引入混合精度的计算,变得麻烦。
其实是不必要引入的,借用前面SmoothQuant中用到的方法,把权重的敏感性转给我们保持不变的激活值
相当于增加一位的精度
不需要反向传播,不需要基于回归的方法,只需要 calibration 校准数据集。
(Perplexity 困惑度 是衡量语言模型质量的一个指标,和真是输出的比较,越小越好)
TinyChat: LLM Inference Engine on Edge
Hardware-aware packing
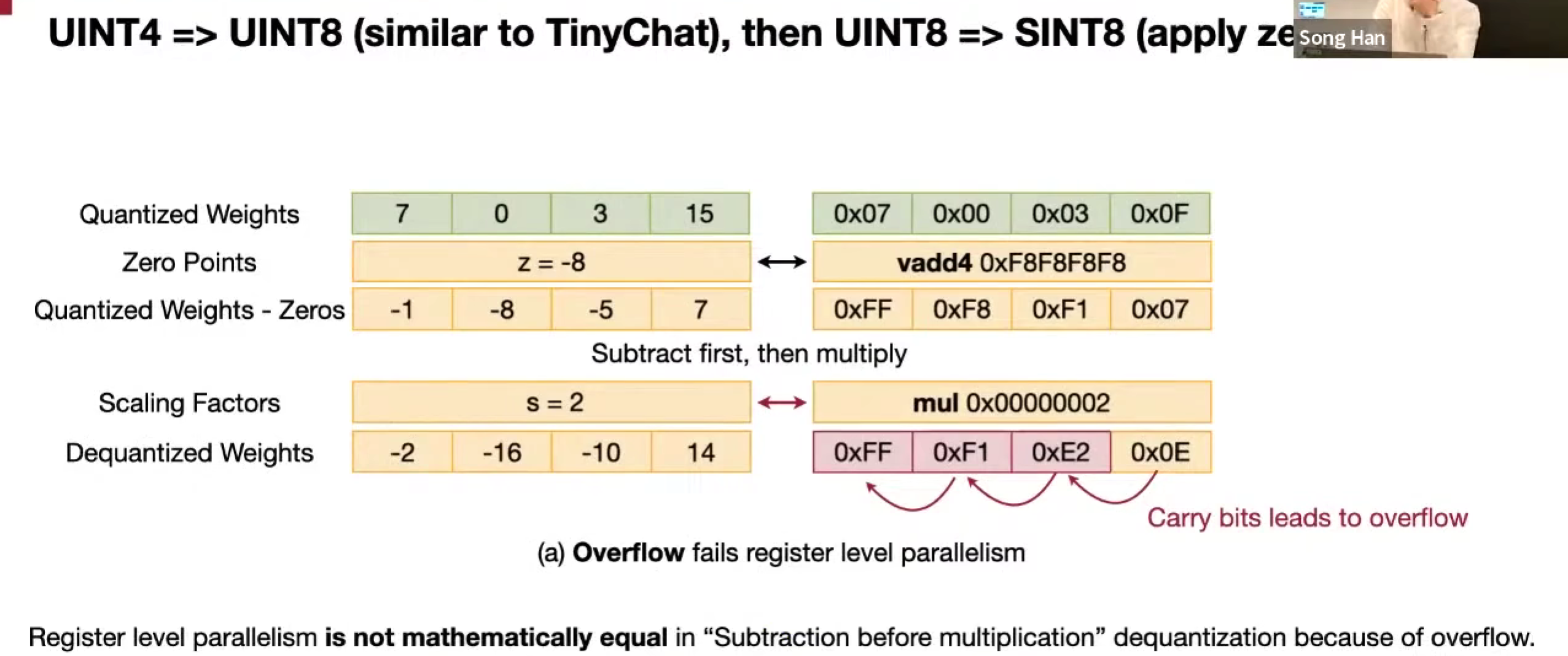
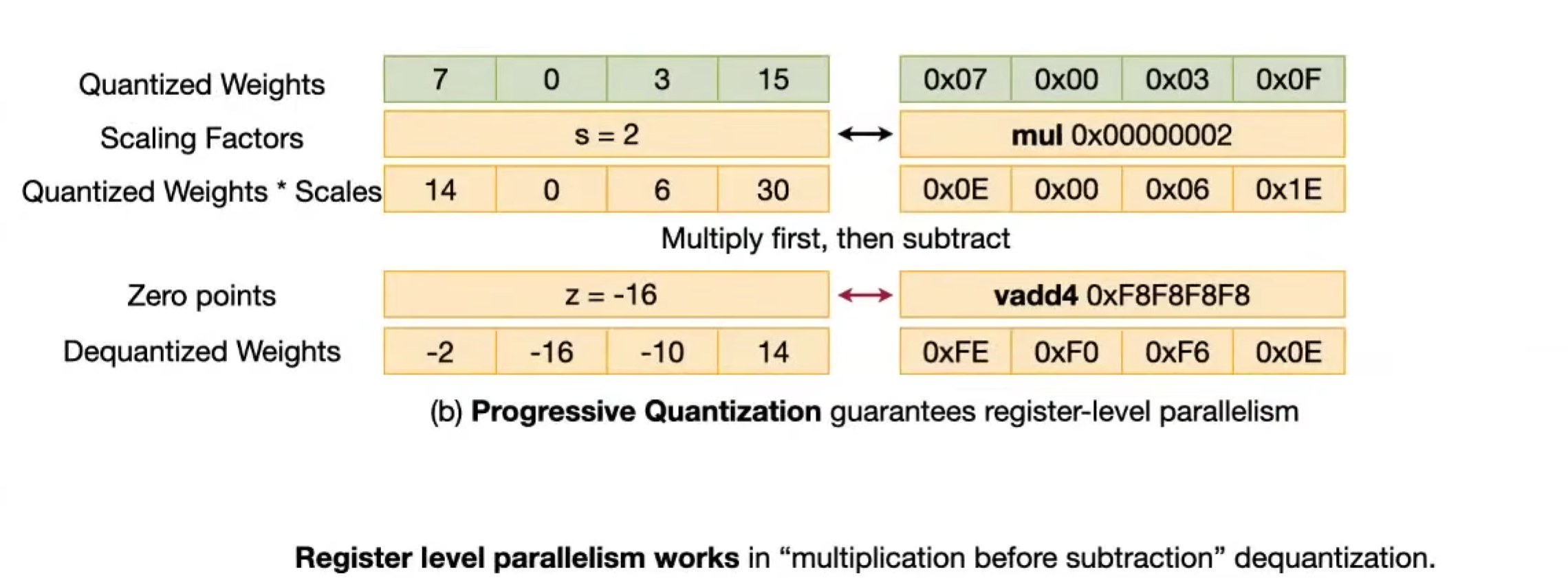
怎么解决 4bit 和 1字节 对不齐的问题?
改变存储方式,为了更好地解码,交错存储

Kernel Fusion
Kernel call 很贵,做融合,BMM,批量矩阵乘法
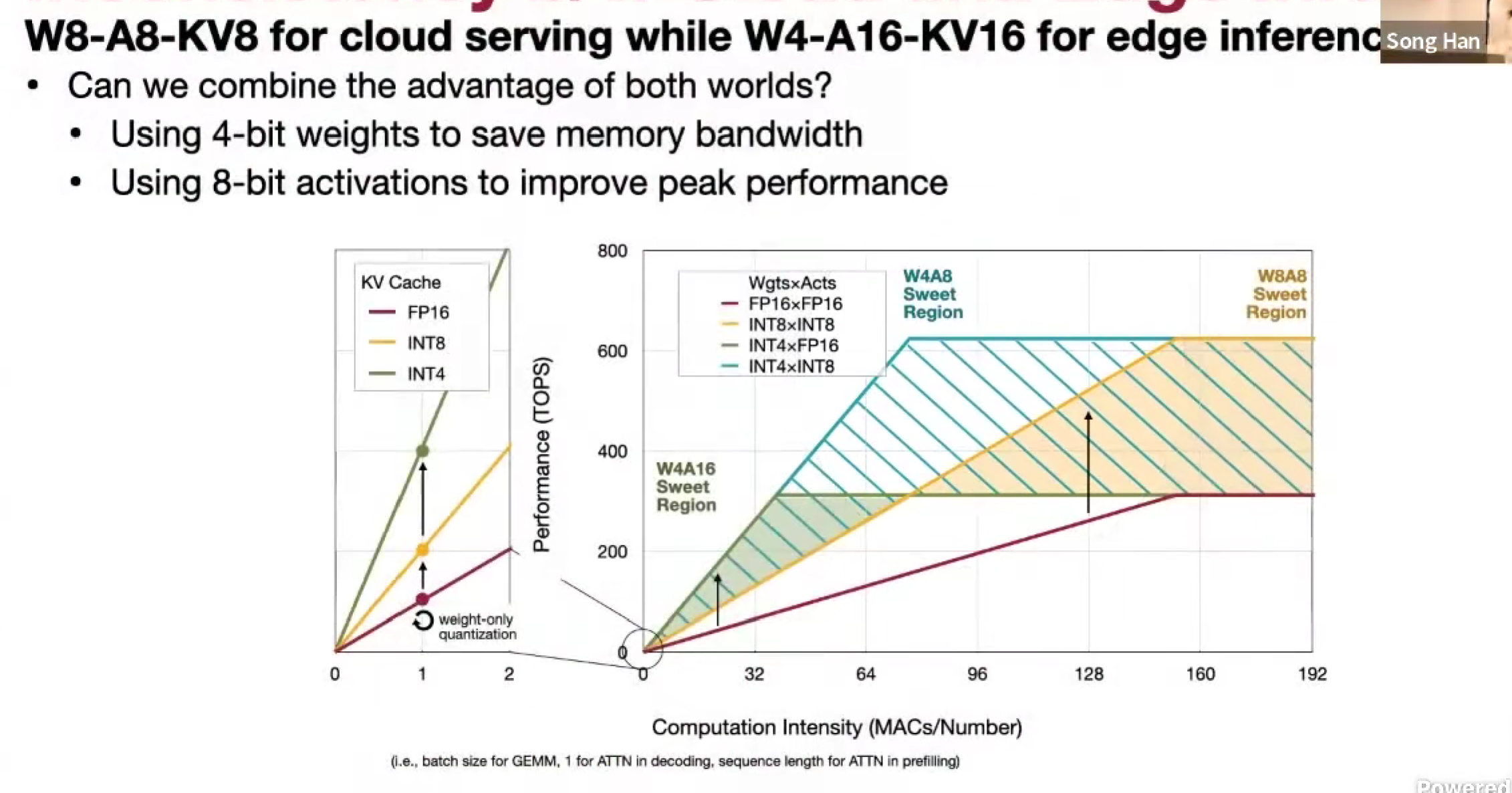
QServe (W4A8KV4)
背景-融合两者的优点
SmoothAttention
类似与SmoothQuant,Q 是平滑的,K 会有某些通道有outlier异常值
反量化,由于溢出可能要调整计算方式
改变位数之后,负数的话,乘一个数,可能下溢出了,所以可以先乘再加减
先缩放还是先加减。
Pruning & Sparsity
Weight Sparsity: Wanda
传统:看权重本身magnitude
Wanda:关注最终激活值小的,对应的权重
Contextual Sparsity
DejaVu (input dependednt sparsity)
?
MoE (Mixture-of-Experts)
提高总参数,不提高推理代价
router路由器分配workload工作
路由机制
token选择expert
expert选择token
全局expert分配
Attention Sparsity
SpAtten (token pruning & head pruning)
Q-K,K列的attention sum,大 = 重要
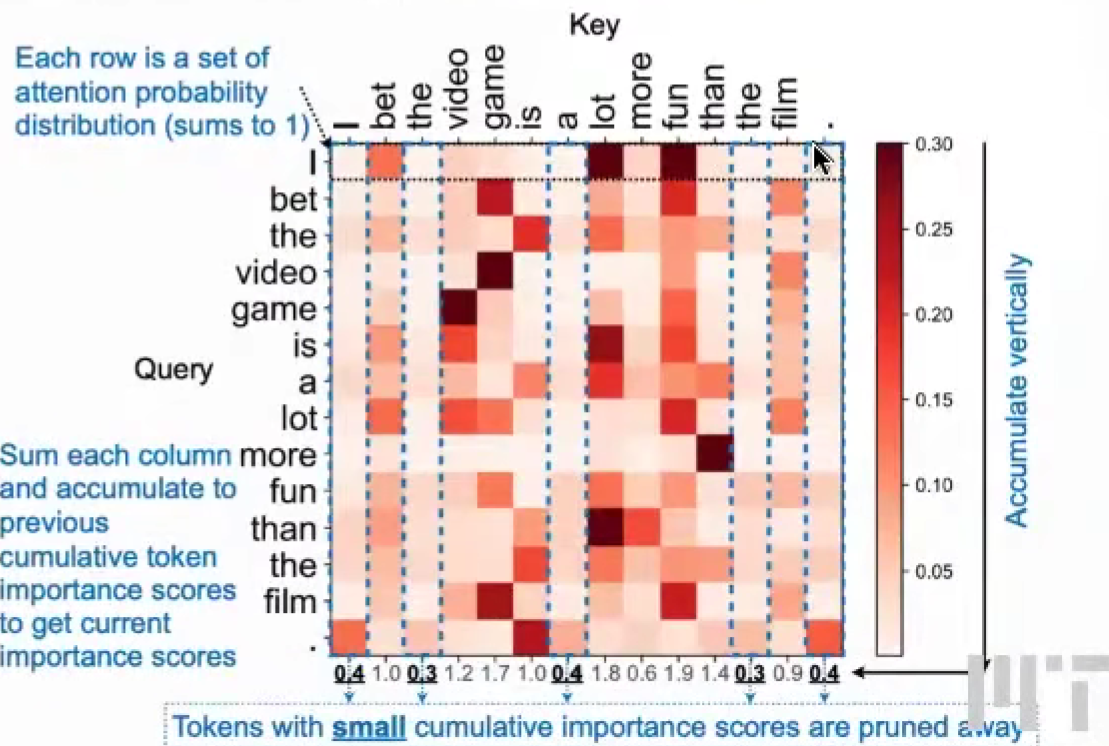
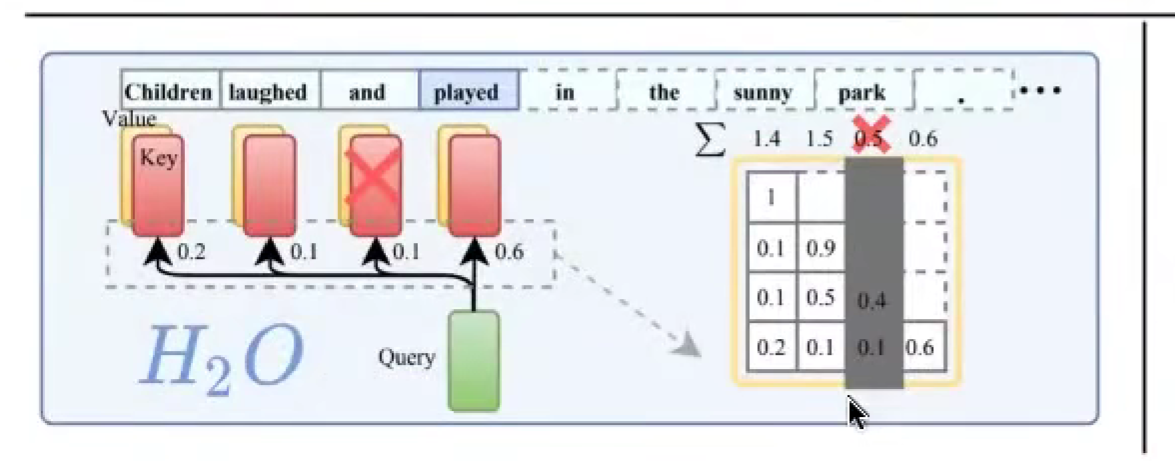
H2O: token pruning in KV cache
LLM Serving Systems
Important Metrics 指标 for LLM Serving
- Time To First Token (TTFT),响应速度,实时互动
- Time Per Output Token (TPOT),每个token所需时间 100 ms/token, 10 token/s
- Latency = (TTFT) + (TPOT * number of token to be generated),总延迟
- Throughput,对所有请求的每秒产生的 token 数
优化目标
最小 TTFT,最大 throughput,减小 TPOT,后两个需要 tradeoff,常矛盾
常用启发式:输出长度,输入长度,模型大小
Paged Attention (vLLM)
KV Cache 的资源浪费
- Internal fragmentation:内部碎片化,由于不知道输出长度,过度分配空间
- Reservation:预留碎片化,现在步骤没用,未来会用
- External fragmentation:多个request,不知道sequence长度,要空出位置
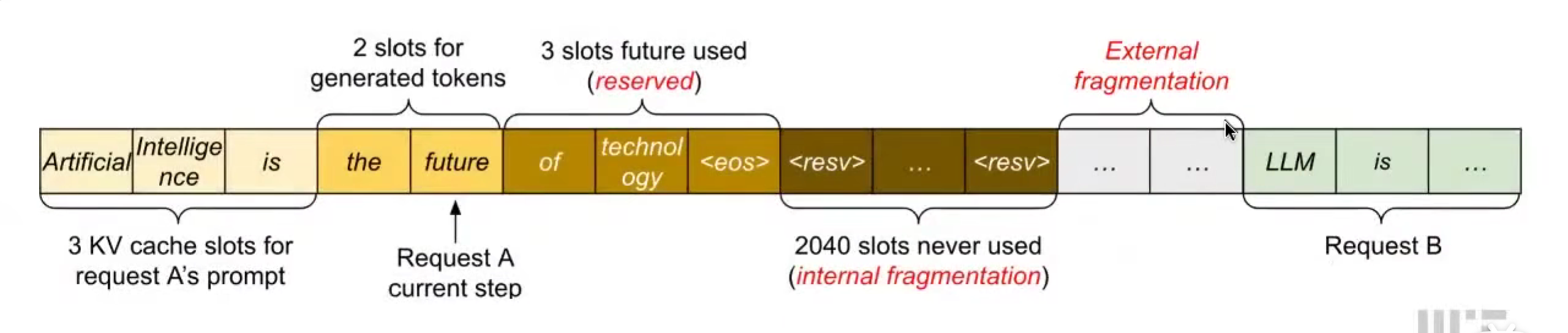
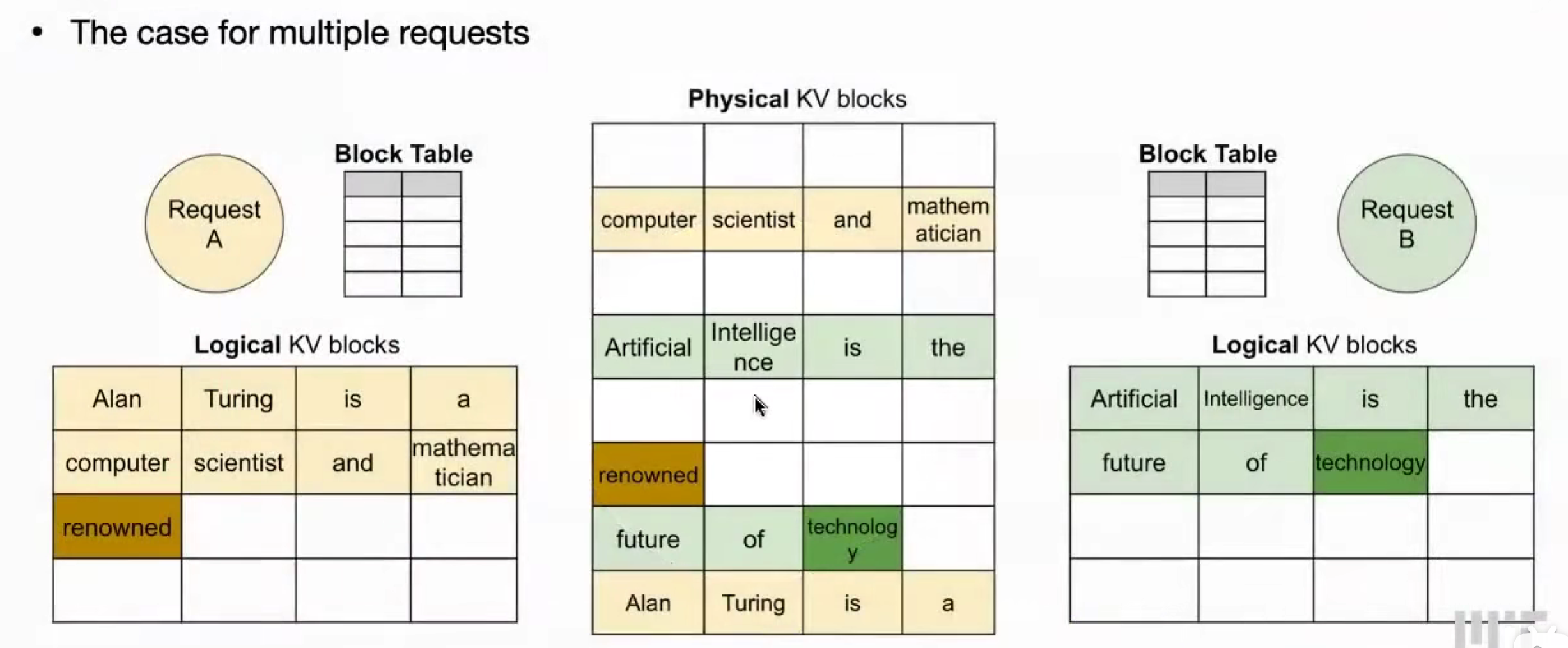
解决 / PagedAttention的好处
由 OS 操作系统的 virtual memory and paging 虚拟内存和分页机制启发
交替使用 KV blocks
- 解决 KV-cache 内存碎片化,支持多访问 requests
- 动态块映射 使得 能够 共享 Prompt
FlashAttention
生成attention注意力矩阵时,NxN 很大
tiling + kernel fusion
Speculative Decoding 推测性解码
小模型 Draft model,生成
大模型 Target model,验证
小模型自回归生成,大模型并行验证(因为大模型运行比较贵)
纠正,重新生成
Batching
增加吞吐量
- no batching,不做批处理
- static batching,静态批处理,固定批次大小
- dynamic batching,动态批处理,批次大小到了,或者时间到了
- continuous batch (in-flight batch),连续批处理,token级别
Lec 14 LLM Post-Training
LLM Fine-Tuning 微调
Supervised Fine-Tuning (SFT) 监督微调
对齐人类价值观/偏好,比如说话更加友好,更加善解人意
helpfulness & safety
Reinforcement Learning from Human Feedback (RLHF) 基于人类反馈的强化学习
BLEU、ROUGE的测试,客观答案,RLHF 更加主观,人类定义的创造性、可信的、有用的
朴素的
奖励模型训练──数据生成结果,人类对不同结果排序,比较函数,排序前的大大大于后的
两方面
- 调整后的模型,不会过拟合奖励模型,和原始模型的内容不能偏差过多
- 奖励模型下的结果不错,符合人类偏好
三个模型,两个损失值
Direct Preference Optimization (DPO) 直接偏好优化
简化流程,转化为单流程的 SFT 任务

Parameter Efficient Fine-Tuning (PEFT)
BitFit (Fine-tune only the bias terms) 只微调偏置项
微调权重需要存储激活值,但微调偏置项不需要存储激活值
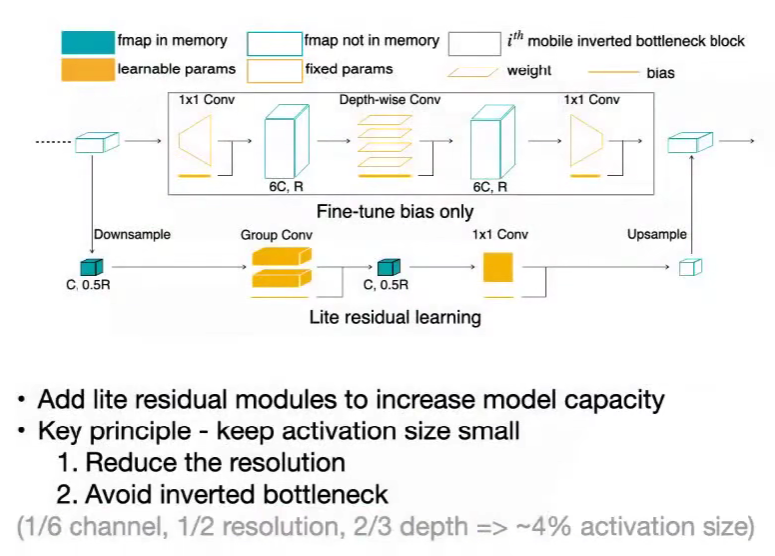
TinyTL: Lite Residual Learning
在主干网络计算量较大的基础上,添加轻量级的侧分支,只更新侧分支,学习残差
下采样 group conv, 1x1 conv,上采样,激活规模小
Adapter 插入适配器层
Adapter Layer:残差,下采样 激活 上采样,bottleneck
对每个任务,只添加一些可训练的参数
会增加模型深度,增加计算开销,延迟增加
不改变模型?
Prompt Tuning
可以训练连续的prompt,学习prompt
Prefix-Tuning
Prompt-Tuning 只对第一层有提示 => 对每一层有提示
增加输入损失,KV cache 使用变大,延迟变大
不引入额外推理延迟?
LoRA
同样训练侧分支
从 d 维 => 低秩 r 维(高斯分布初始化),低秩 r 维 => d 维(零初始化)
最初添加,不会有影响
h = x @ W + x @ A @ B = x @ (W + A @ B) = x @ W'
没有非线性激活,所以可以fuse到原本的矩阵乘法
QLoRA
同样 LoRA 的设计原则,加上对骨架模型的量化
- 引入 NormalFloat (NF4),centroid 不是学到的,是固定的
- 双重量化 Double quantization,缩放因子也被量化
CPU卸载功能的分页优化器,优化状态不用时,存放在CPU,节省内存
Bit-Delta
Your Fine-Tune May Only Be Worth One Bit
出发点是,模型已经学得很好了,微调只需要加一点点参数就好
能不能就微调 1 位,把增量量化至一位,还有一个缩放因子
二值化delta,sin(delta) > 0 => 1 else -1
Multi-model LLMs
Cross-Attention Based: Flamingo
将视觉信息注入inject到语言模型
LLM 参数固定,加入cross-attention layers
视觉信息 KV,文本信息 Q
Visual Tokens as Input: PaLM-E, VILA
全部都 tokenize,视觉信息tokens
解冻LLM参数;
交错使用图文,而不是图文对,否则LLM性能下降严重;
混合数据,还是需要纯文本数据
分辨率重要
高分辨率的处理,分块多少,看任务,OCR 分块多好;知识推理不一定
QKV,把低分辨率作为 Q,高分辨率作为 KV
Enabling Visual Outputs: VILA-U
统一图像和文字理解
Prompt Engineering
In-Context Learning (ICL)
zero-shot few-shot
Chain-of-Thought (CoT)
let’s think step by step
ReTrieval Augmented Generation (RAG)
Lec15 Long-Context LLM
Context Extension
PoPE
增加频率,扩展上下文,然后还需要去微调 Fine-tune
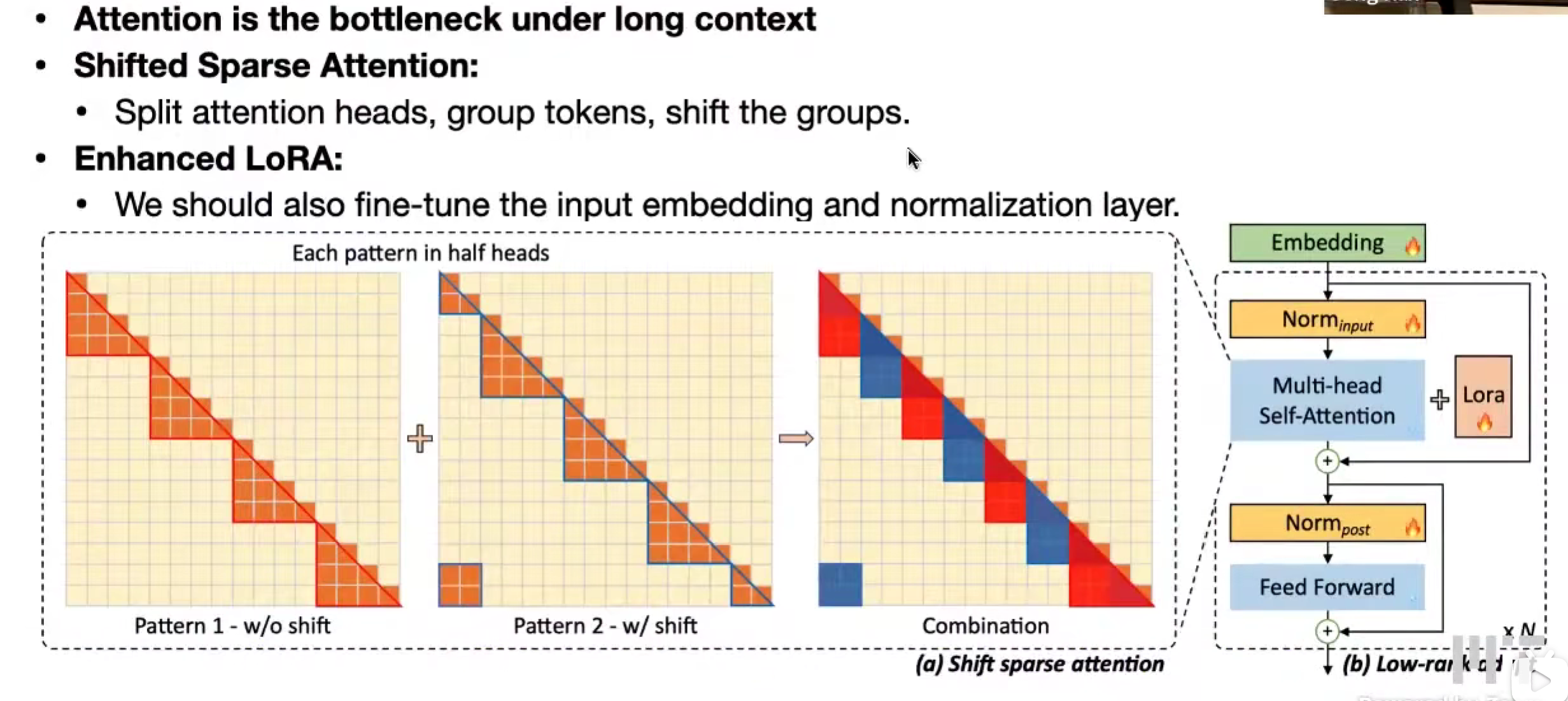
LongLoRA
性能瓶颈:注意力机制。二次增长
偏移稀疏注意力,不同模式,作为一个注意力头
怎么Fine-Tune embedding 和 normalization 层的?
两个模式都用,比单用一个模式好。

Evaluation of Long-Context LLMs 长上下文大模型的评估标准
The Lost-in-the-Middle Phenomenon 中间丢失现象
当相关信息在开头和结尾时,准确率高,中间准确率低。
**生成一段流畅的长上下文回复,不意味着模型真正记住了里面的内容,**所以只用困惑度是不够的。
Long-Context Benchmarks 长上下文的基准测试: NIAH, LongBench
NIAH (Needle In A Haystack) 大海捞针
aa在bb干了cc。做询问
随着上下文的变长,询问在文章xx%的位置的内容needle,检索Retrival准确率。
人为设计的合成基准测试
LongBench
多种任务,发现上下文压缩等技术不如位置编码。
现实世界的测试
Efficient Attention Mechanisms,KV cache 过大的问题
KV Cache
BS * layers * kv-heads * n_emd * length * 2 * type,每个token
StreamingLLM and Attention Sinks
保持恒定内存,Window Attention 的问题,第一个token被移出时,PPL上升
Dense Attention 的问题,在token长度超过预训练长度时,PPL上升 perplex
滑动窗口 + Re-computation 重计算
Attention Sink 注意力汇聚 现象
对第一个token的注意力会高。
用了softmax,注意力得分和为1,就算有些不需要关注,而自回归模型中,首个token是全局可见的,所以把这些冗余的注意力得分给它。
是因为semantic 语义,还是position 位置?是位置。
保留来一个可训练的注意力汇聚点 / 四个注意力汇聚点。
(实验得出四个是 sweet point)
ViT 的注意力汇聚点出现在语义信息比较少的区域。
Bert 在句子末尾的分隔符标记
streamingLLM不等同于长上下文,查询早期的是查不到的,在kv cache中淘汰了。
(DuoAttention 是来解决这个问题)
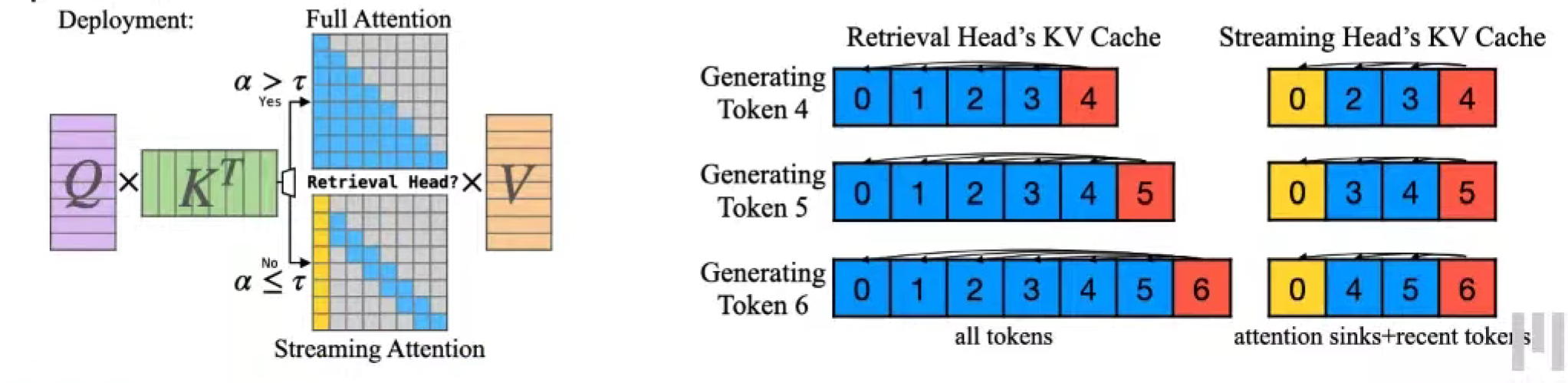
DuoAttention: Retrieval Heads and Streaming Heads
Duo = Two,同样不能无限长,但是能够减缓。
retrieval head 和 streaming head
retrieval head,最初的 dense attention
streaming head,只关注 recent token & reduced tokens
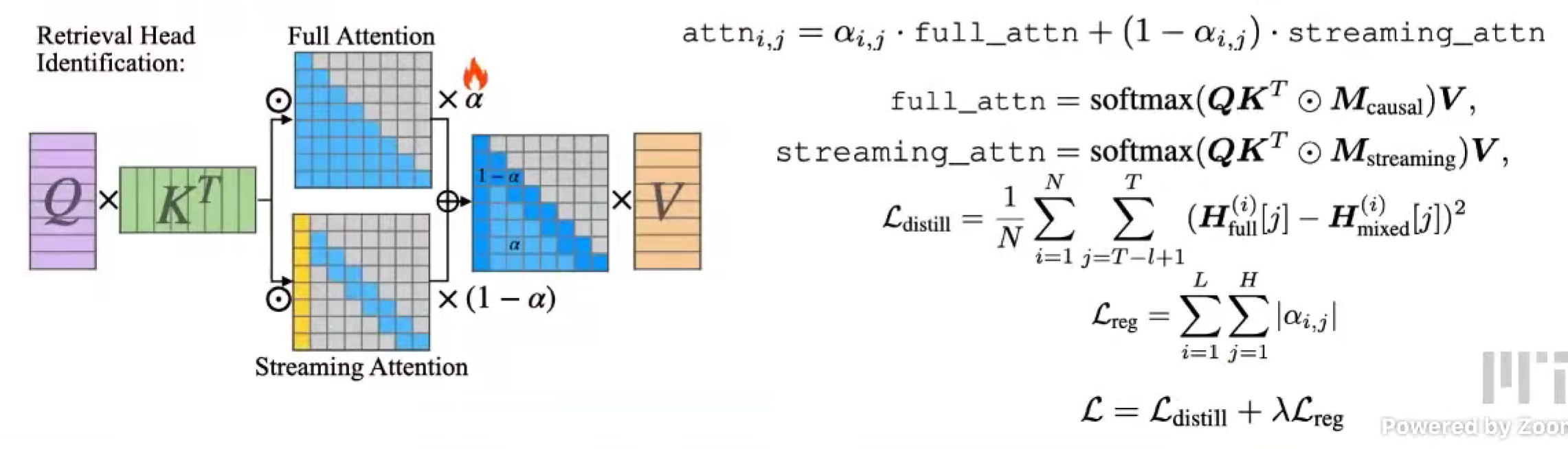
每个注意力头都需要训alpha
因为是要用更少的内存,所以,我们对这个注意力结果做蒸馏distill,使得和最终的差值最小。
需要训练多少个alpha?
layers x heads
训练材料?
类似于NIAH,设置一系列 passkey。
推理的时候怎么办?
设置阈值threshold,大于dense,小于streaming。
decoding
两种 kv cache 一个是全部,一个是sink point + 最近几个token
计算是正常的多头。
prefilling
分块注意力
time complexity $O(L^2) \to O(LK)$
memory complexity $O(L) \to O(K)$
希望 streaming head 越多,节省的越多。
实验中,有一半可以作为streaming head。
实际上是对attention的剪枝、稀疏化。
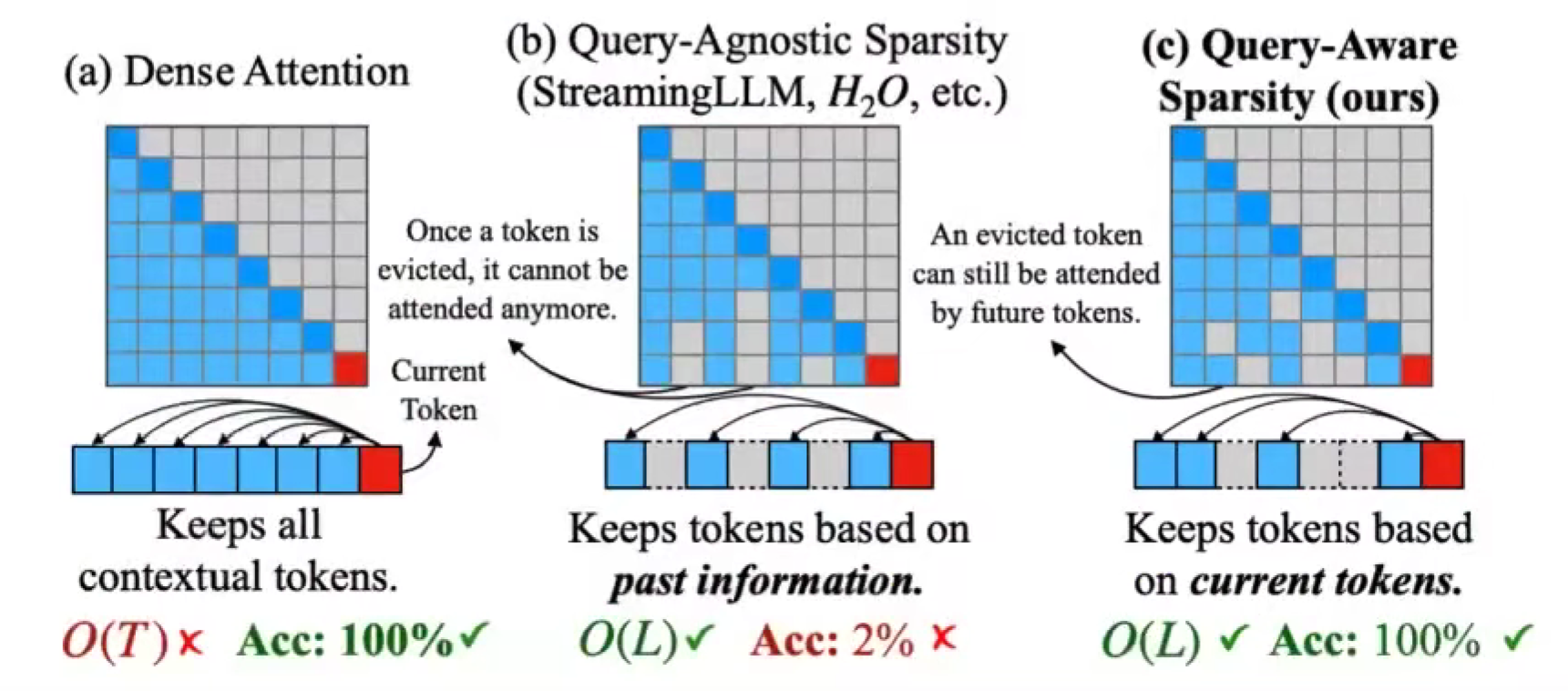
Quest: Query-Aware Sparsity
- Dense Attention
- Query-Agnostic Sparsity 查询无关,要是在前一个token除移除了kv,后面的不会再有这个toekn
- Query-Aware Sparsity,查询感知,前一个移除了,不影响后面还是可以有;基于正在解码的新词元。
因为确实会有某个token对前一个来说不重要,但对下一个很重要的情况,所以我们要全都存下来kv cache,因此没有节省内存,只是节省移动的内存开销,只抓取重要的 kv cache,其他的留在内存中。
同样的对 attention page 求和/求平均,只抓取重要的page,其余的留在内存
Beyond Transformers
State-Space Models (SSMs): Mamba
注意力机制两大任务,不同之间,单个内部。 还是不懂#
Mamba,加基础上引入 Selective State Spafe)
固定的kv cache,不线性增长。
Hybrid Models: Jamba
混合模型。
Lec16 ViT
Basics of Vision Transformer (ViT)
Patch(CNN, patch_size, 3, hidden_dim),Position Encoding,然后就和语言模型一样了
对比CNN,数据量小的时候,CNN好,大的时候,ViT好。
Efficient ViT & accerleration techniques
超分辨率,有实时应用场景;
高分辨率,对自动驾驶重要。
高分辨率,对比CNN,ViT 的计算量提升很快,是二次方的提升,分辨率也是二次方,所以就是四次方。
Segment Anything
Windows attention
注意力机制只在窗口window内发生,固定token大小,计算复杂度的是线性的。
但这样一来,注意力就在局部流通,全局没有了?
Swin Transformer 引入 shift window,shift operation,让下一层的窗口移动,使得能注意到相邻窗口的内容。
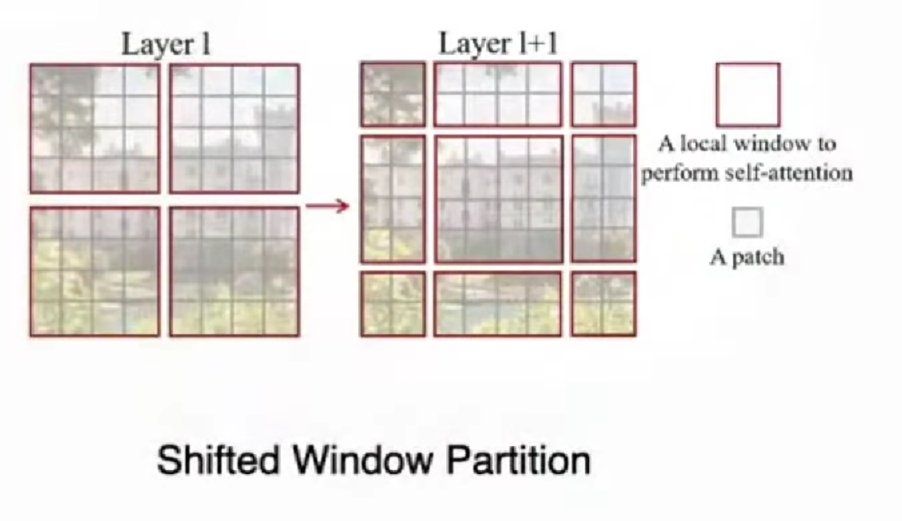
Sparse Windows attention
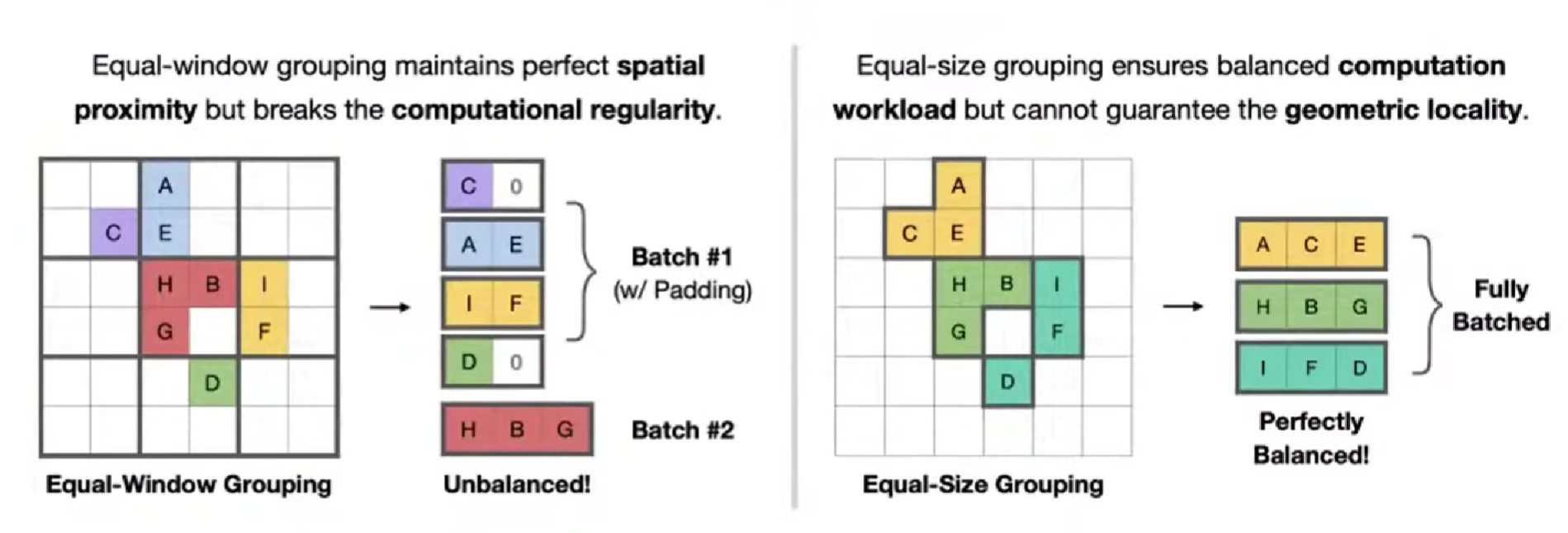
并不是所有的windows都是有用的。
FlatFormer,相比于 等窗口组合,用 等大小组合 ,可以更加硬件友好,更好地并行,不多等待。
Linear attention
替换。
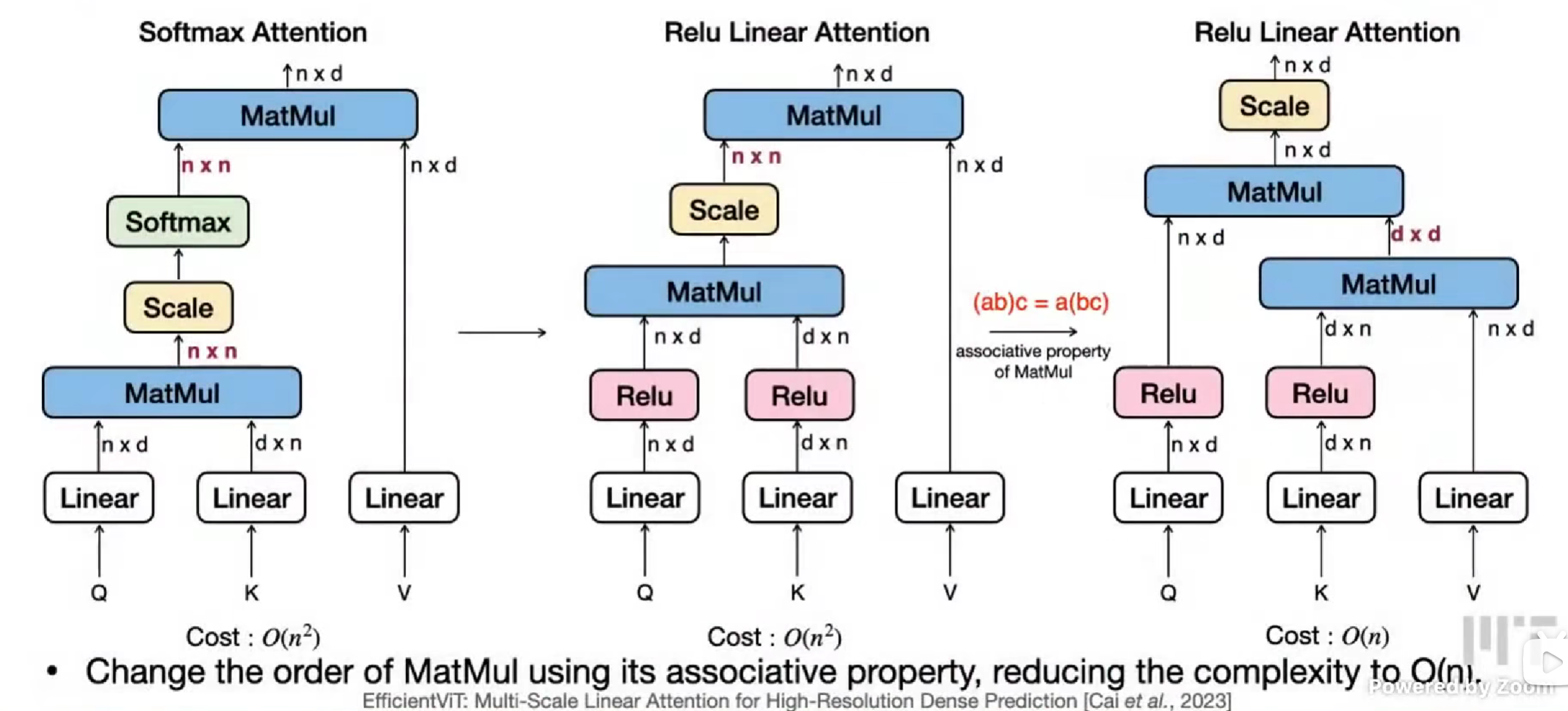
然后发现效果差很多,注意力不突出了。
擅长捕捉全局上下文信息,但局部信息不行。
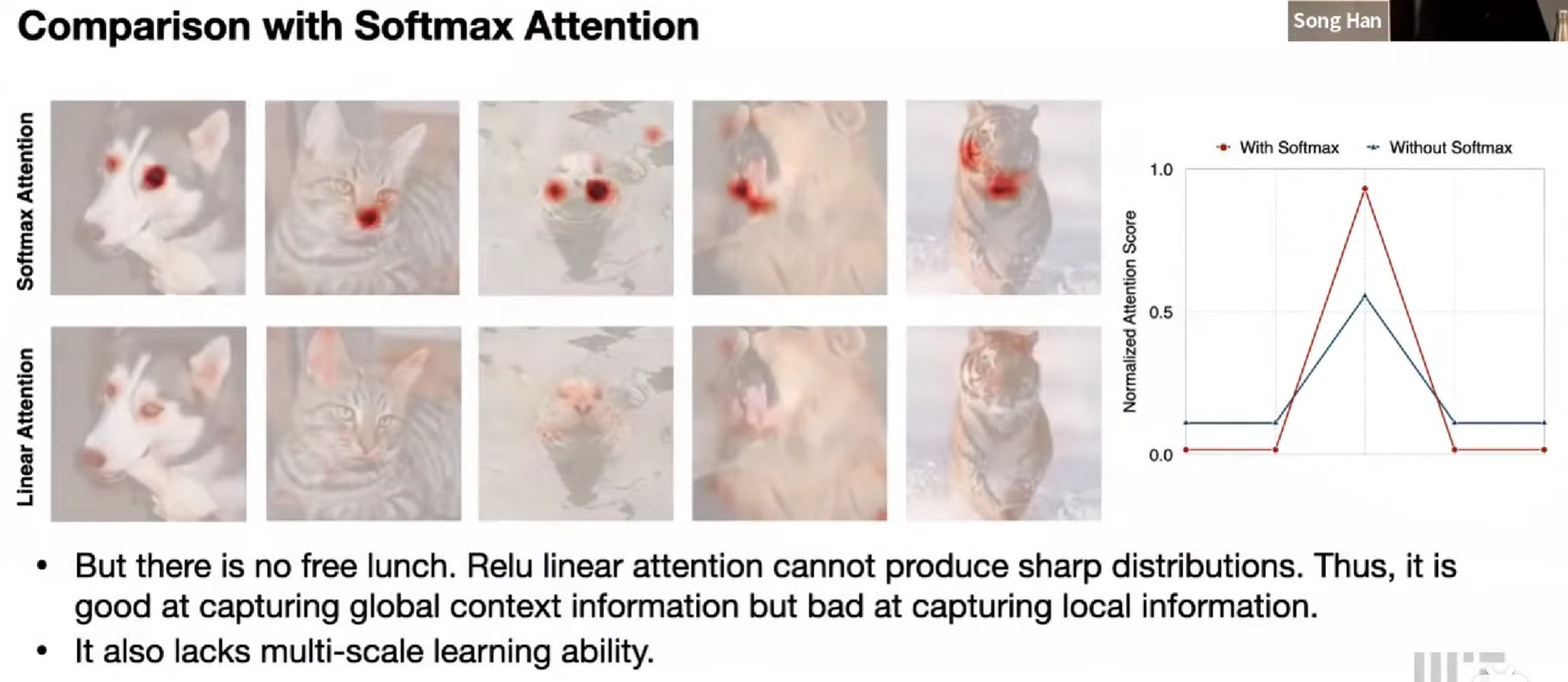
想到CNN是提取局部信息的好工具,在原先的基础上,加上CNN
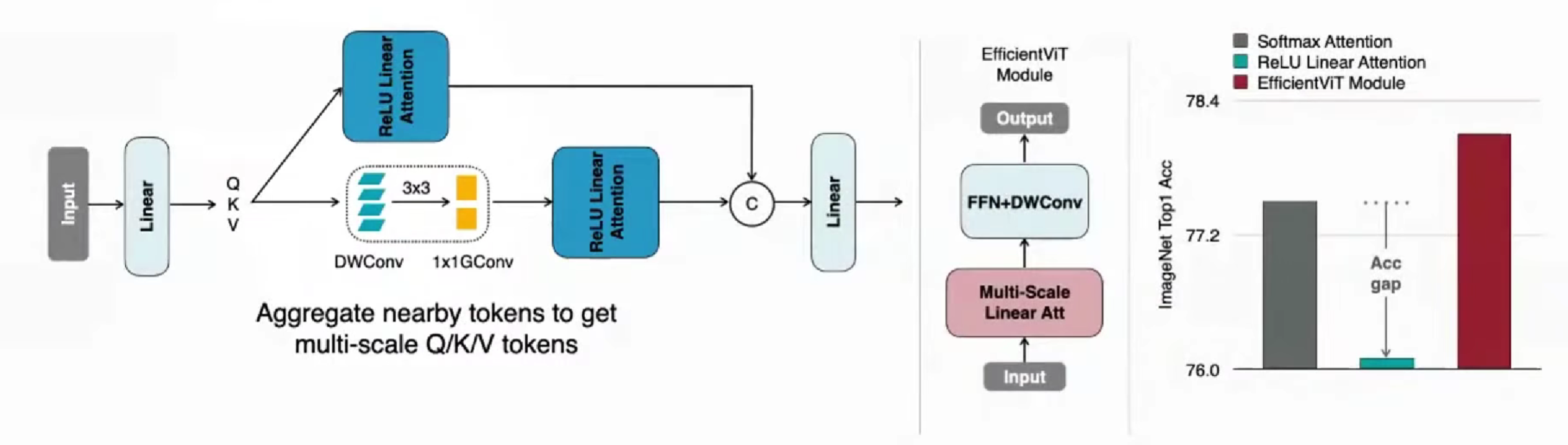
结果提升。(分析新的注意力分布与原本的注意力分布特征的区别,得出的解决方案)
Sparse attention
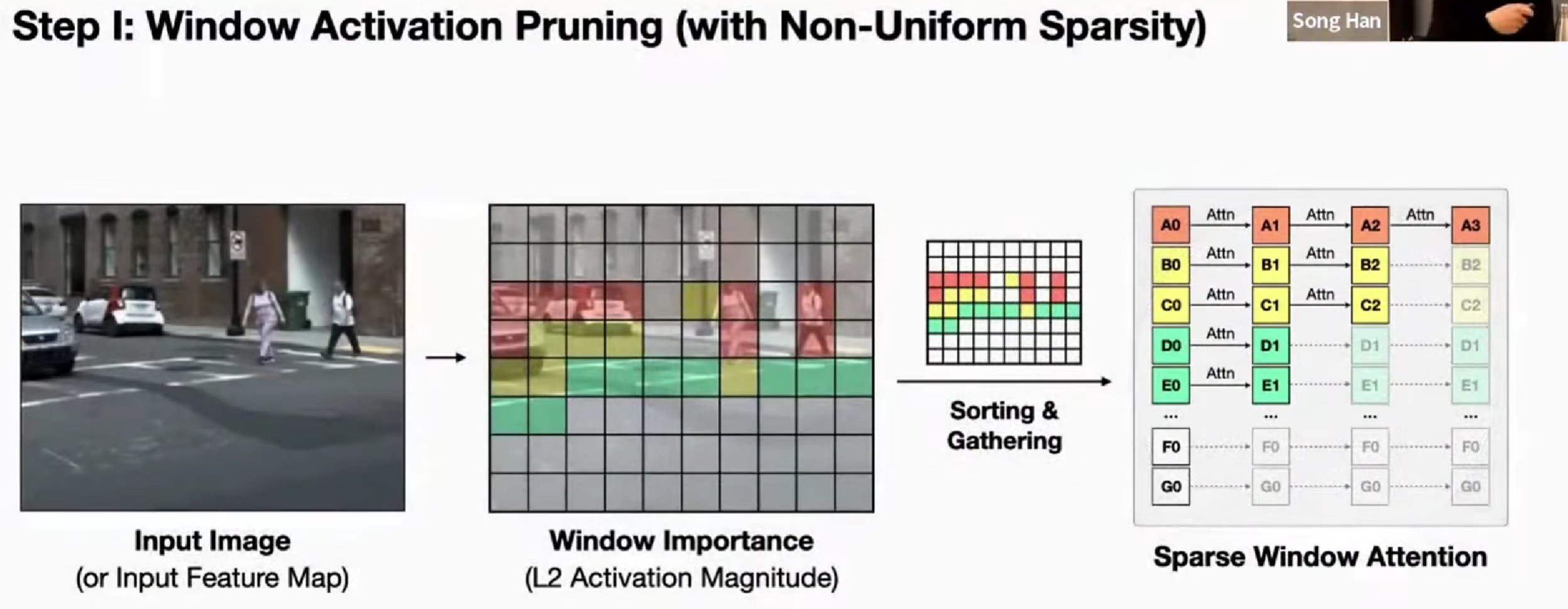
SparseViT,用 L2 激活值来确定窗口的重要程度。
分出不同的重要程度,可以在不同层使用不同的稀疏度。
Self-supervised learning for ViT
怎么利用unlabeled data
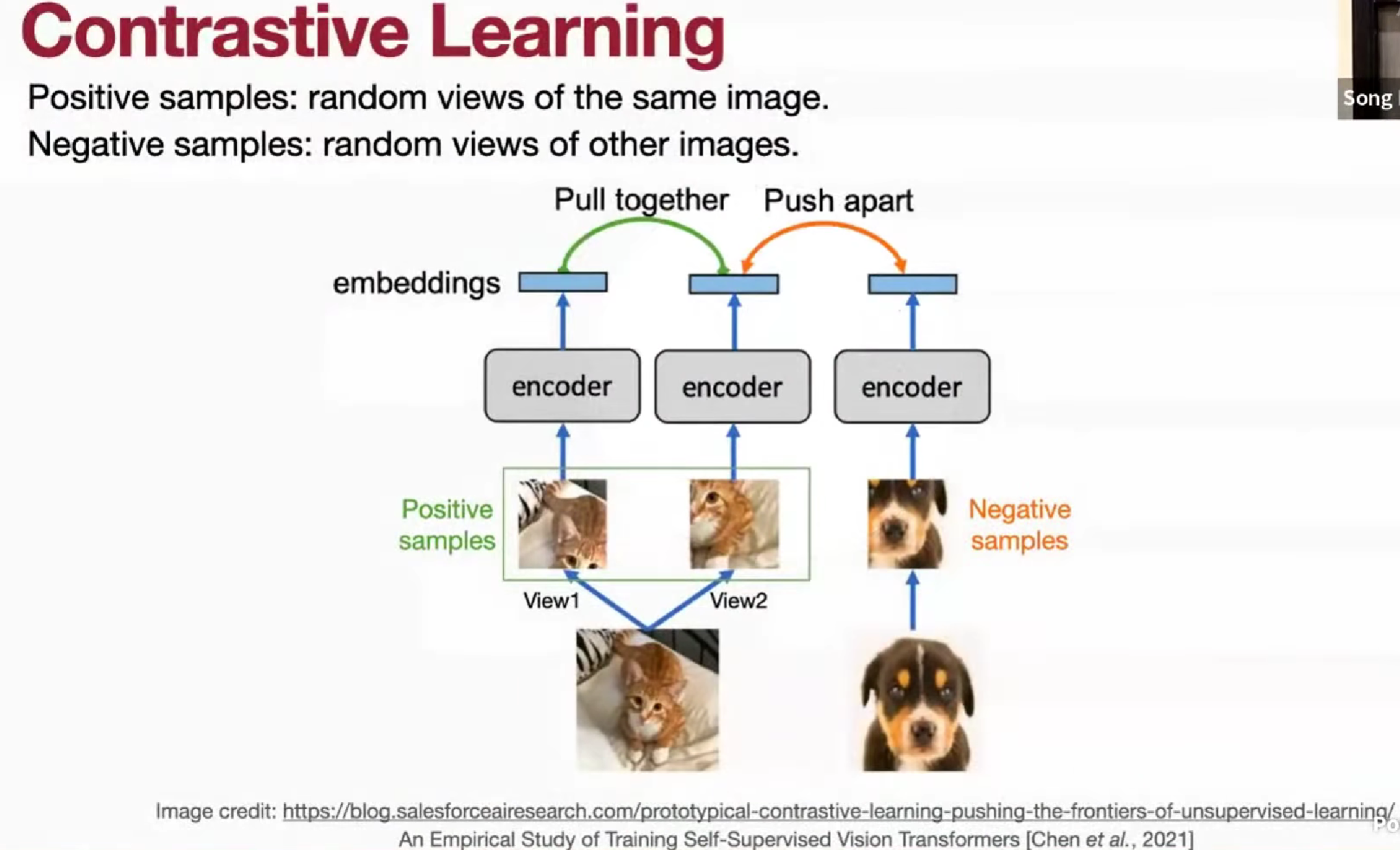
Contrastive learning
拿同一张图片的不同 crop,去做同一的、拉近的 loss,不同的图片做拉远的 loss。
在小数据集上训的时候,SL,更大的模型可能得不到更好的结果,但是用了对比学习自监督self-SL(CL)会更好
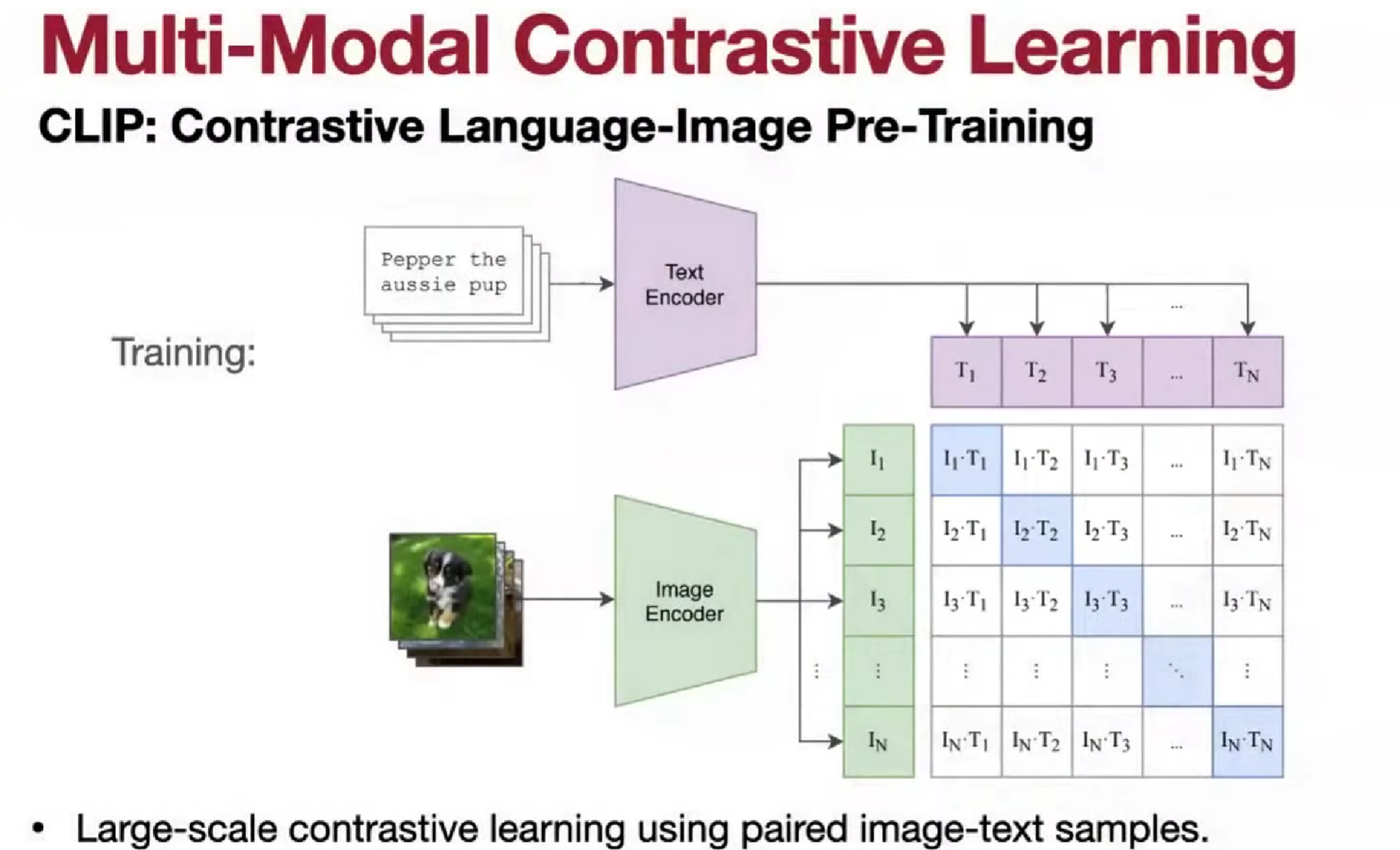
多模态对比学习 CLIP
Masked image modeling
类似与bert的重建遮挡,Mask Language Models, MLM。
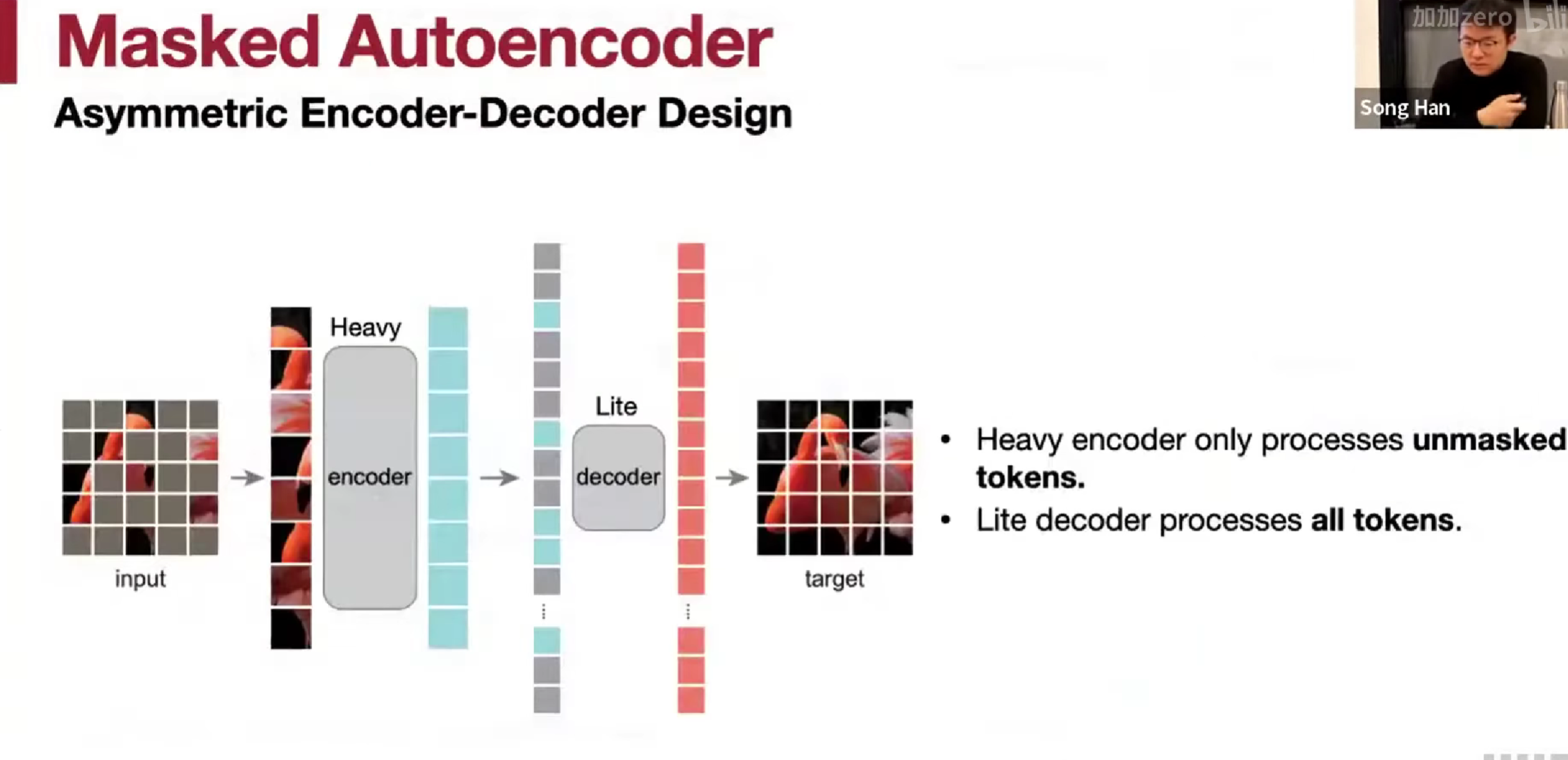
Heavy encoder只编码未遮的图片,lite会编码所有。
mask 70~75% sweet spot
作为对比,bert 比率是 15%,图片冗余大。
ViT & Autoregressive Image Generation
Autoregressive AR。
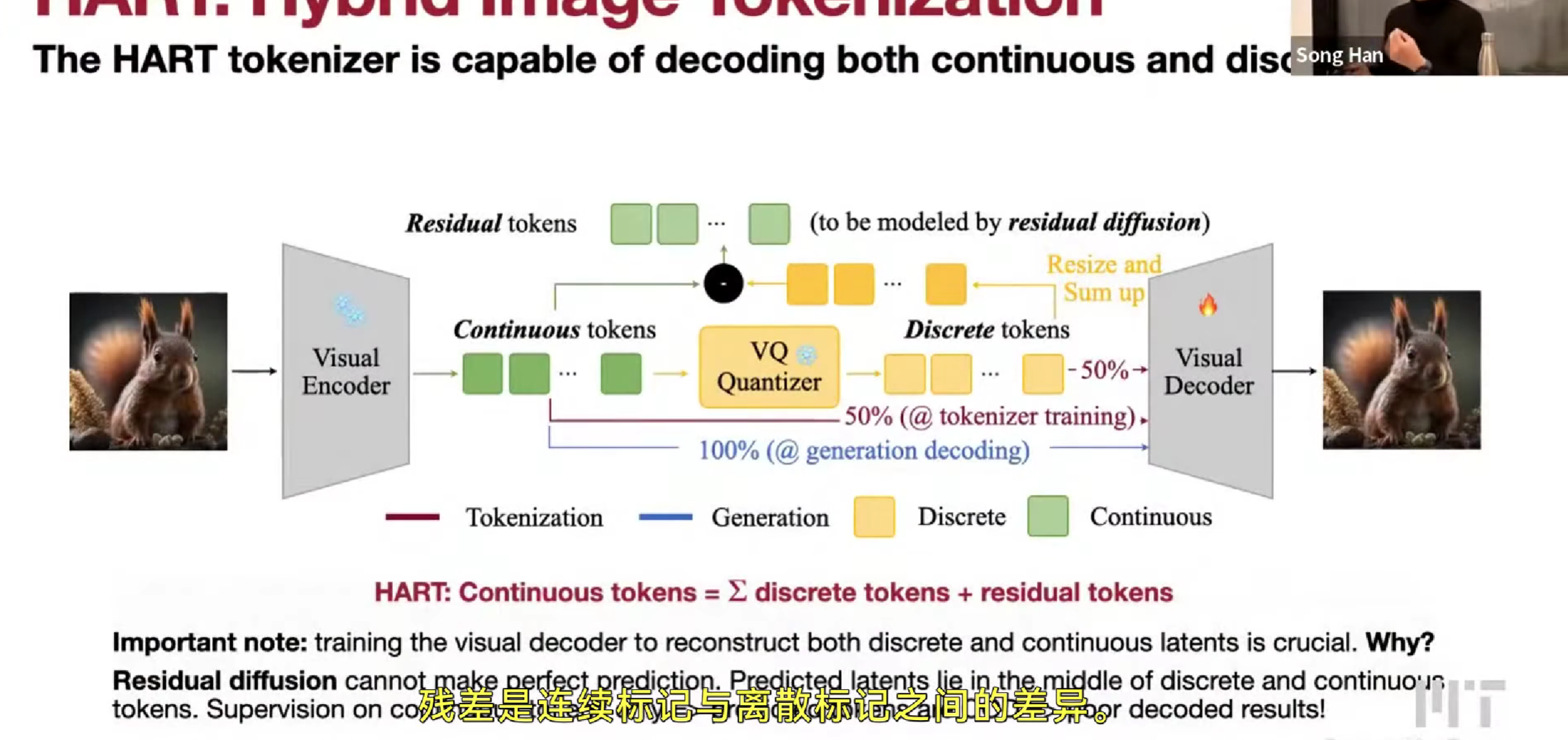
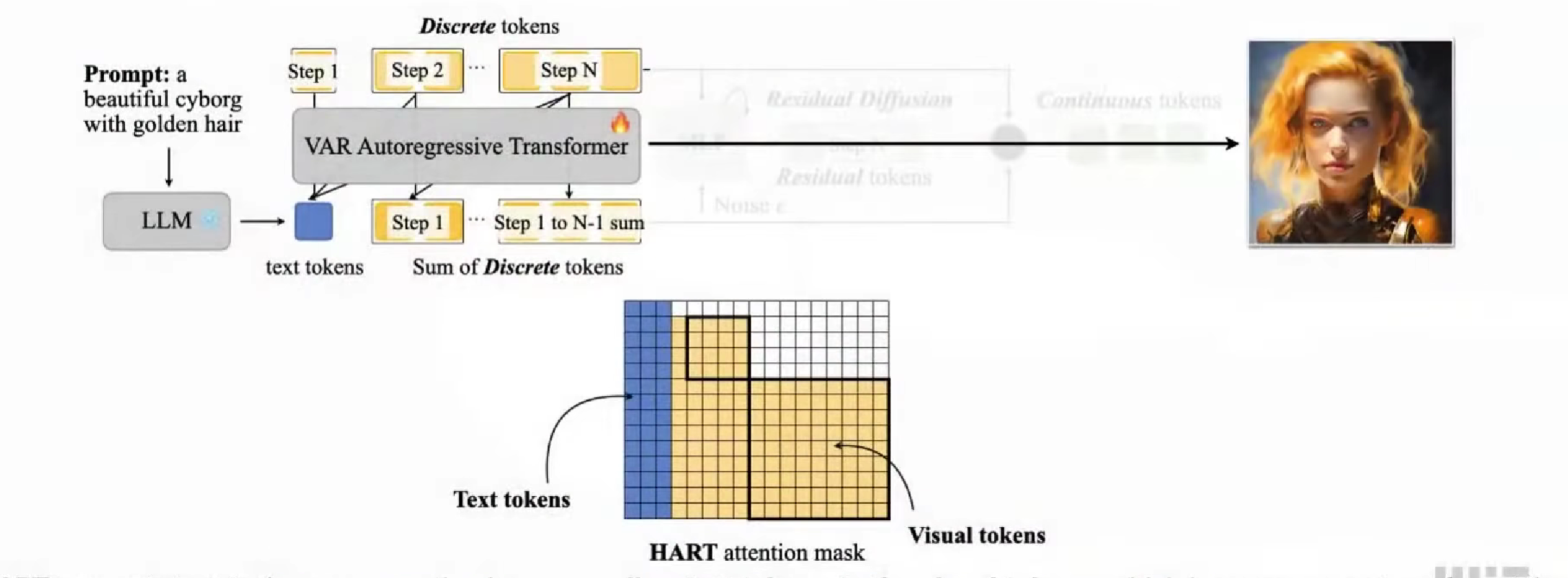
Hybrid Autoregressive Transformer (HART)
和新目标是减少迭代次数来加速。
有三种不同的生成方式。
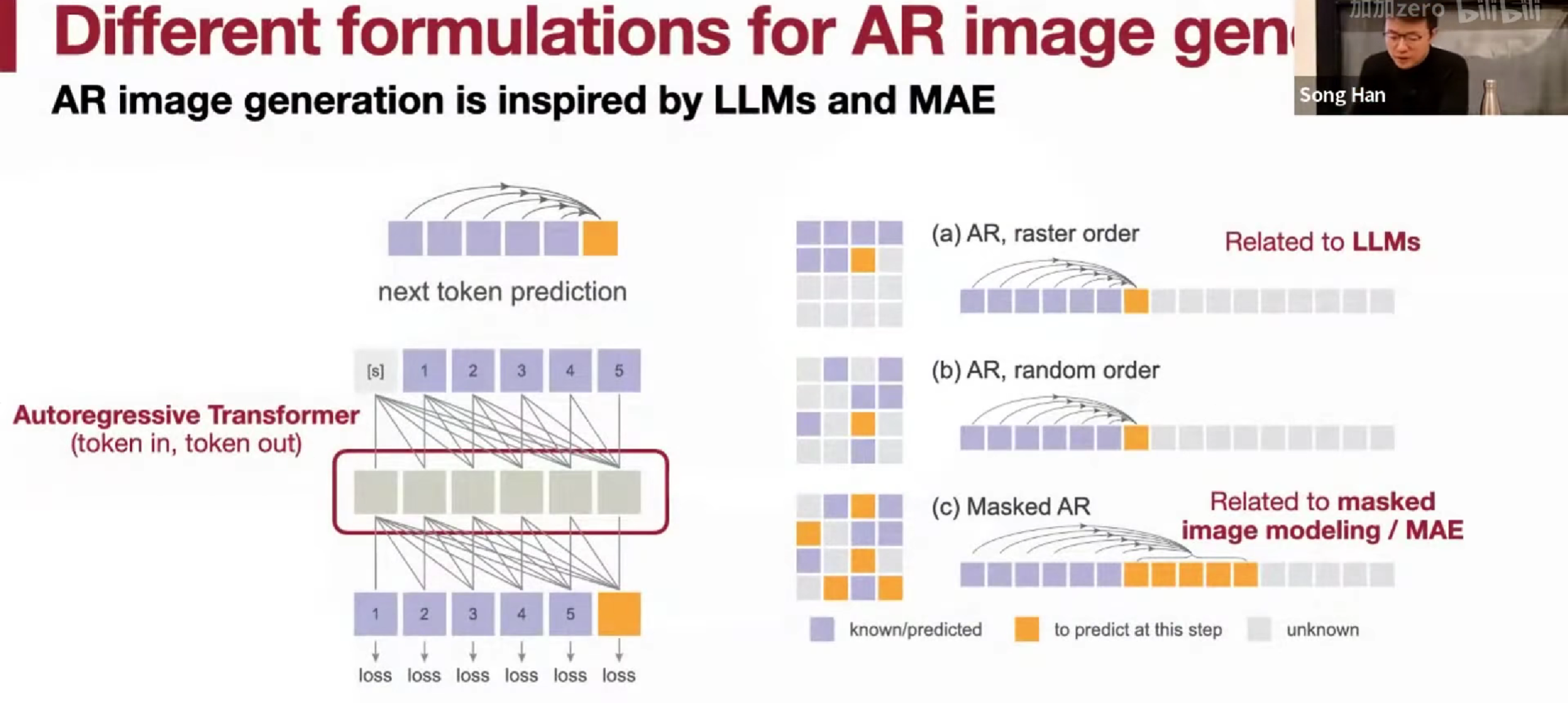
文字生成和图像生成的不同,语言有词汇表,离散的,而图像是连续的。
要用一种AR架构把这两种模态统一起来,就需要一种离散的图像标记,就可以使用同样的loss了。
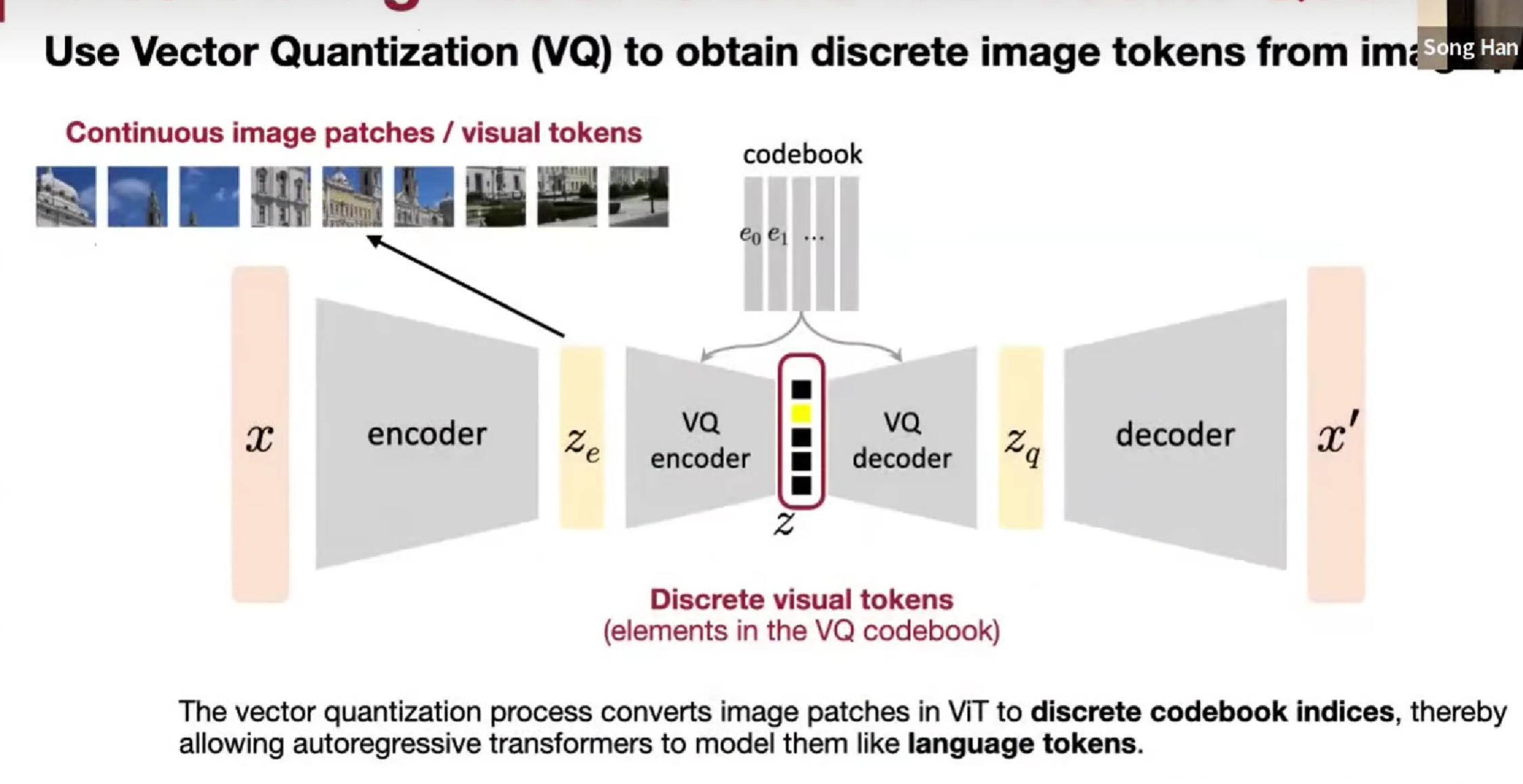
具体的,加入vector quantized, VQ encoder/decoder和 codebook,一个像素的vector量化是一个标量(量化)。
经验法则:一次性生成更多的标记token。
Visual Autoregressive,VAR,引入新的标记生成方法。
先为一张图像生成一个token,和分成2x2…,多个粒度。

他的 attention mask,也有变化(没特别理解
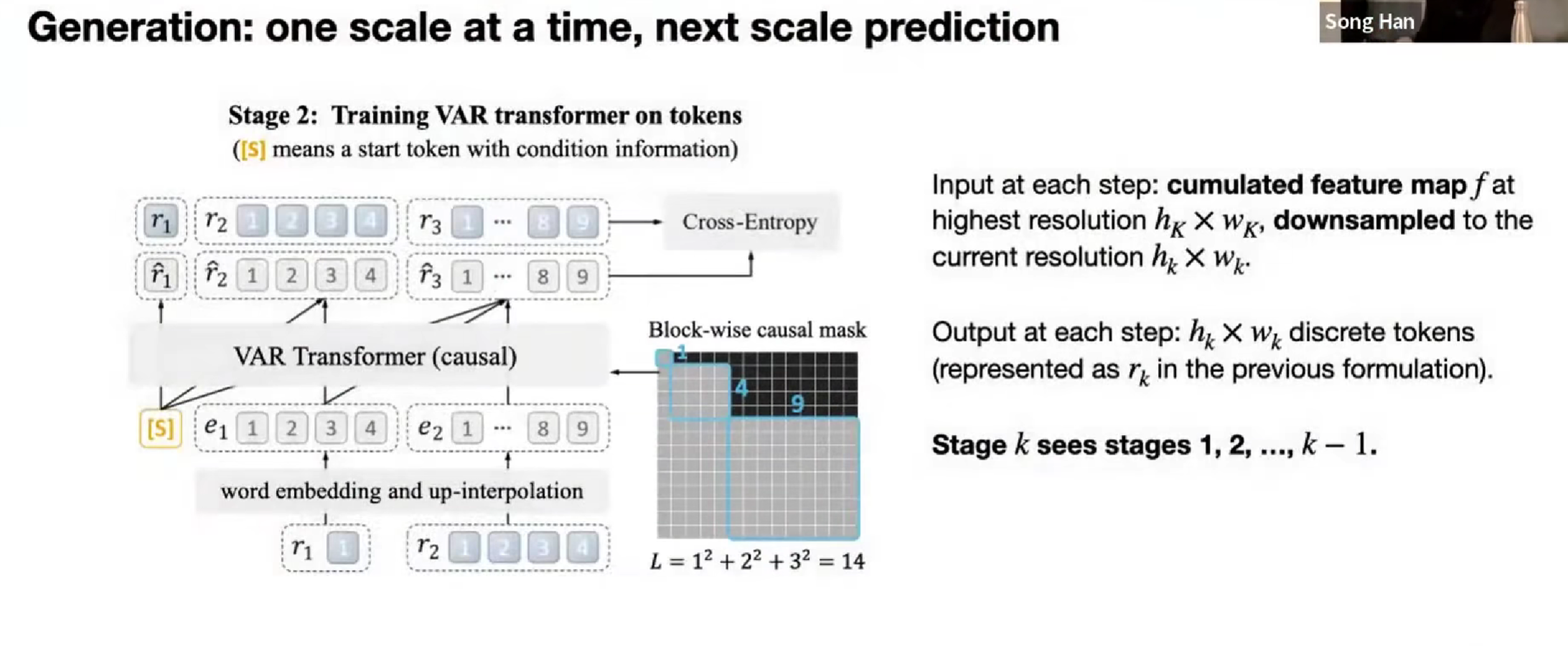
不过效果没那么好。
Hybrid Image Tokenization,HART
小的duffusion model,residual duffusion残差扩散,来学习离散token和连续token的区别(因为离散token自己学细粒度的很困难)
训练时候采样50% 50%,让两者在 decoder 中处于同一空间

Lec17 GAN, Video, Point Cloud
Efficient GAN
显然为了加速推理,压缩 generator
un/conditional GAN
提供条件(class, segmentation map, strokes/随机噪声
GAN 比识别的模型贵
GAN Compression
重建reconstruction loss,蒸馏(中间特征图)distillation loss,cGAN loss(真实图片和生成图片)
AnyCost GAN
StyleGAN2只采样最高分辨率,MSG-GAN采样所有分辨率,随机采样
不同通道数量,增加蒸馏损失,可以使得删去通道后的图片样式类似
同样的判别器对于不同的分辨率效果不一定都好
Differentiable Augmentation for Data-Efficient GANs
需要收集很多数据,贵
图片增强
只对真实图片增强,颜色改变,图片位置shift,部分cutout,会导致生成的图片也长这样,所以不好
(训练D的时候)在生成后都应用,判别器对转换后的图片的判别率高,对原图片 G,效果不好
在训练(G和D的时候)都判别前运用图片转换
Efficient Video Understanding
temporal modeling 时间建模
2D CNN
采样图片,再aggregate,average max
双流网络 spatial + temporal,optical flow
2D CNN + Post-fusion(e.g. LSTM) ,low level 是独立处理的
好处,计算高效,重复利用图片识别2D CNN
坏处,时间信息,光流计算量大,late fusion 无法建模 low level
3D CNN
C3D,参数量变大
I3D,用2D CNN来初始化3D CNN,inflation,就重复
好处,时空信息一起 ,各个级别的信息都可以建模
坏处,模型大小,计算量都变大
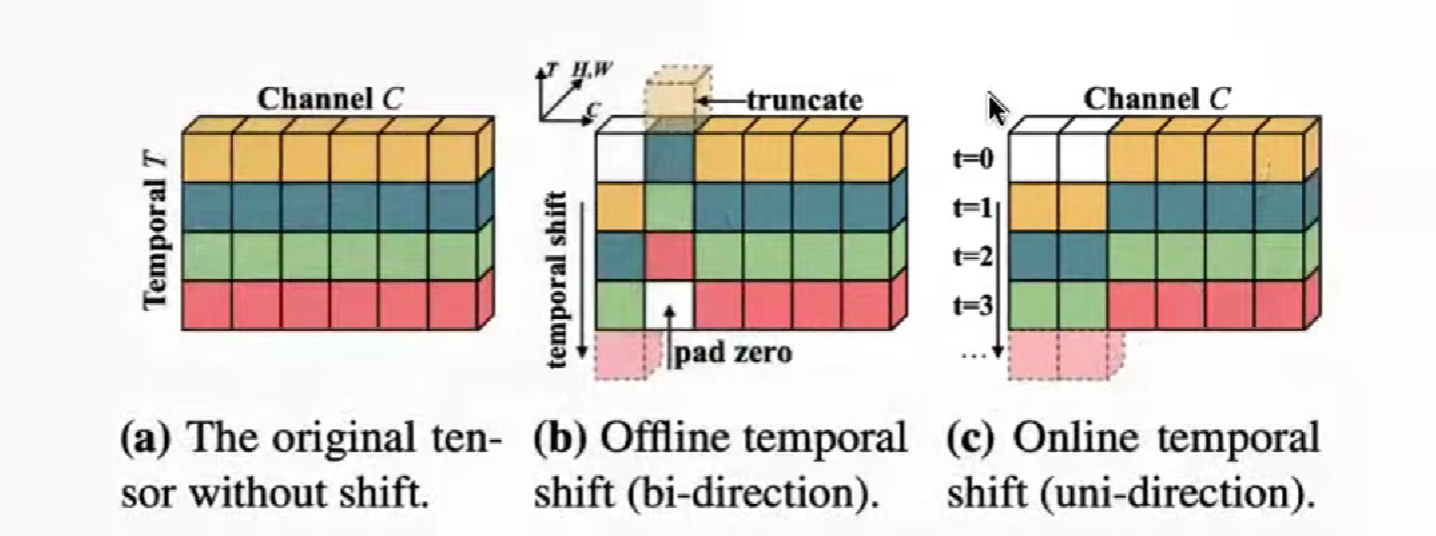
TSM (Temporal Shift module)
不用计算量、参数来为时间建模
offline,bi-direction 可以做双向
online,uni-direction 做单向
shift 的比例,不能太多也不能太少
Efficient Point Cloud Understanding
稀疏,非规整;应用场景算力限制
PVCNN / SPVCNN
Point-Voxel,Point local,Voxel global(稀疏掉0,让 point 去做高粒度)
3D NAS SPV
BEVFusion (Bird’s-Eye View)
Dense 摄像头,Sparse 雷达,产生BEV + 3D 对象检查
Lec18 Diffusion Model
Basics of diffusion model
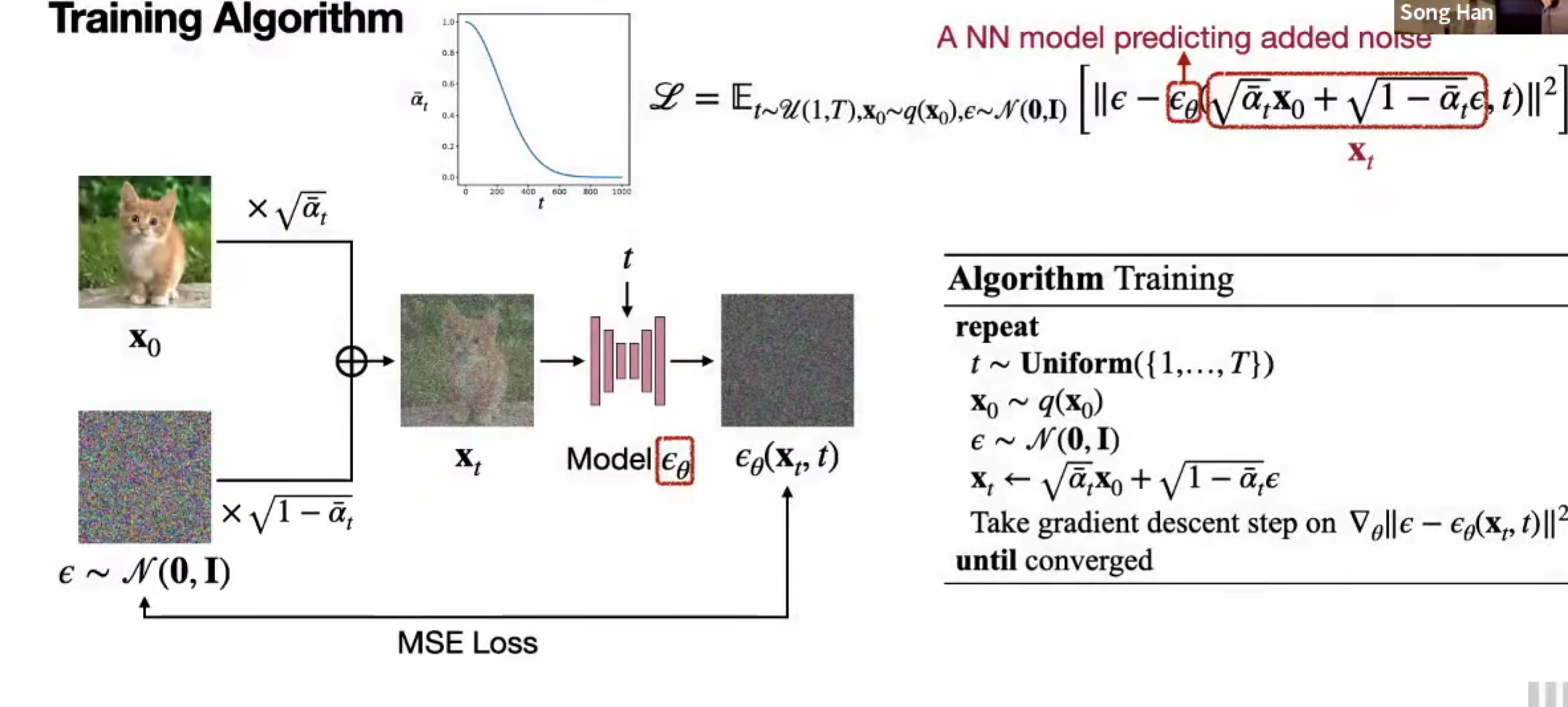
Denoising diffusion models


训练算法
采样算法

Conditional diffusion models
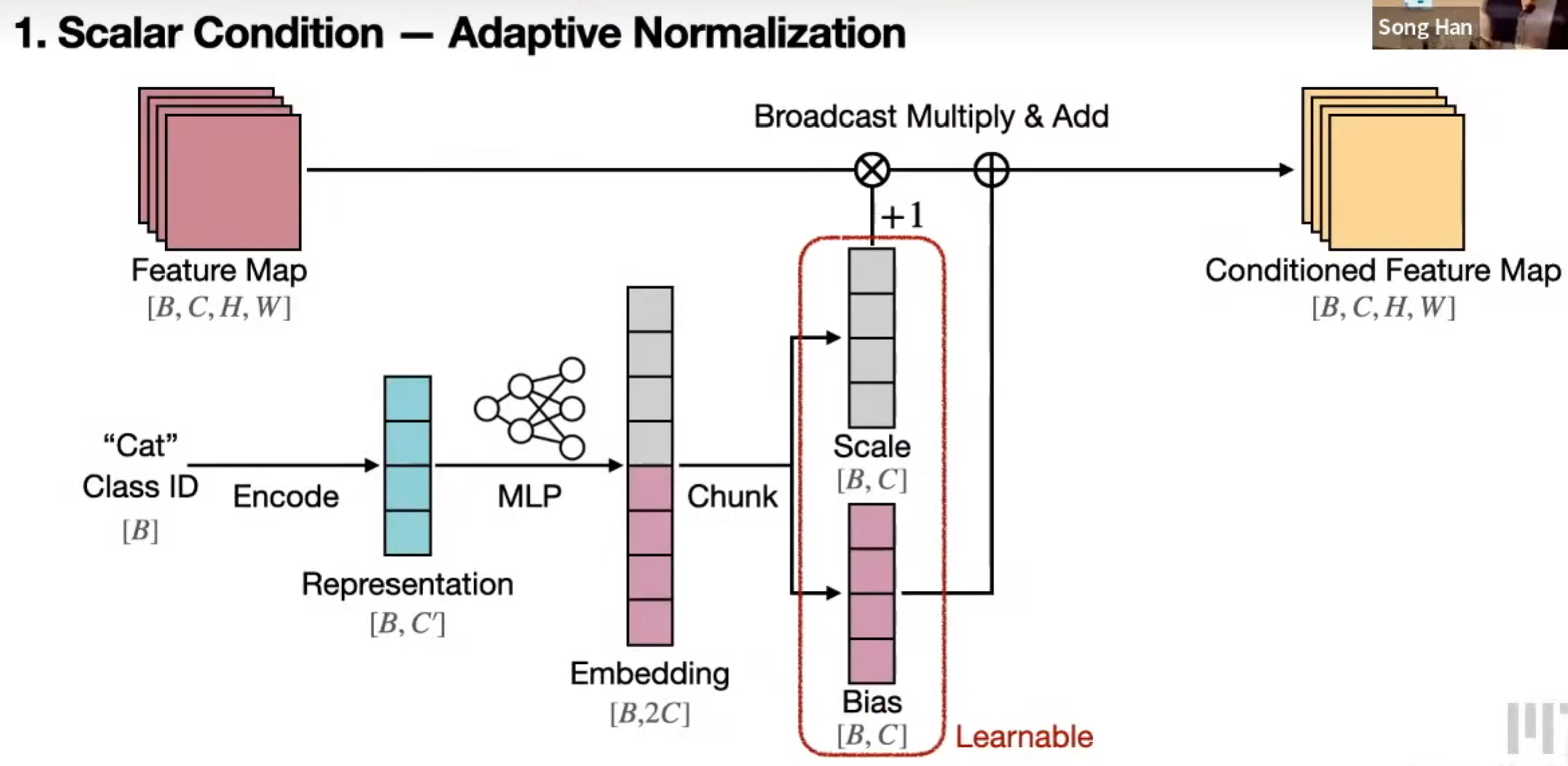
Scalar condition
Class ID,encode,embedding,加到特征图上(或者embedding scale 和 bias更加复杂)
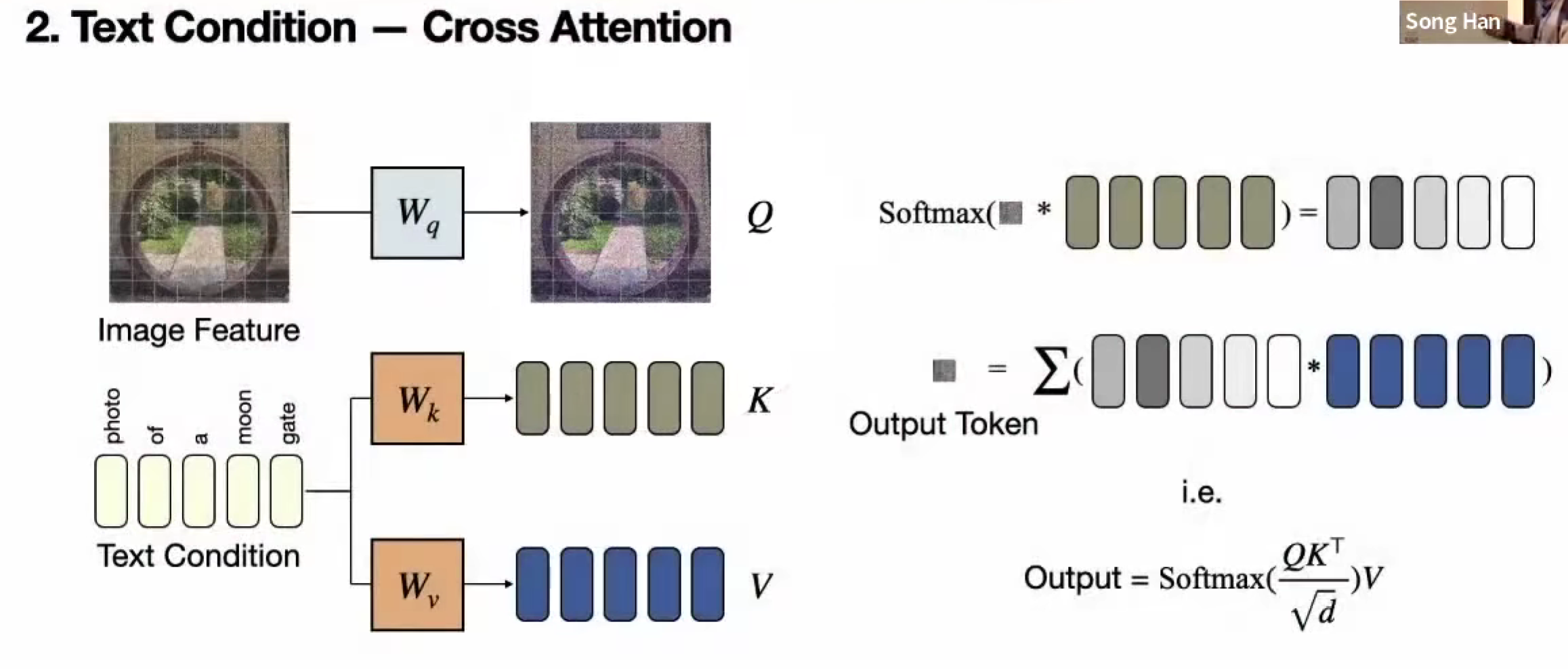
Text condition
Cross Attention
图像和文本并不对称,图片 Q,文本 K V
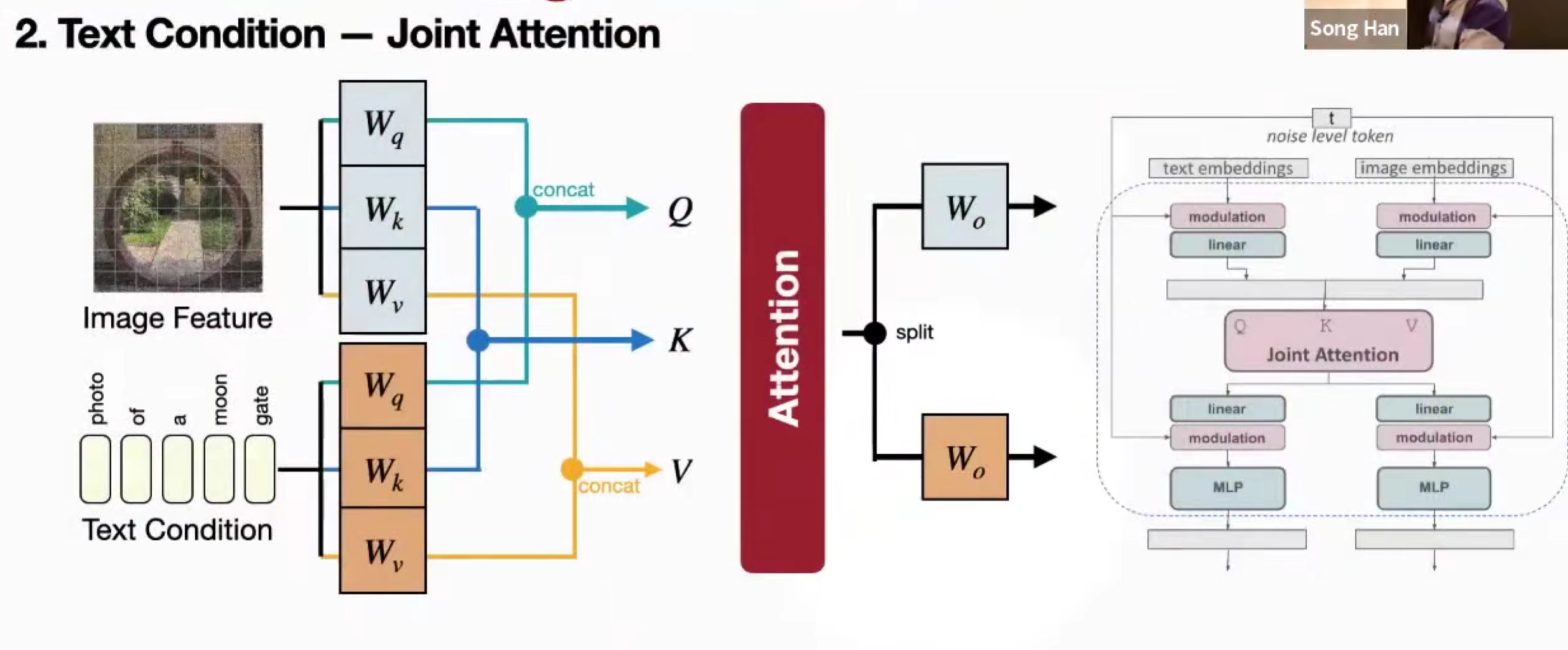
Joint Attention
文本和图像对称
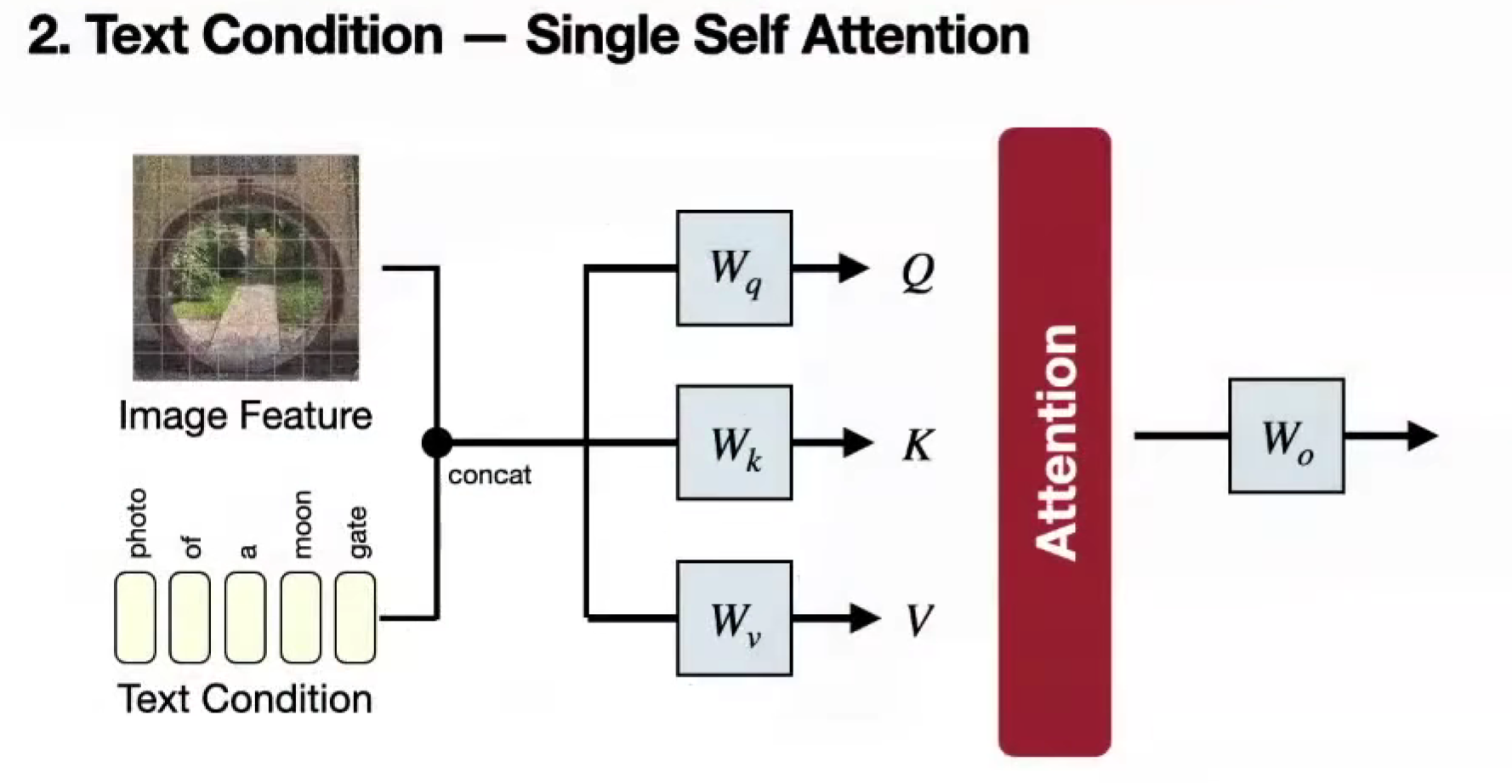
Single Self Attention
Early fusion
Pixel-wise condition
Control Net
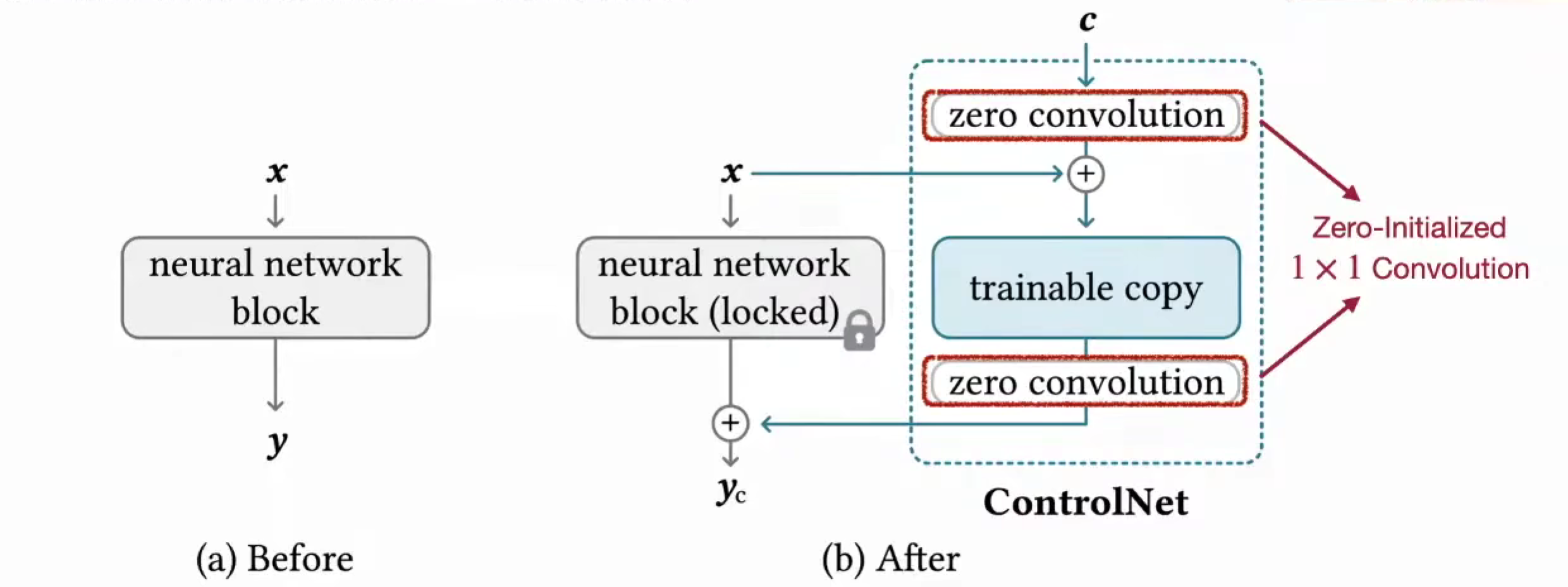
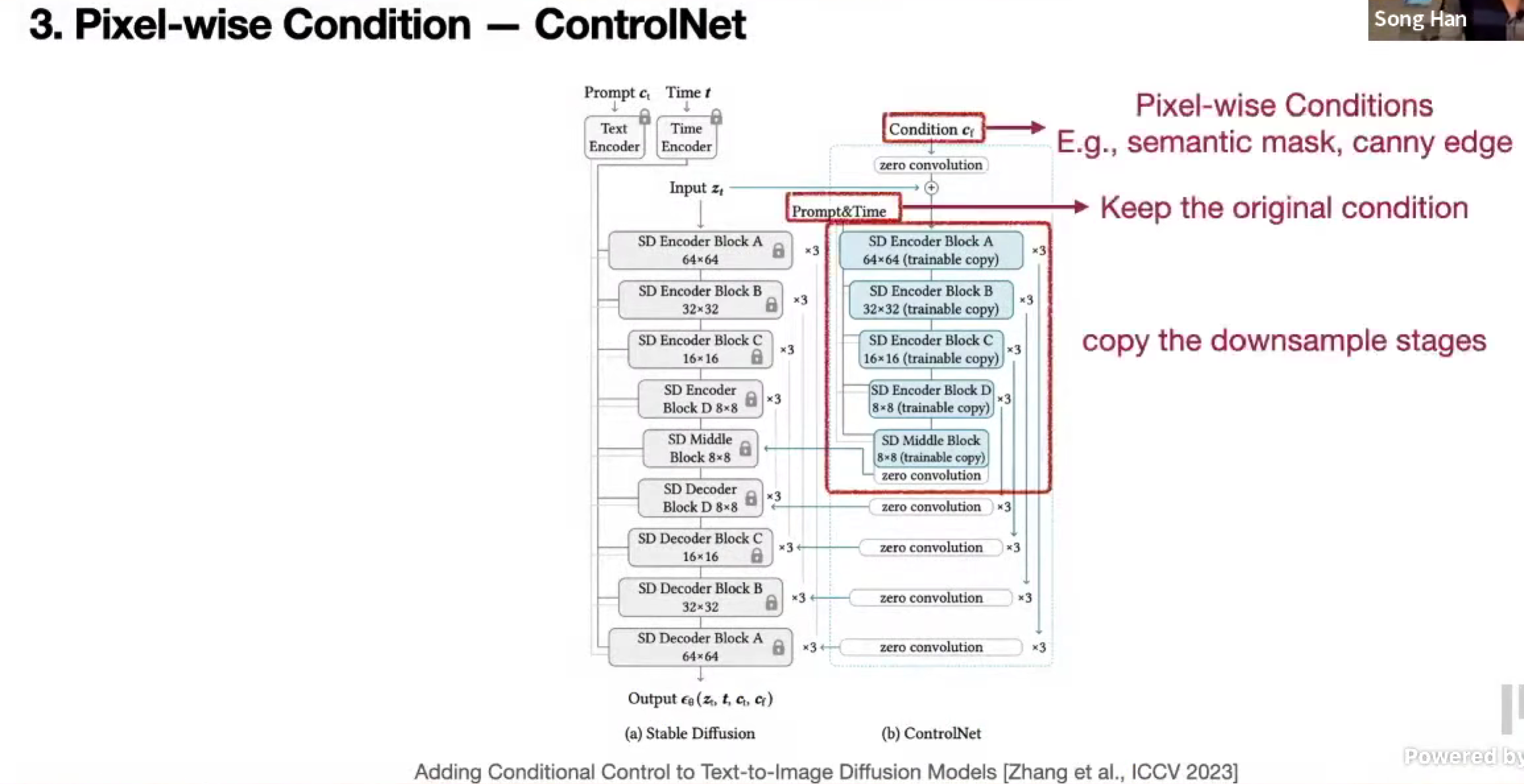
关于多样性和质量,增加 c 的分类器,强度
classifier-free guidance

Latent diffusion models
较少计算量
预训练 VAE,编码到潜空间 diffusion,最后再解码
学习目标是一样的,预测噪音
采样也是类似
分辨率压缩的越多,运行的越快
Deep Compression Autoencoder (DC-AE) f64
压缩 64 倍,考虑 Attention 平方,减少的计算有 4k 倍
具体地,通过显式 space-to-channel / channel-to-space,残差自编码,使得更加稳定
因为自编码器要的计算量变大,为了减少计算量,使用分层稀疏调优的方式,减少计算量
还有 Linear Attention,使用小 LLM 作为文本编码器,kernel fusion,flow based PPM 求解器
Image editing
Stroke-Base Editing
通过增加噪声,使得草图和图像接近,然后解出来(具体训练是怎么样的?)
SDEdit
Model personalization
人物一致性
DreamBooth,通过 finetune,用特别的标识符来代表这个类别
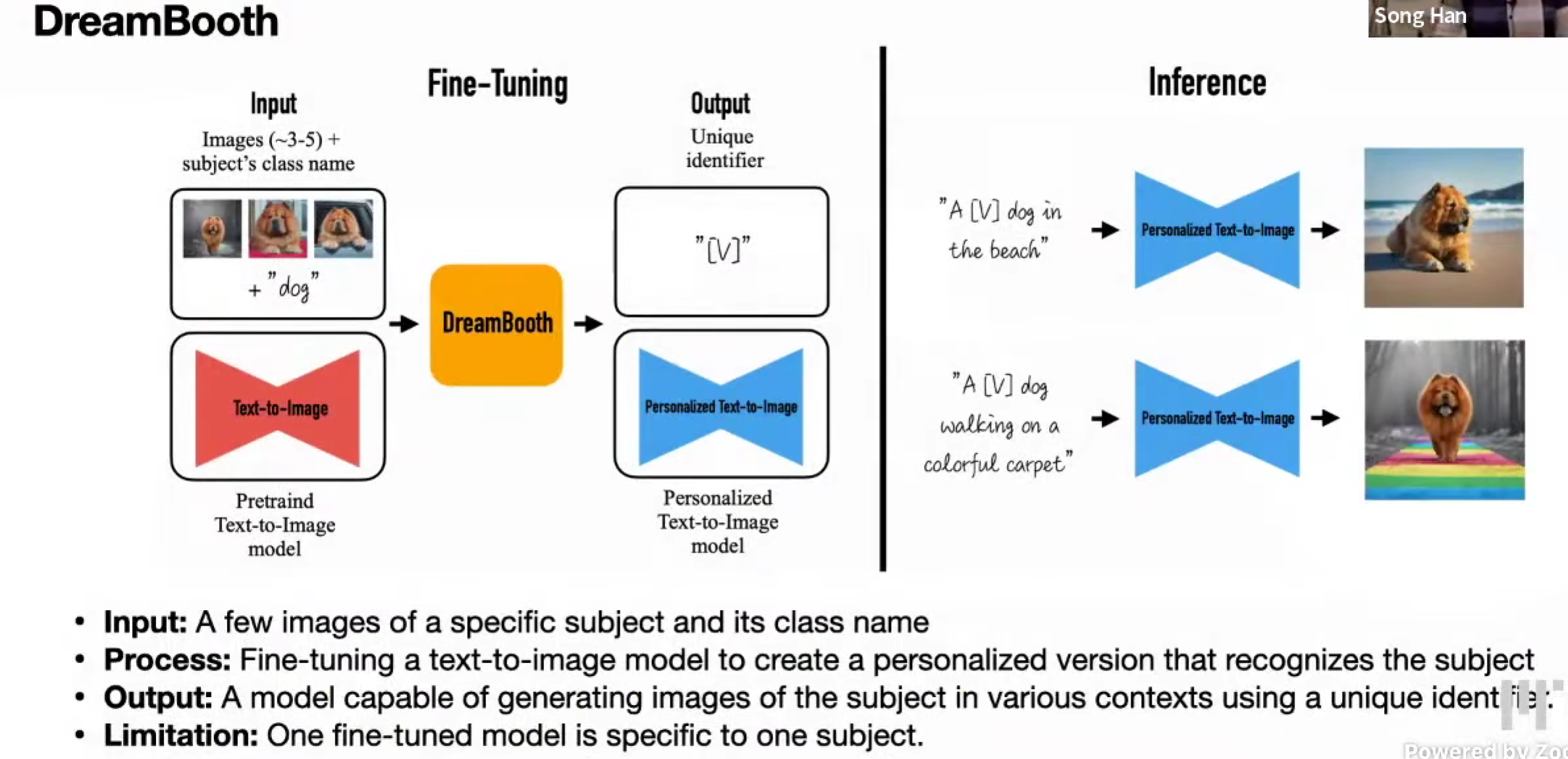
但是,只能对每一个新的类别都需要去finetune,costly
后续也有 training-free 的技术
Fast sampling techniques
能否增大步幅,减少步骤
Denoising diffusion implicit models
之前的马尔可夫Markovian 只依赖前一个步骤,增加和 x0 的关系

Distillation
渐进蒸馏,教师模型一步一步,学生模型从教师模型的两步里面蒸馏学习成一步,然后渐进蒸馏,就可以减少步数

Acceleration techniques
Sparsity
编辑只编辑了一些,但需要对所有像素进行运算
SDEdit,只重新计算改变的部分,别的部分复用
Sparse Incremental Generative Engine (SIGE)
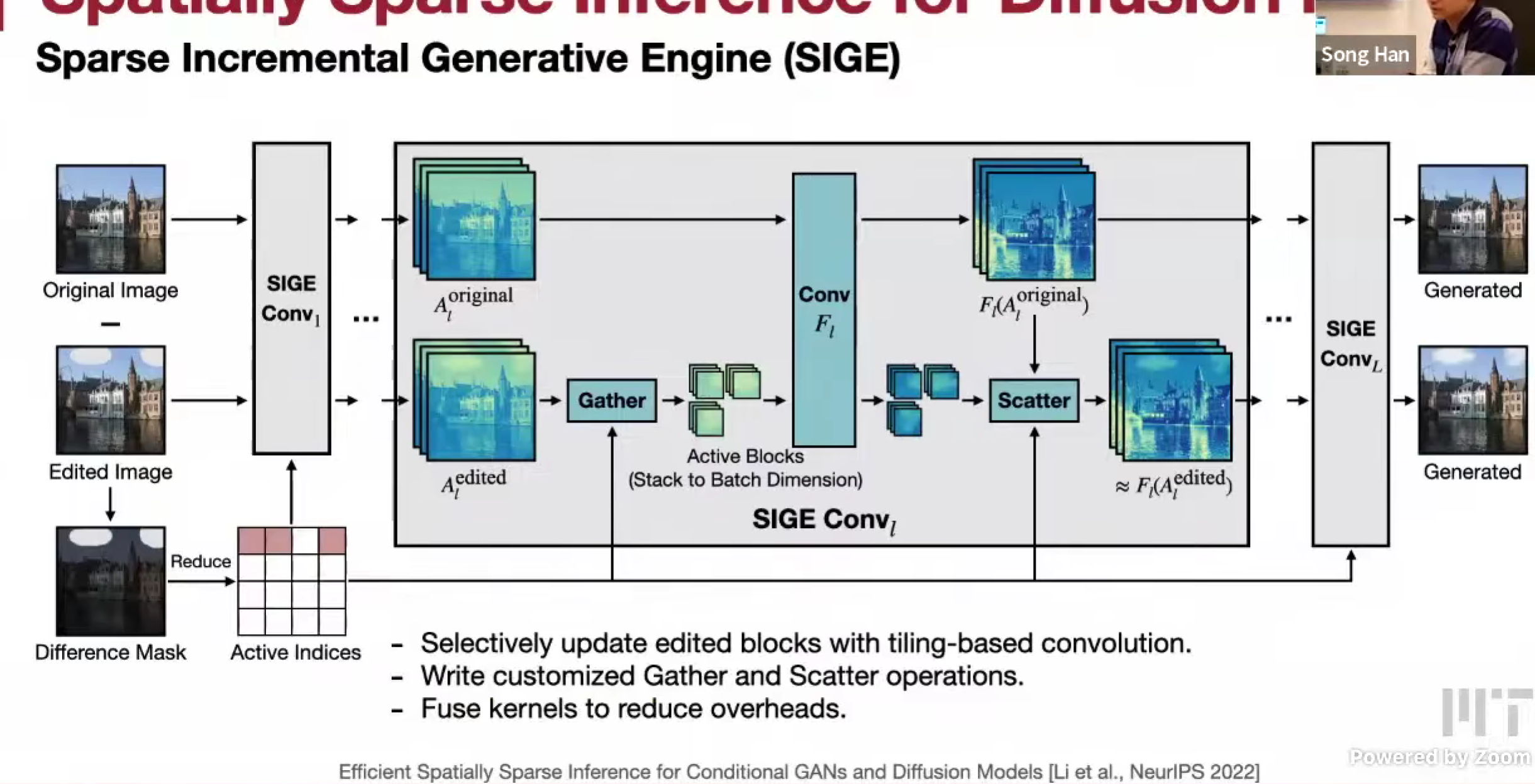
Image Inpainting,类似,同时可以实现交互式
Quantization
SVDQuant
和 LLM 不同,Diffusion Model 是compute-bound,所以 weight-only quantization 没办法加速扩散模型
使用类似 SmoothQuant 的方式,把激活值的 outlier 转移到权重上,然后权重使用 side (low rank) branch 去全精度保持精度损失,经过 SVD,异常值减少W4A4
同时,如果使用 LoRA funetuning,就不需要重新量化,在原本的全精度上追加秩就行了
简单实现,会带来不小的其他开销,kernel fusion 把旁支的 kernel 合在原本的 kernel 中,由于他们共享输入/输出
Parallelism
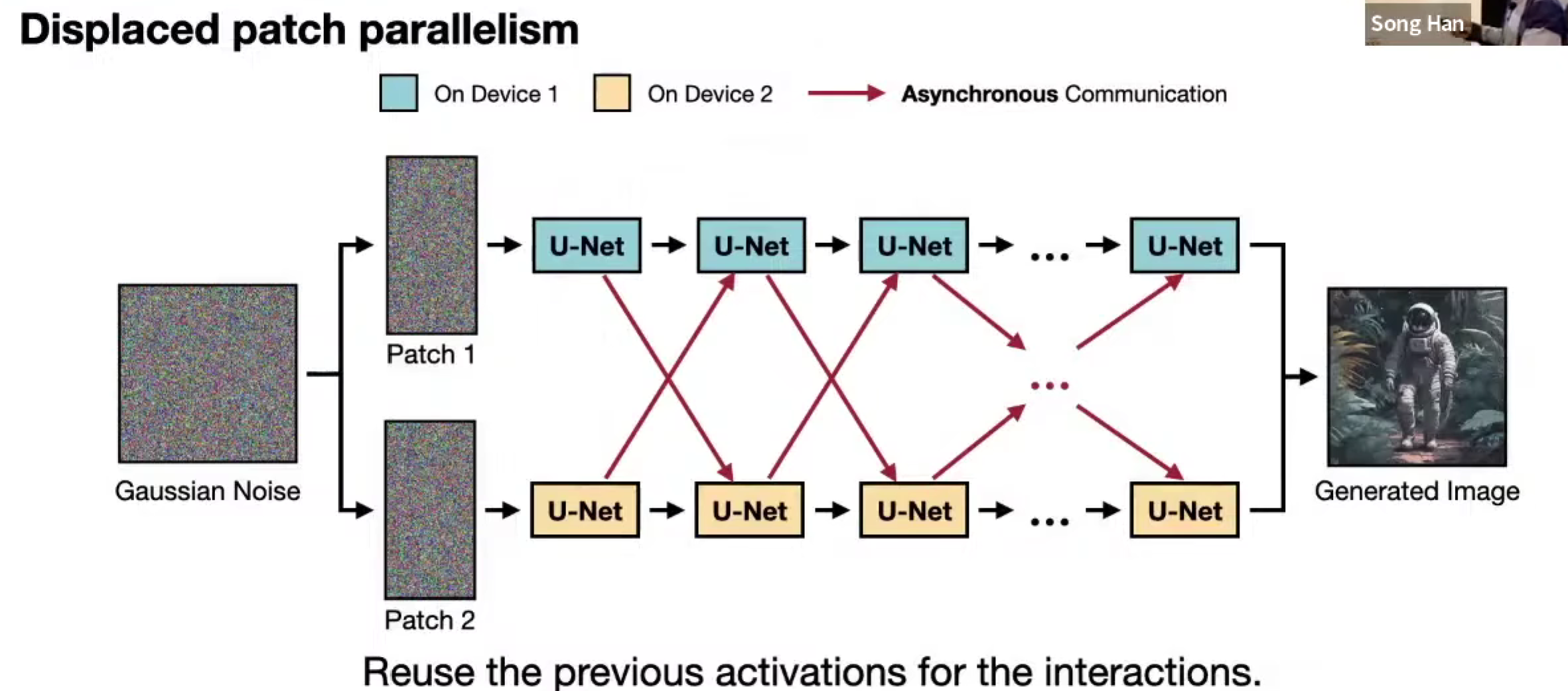
DistriFusion,相邻时间戳的输入实际上很相似,可以通过通信旧的激活值,来 overlap 通信与计算
同时,在更高的分辨率下,加速比更高,因为通信开销更大。
Lec19 Distributed Training 1
Background and motivation
模型大,对于单 GPU 来说训练时间太长,需要多 GPU 协同训练
Parallelization methods for distributed trainging
Data parallelism
拆分数据,多个 GPU 上的模型权重是共享的
partition data, sharing model
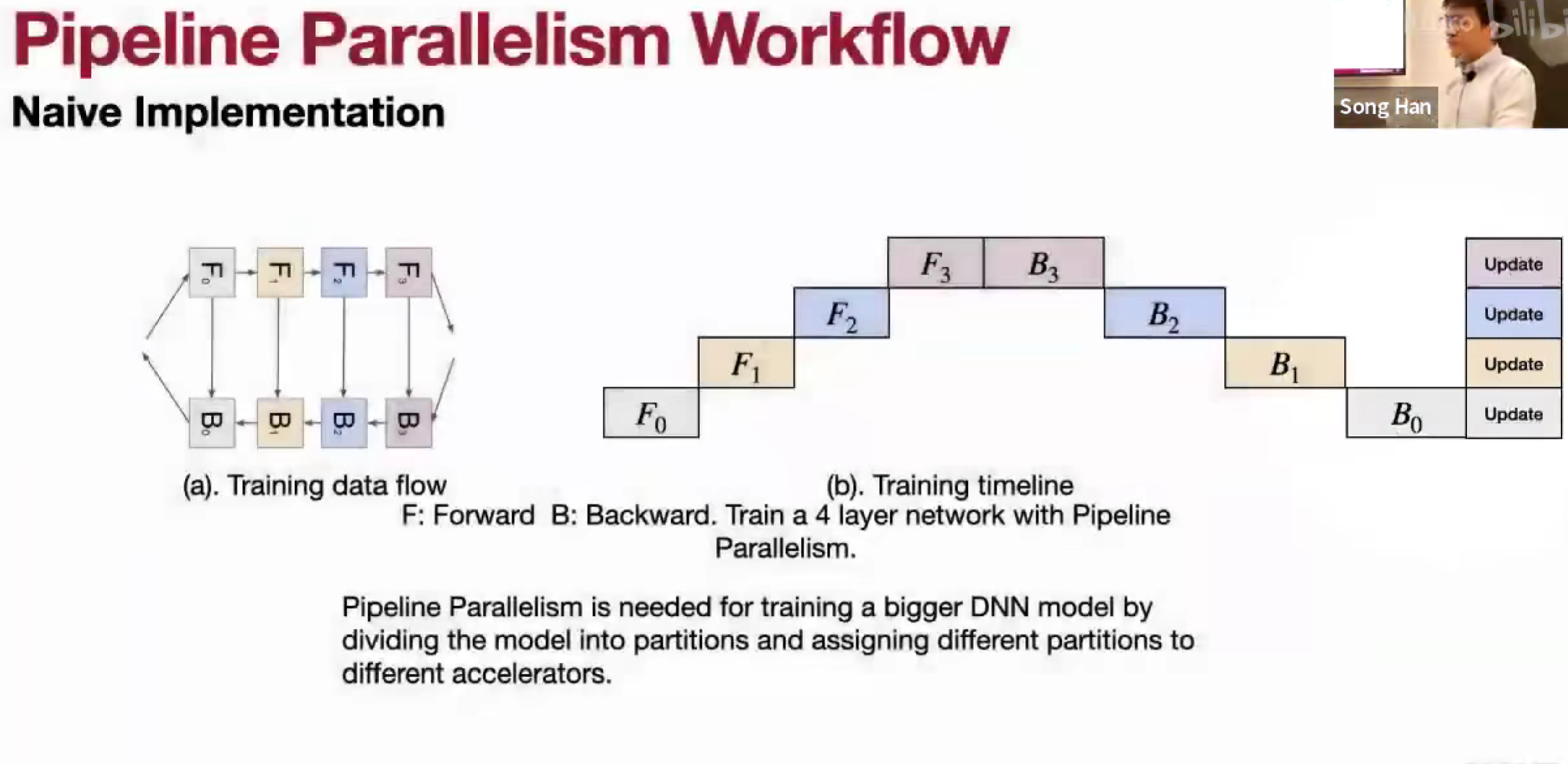
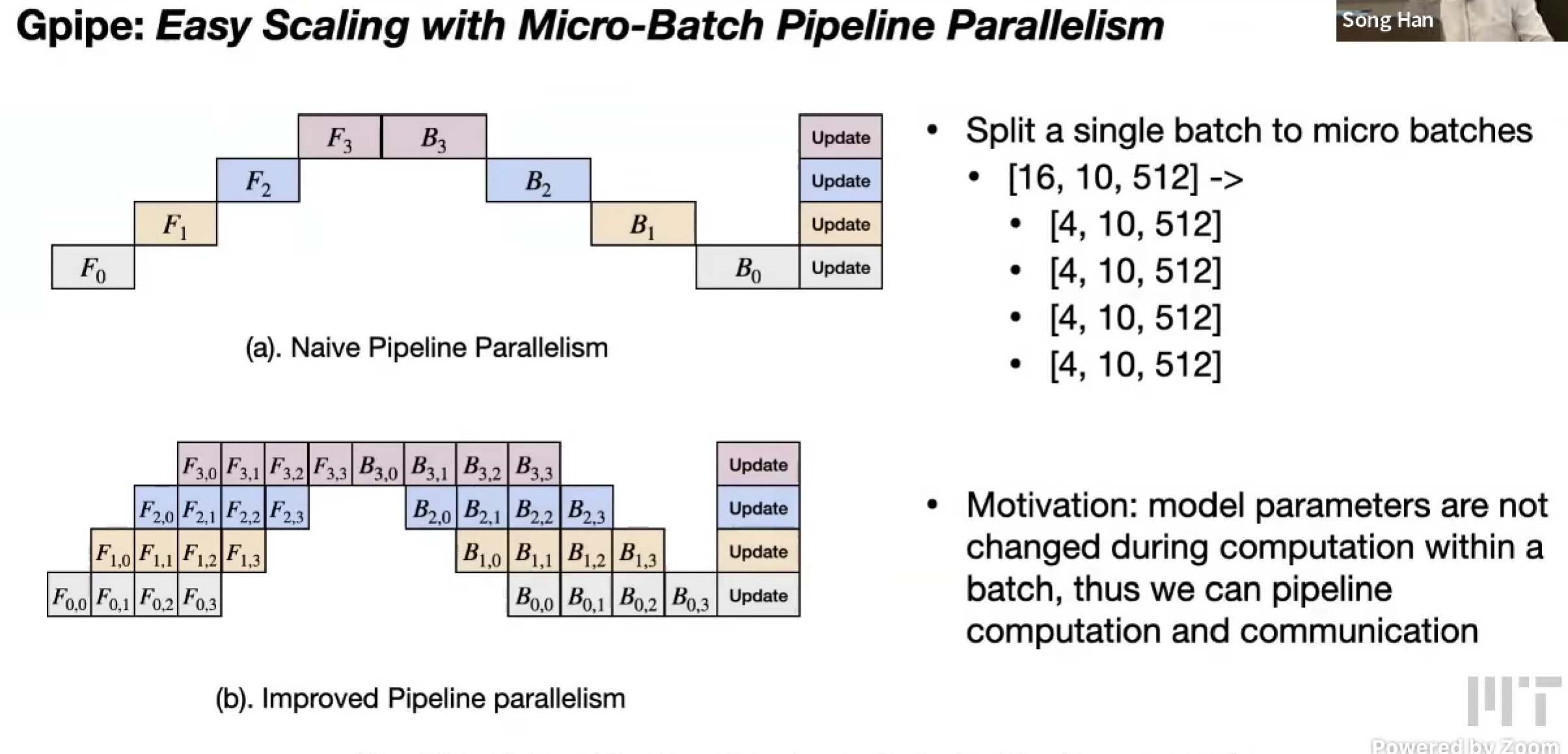
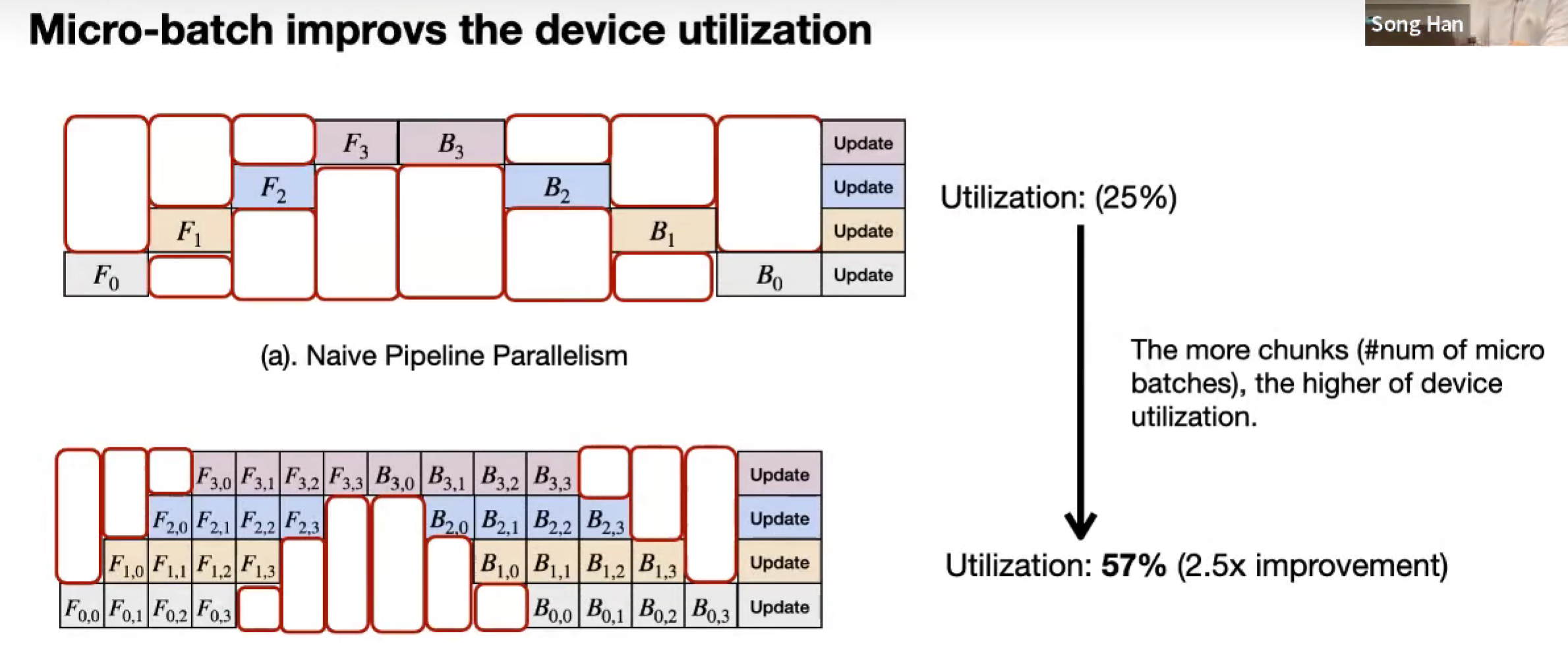
Pipeline Parallelism
拆分模型,一份数据。
按 layer-dimension 划分
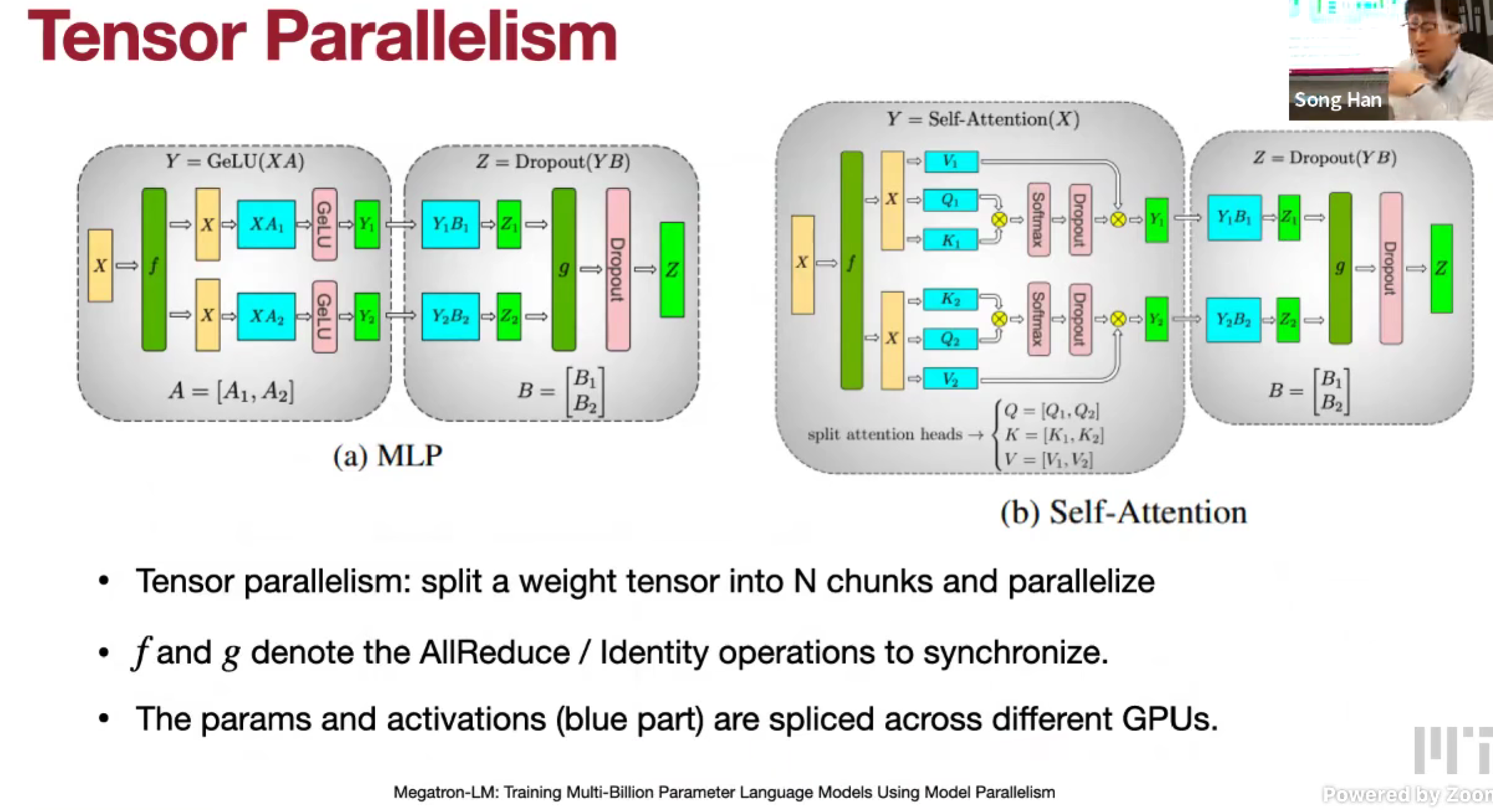
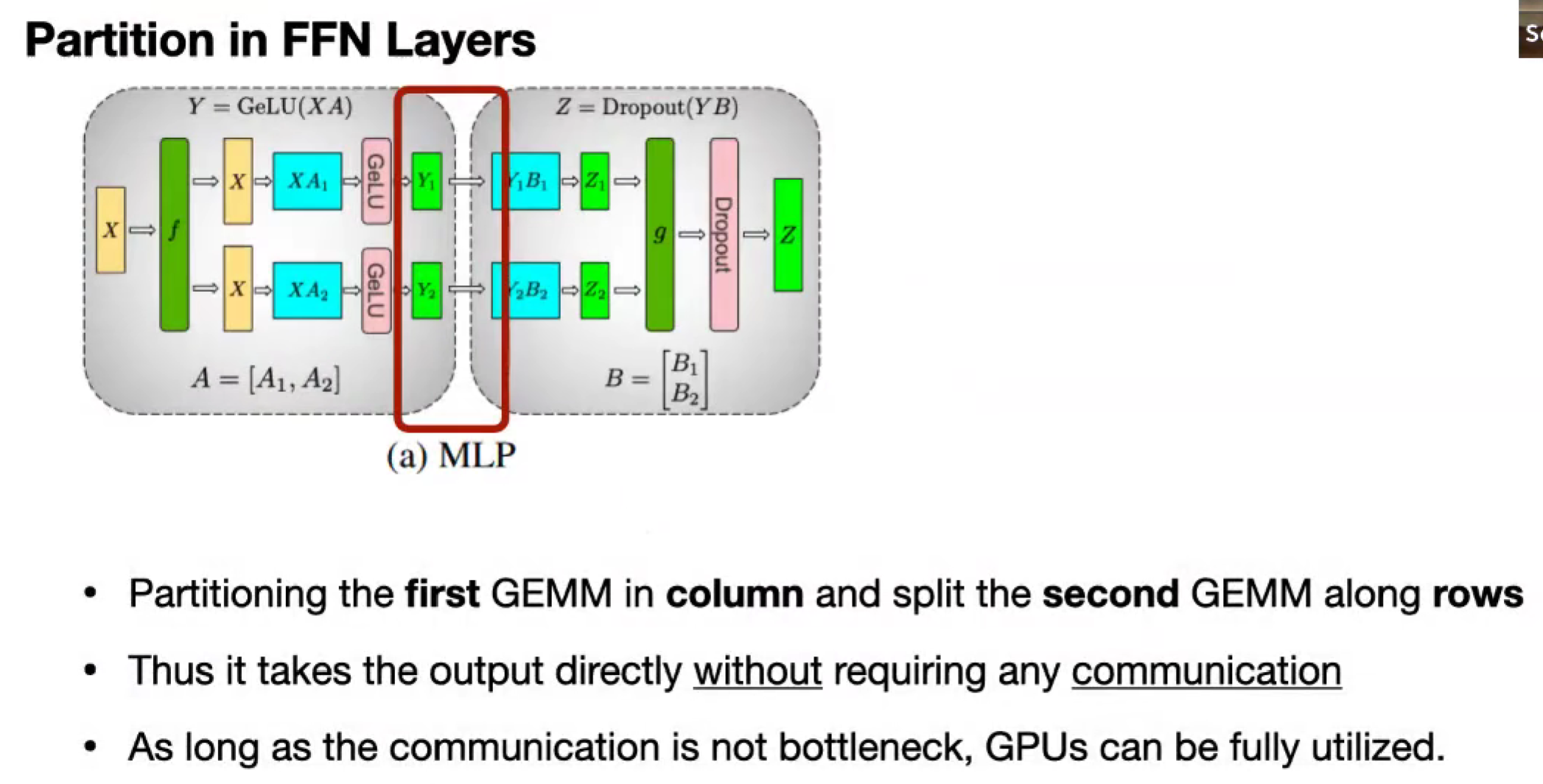
Tensor Parallelism
拆分模型,一份数据。
按 激活值 来划分
Sequence Parallelism
data parallelism 是 batch,sequence parallelism 是 token
Communication primitives
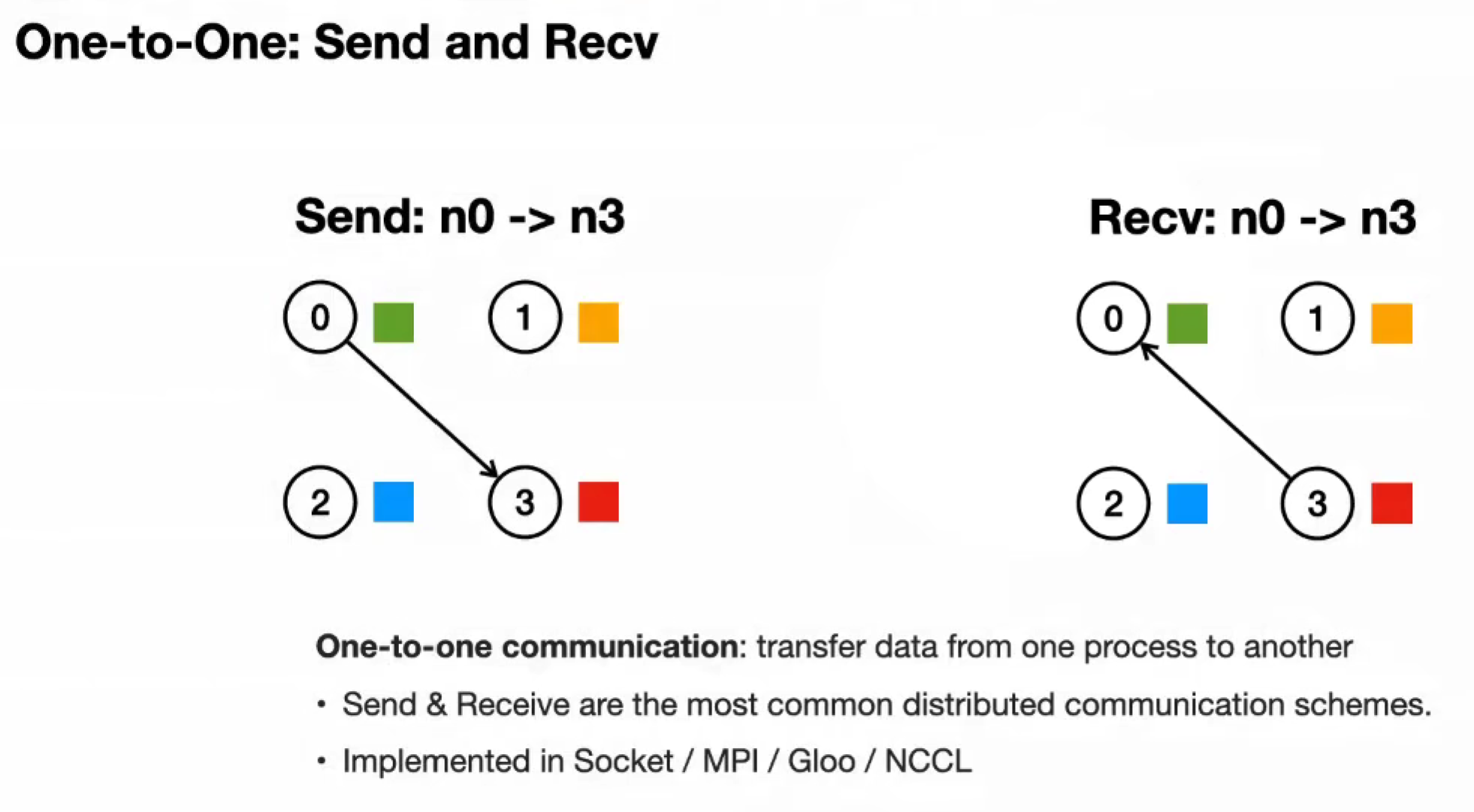
One-to-One: Send and Recv
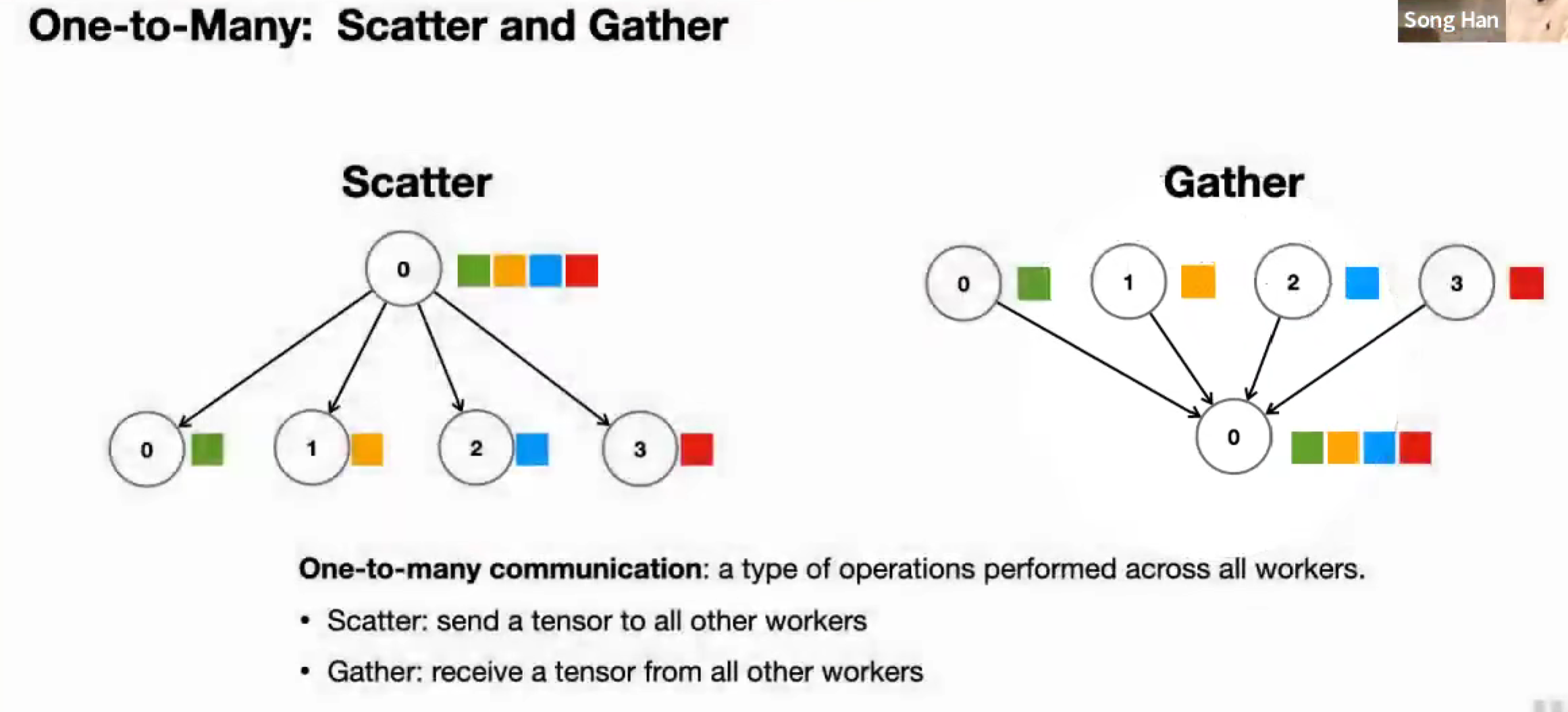
One-to-Many and Many-to-One: Scatter and Gather
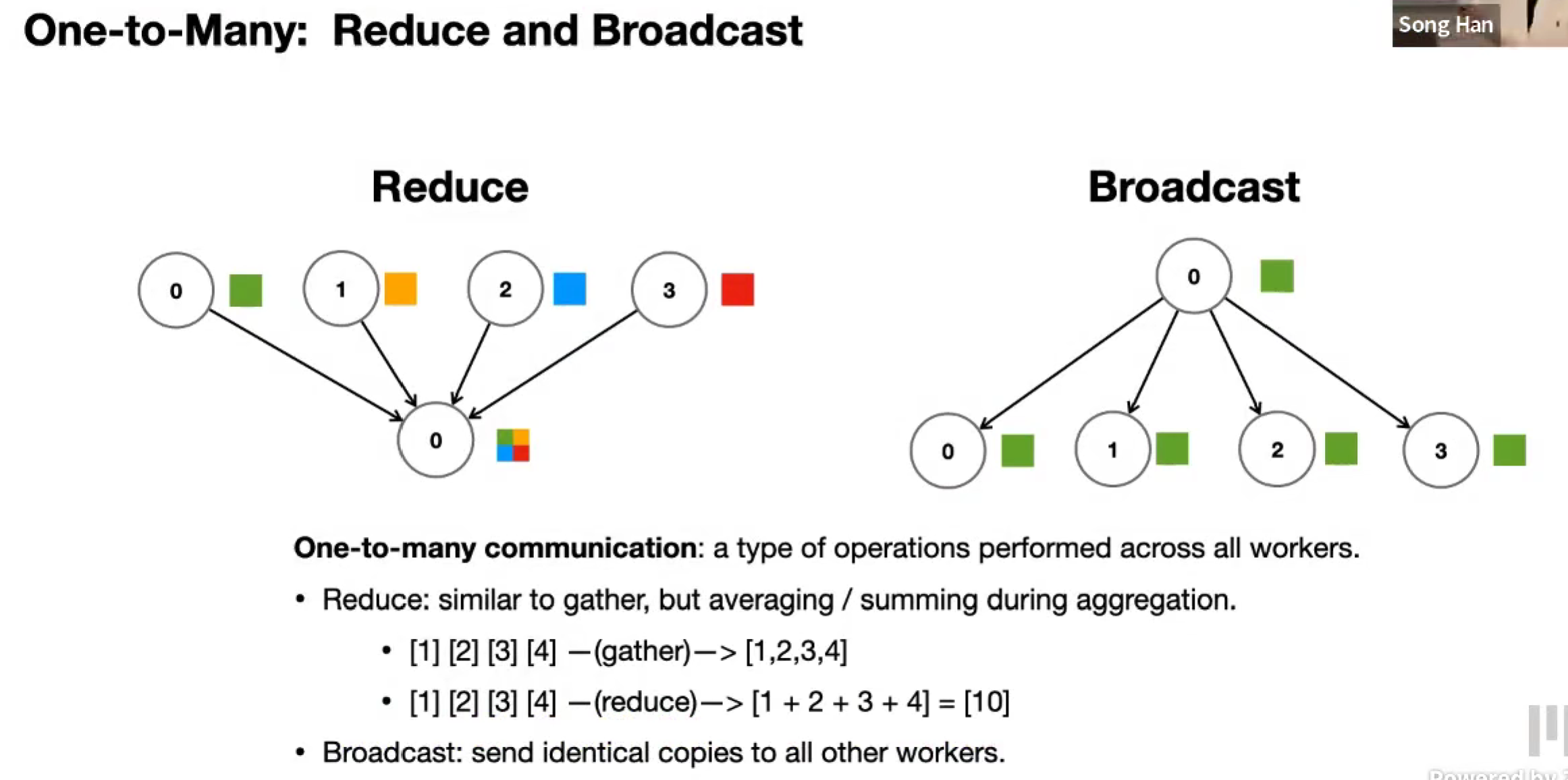
Many-to-One and One-to-Many: Reduce and Broadcast
Reduce 可以看作是 Gather + Reduce 归约操作
Broadcast 是把张量的全部都分发给所有节点,Scatter 是把不同部分分发给不同节点
Many-to-Many: All-Reduce and All-Gather
All-Reduce 对所有 workers 做 Reduce
All-Gather 对所有 workers 做 Gather
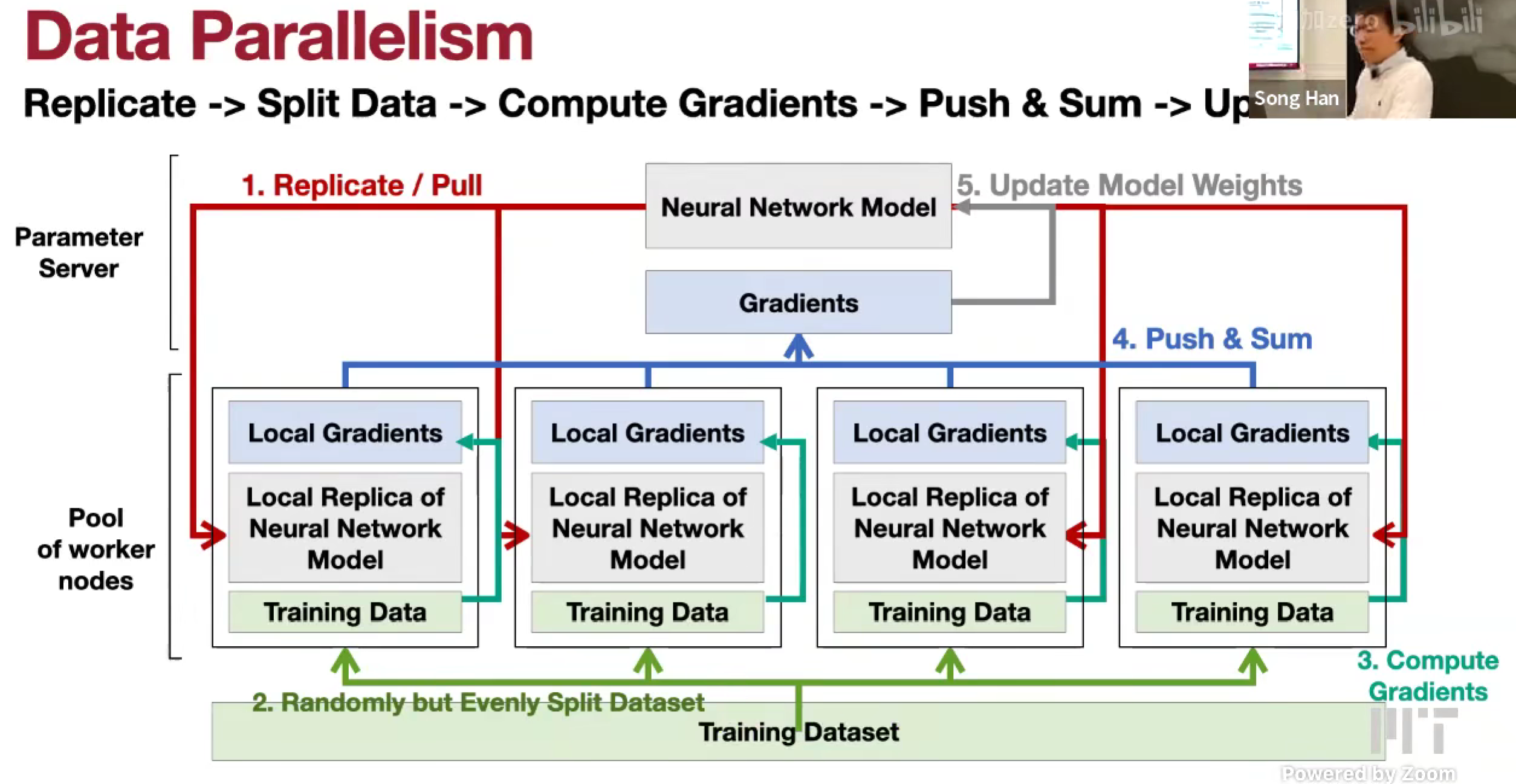
Data Parallelism
Parameter Server
中心化
- Workers pull model from Server
- Workers push & sum to Server gradient
- Server update model using gradient
- Workers replicate / pull the updated model to update local copy
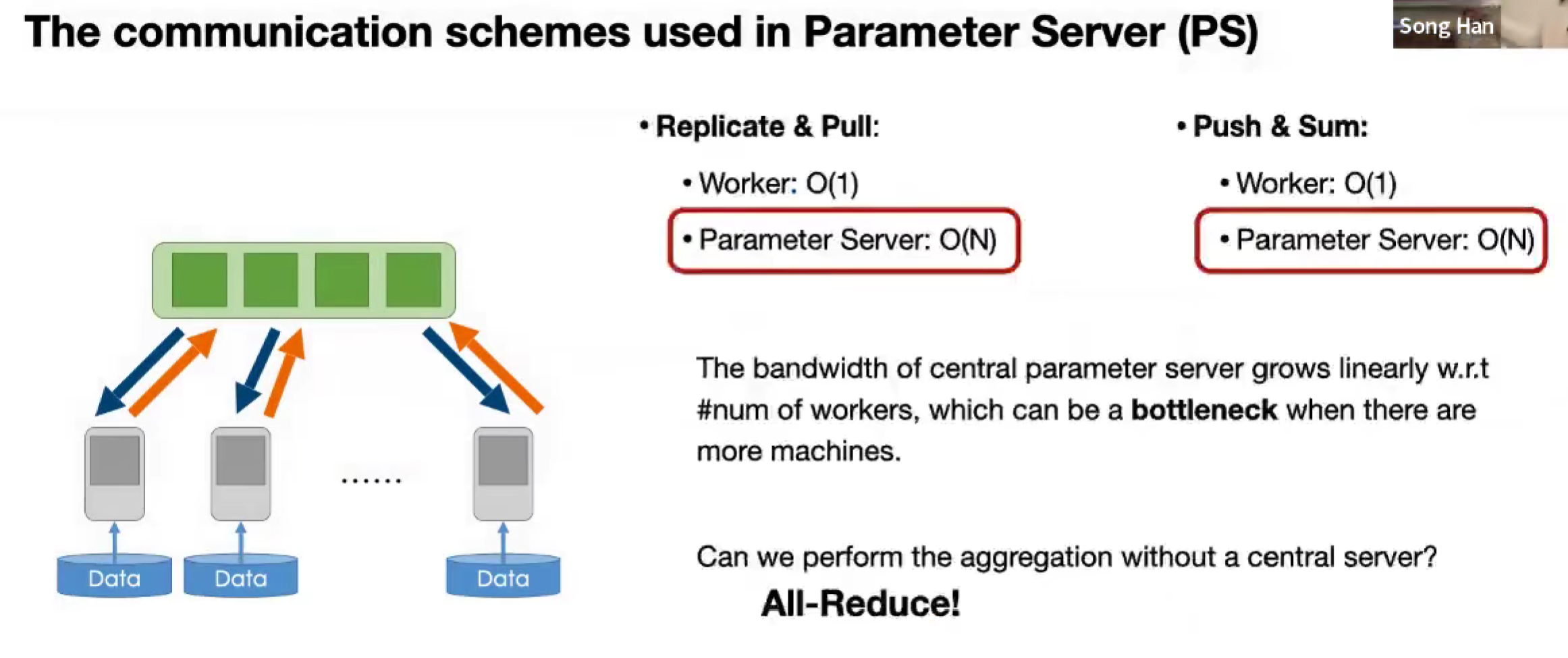
去中心化的方法
Naive All-Reduce, Sequential
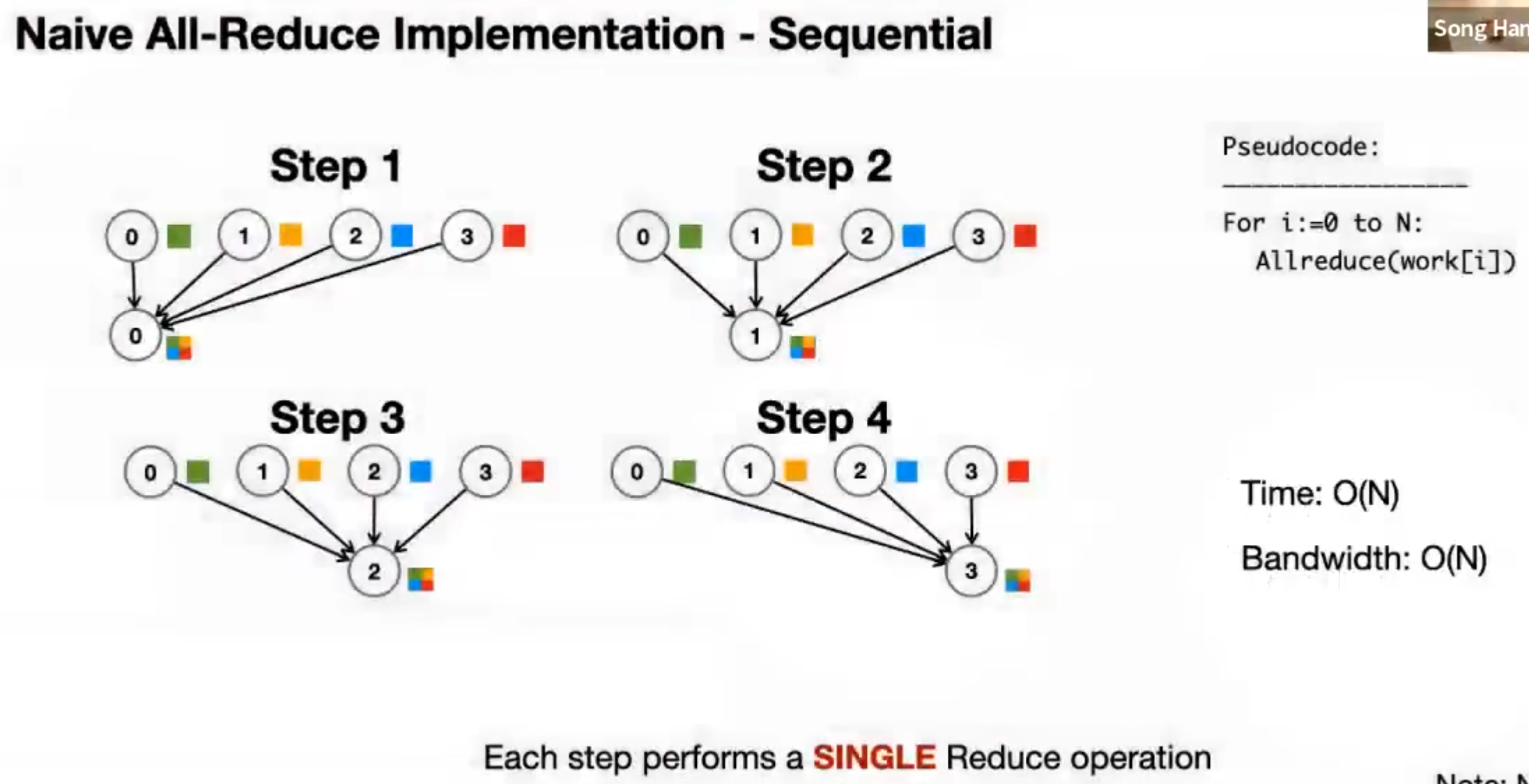
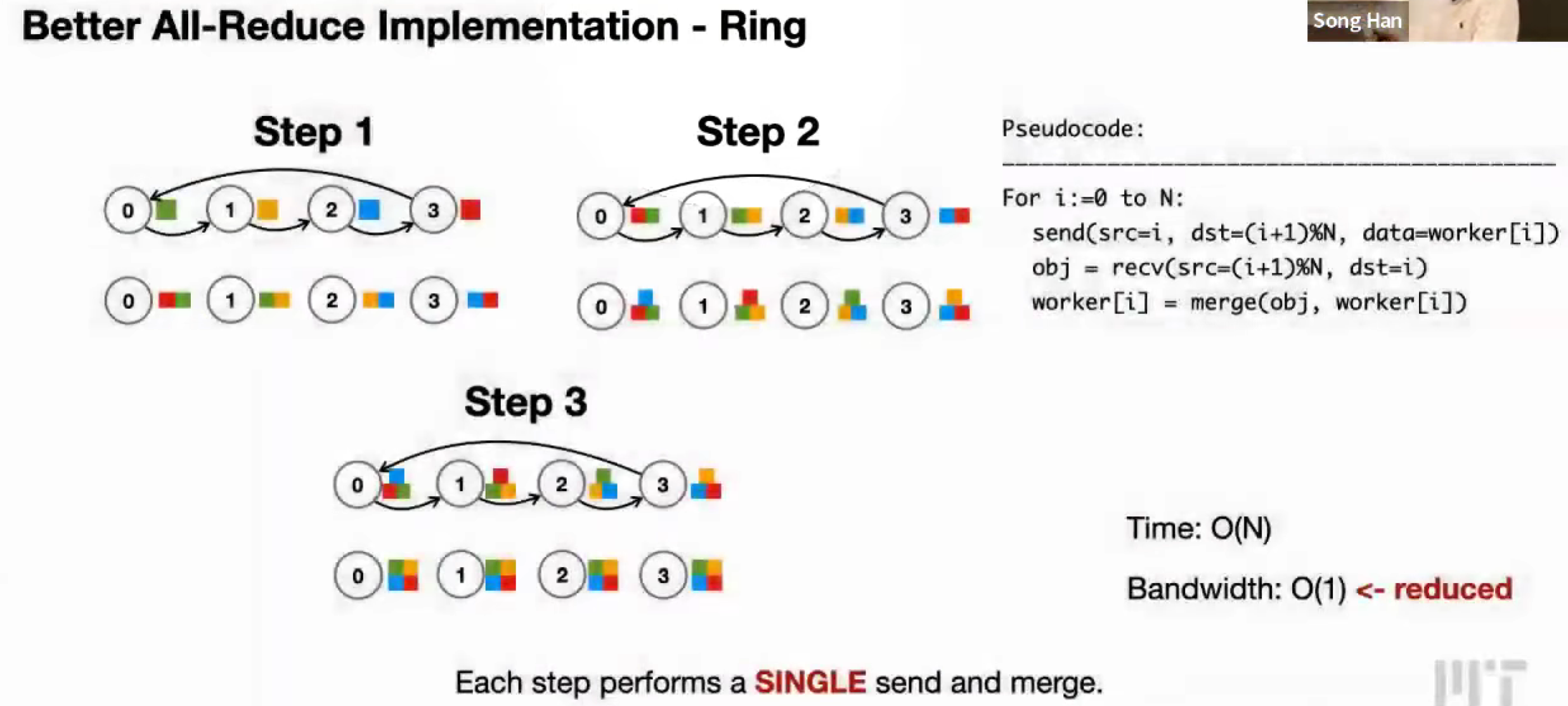
Better All-Reduce, Ring
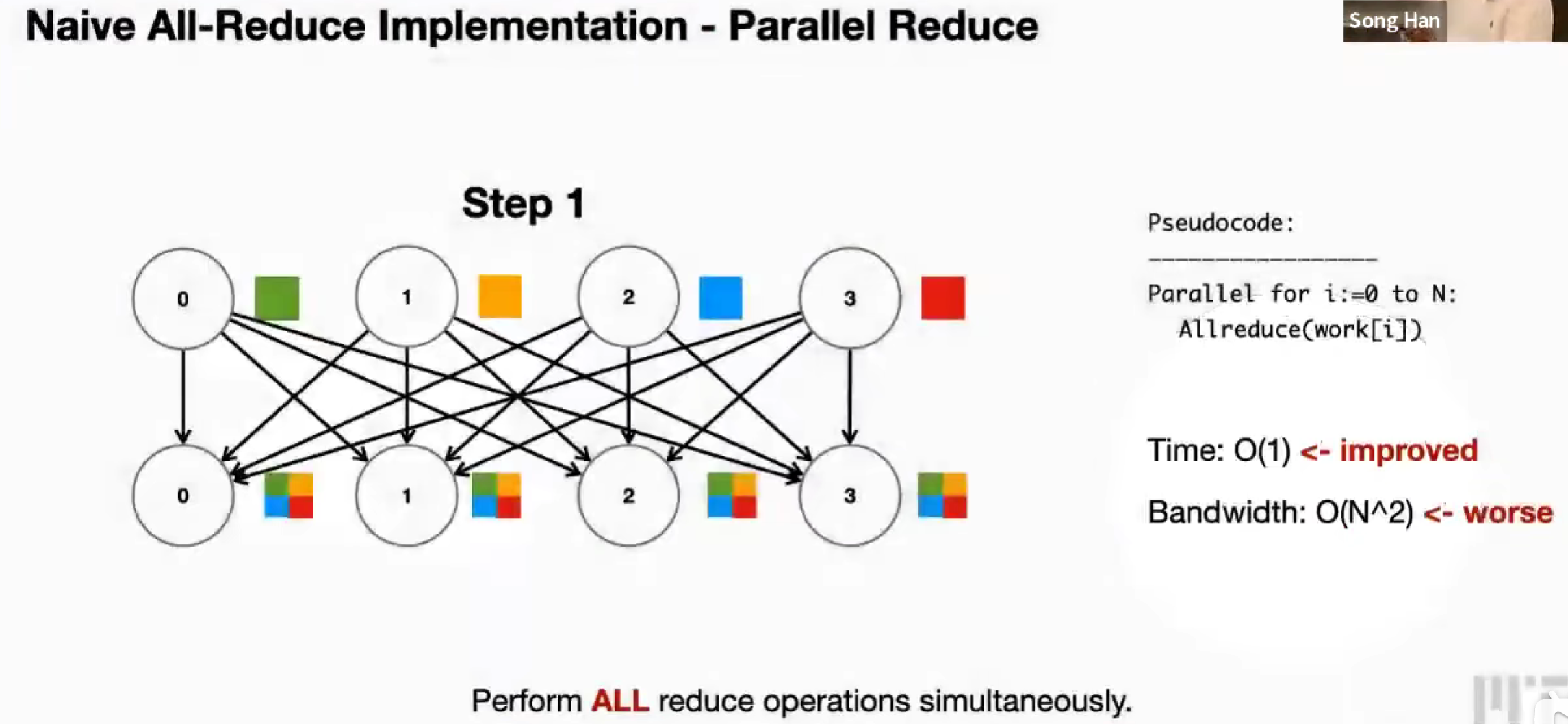
Naive All-Reduce, Parallel Reduce
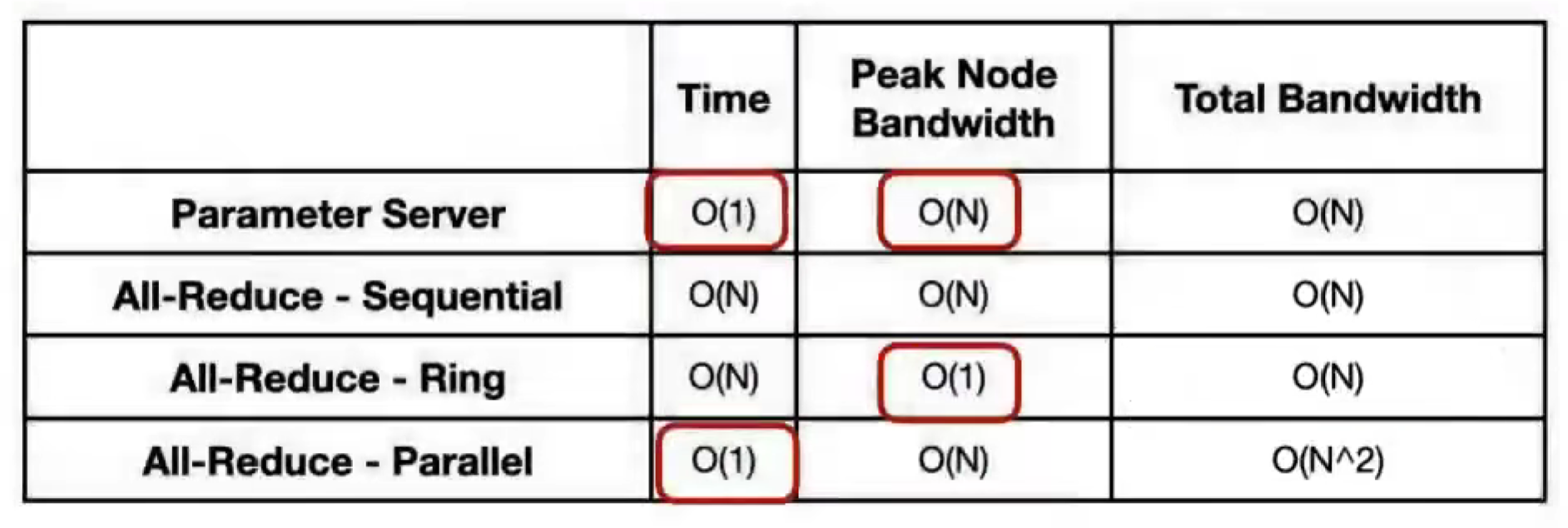
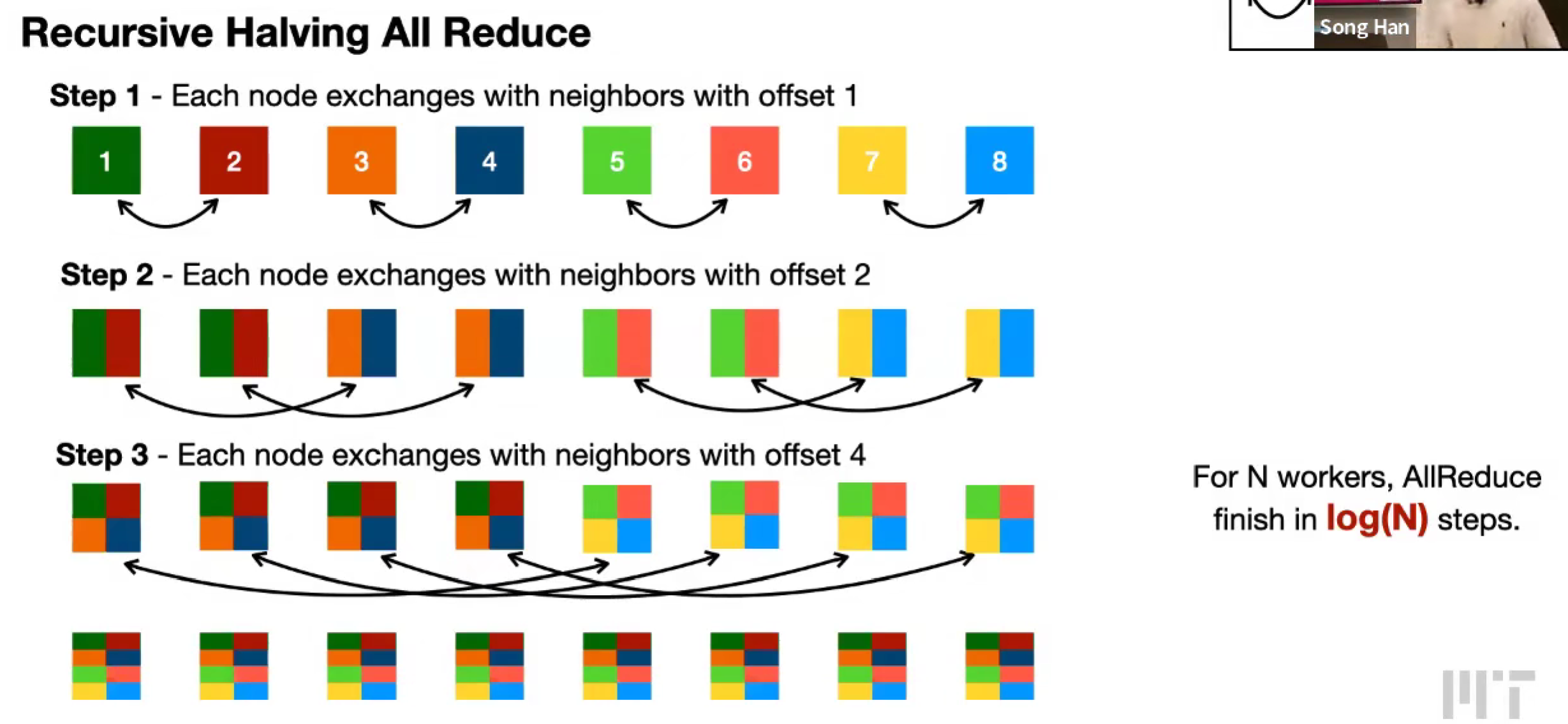
Recursive Halving All Reduce (Butterfly All Reduce)
Reducing memory in data parallelism: Zero-1/2/3 and FSDP

Pipeline parallelism
Tensor parallelism
从 d_dim 维度切,垂直切,再水平切
Scatter and All-Reduce
broadcast activation
Sequence parallelism
处理长下文
比如把一本书的不同章节分别做,但是注意力不能互相计算,只是局部的话,会缺失上下文。
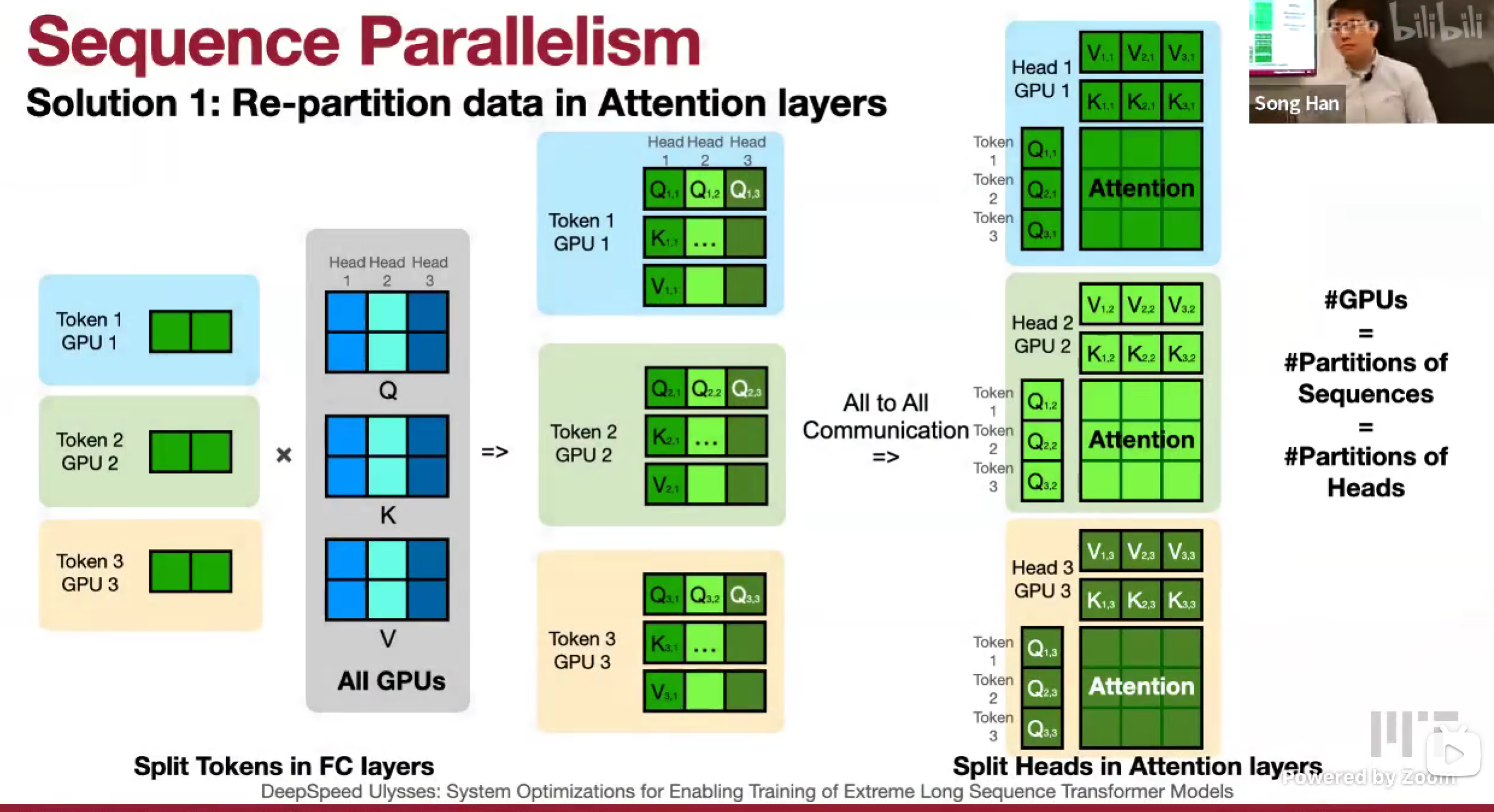
DeepSpeed Ulysses (Solution 1: Re-partition data in Attention layers)
All-to-All 全对全通信开销大,节点之间通信成本高;
最大并行度?会受到模型的多头注意力的头的个数
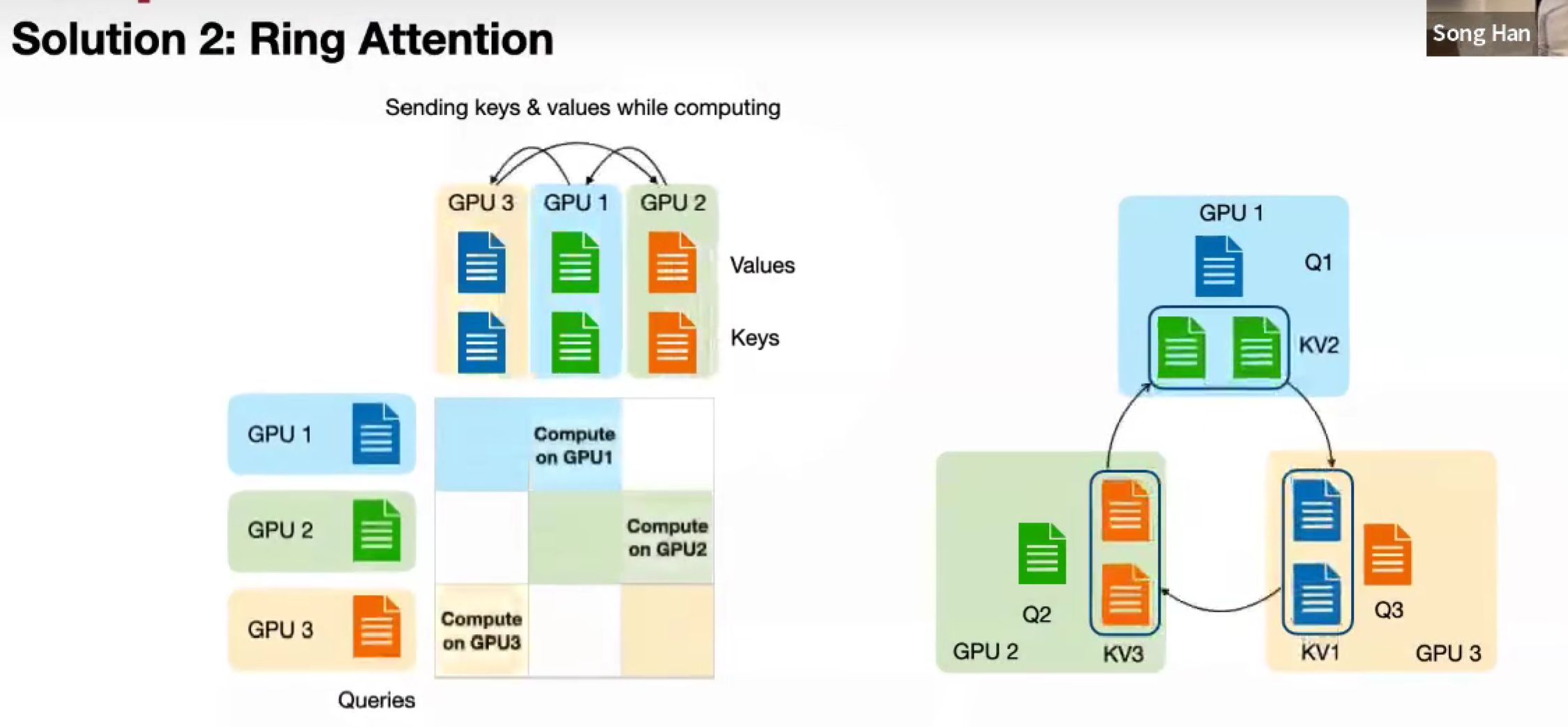
Ring Attention(Solution 2: Ring Attention)
交换 KV1 KV2 KV3
并行度不再受 head_num 限制
Longvilla,结合这两种方法,在一个节点中,用 Ulysses,节点之间用 Ring Attention。
(节点内部通信高)
Lec20 Distributed Training 2
Hybrid (mixed) parallelism and how to auto-parallelize
2D Parallelism
Outer: DP
Inner: PP
Outer: PP
Inner: TP
Intra-node: all-to-all repartition
Inter-node: ring attention
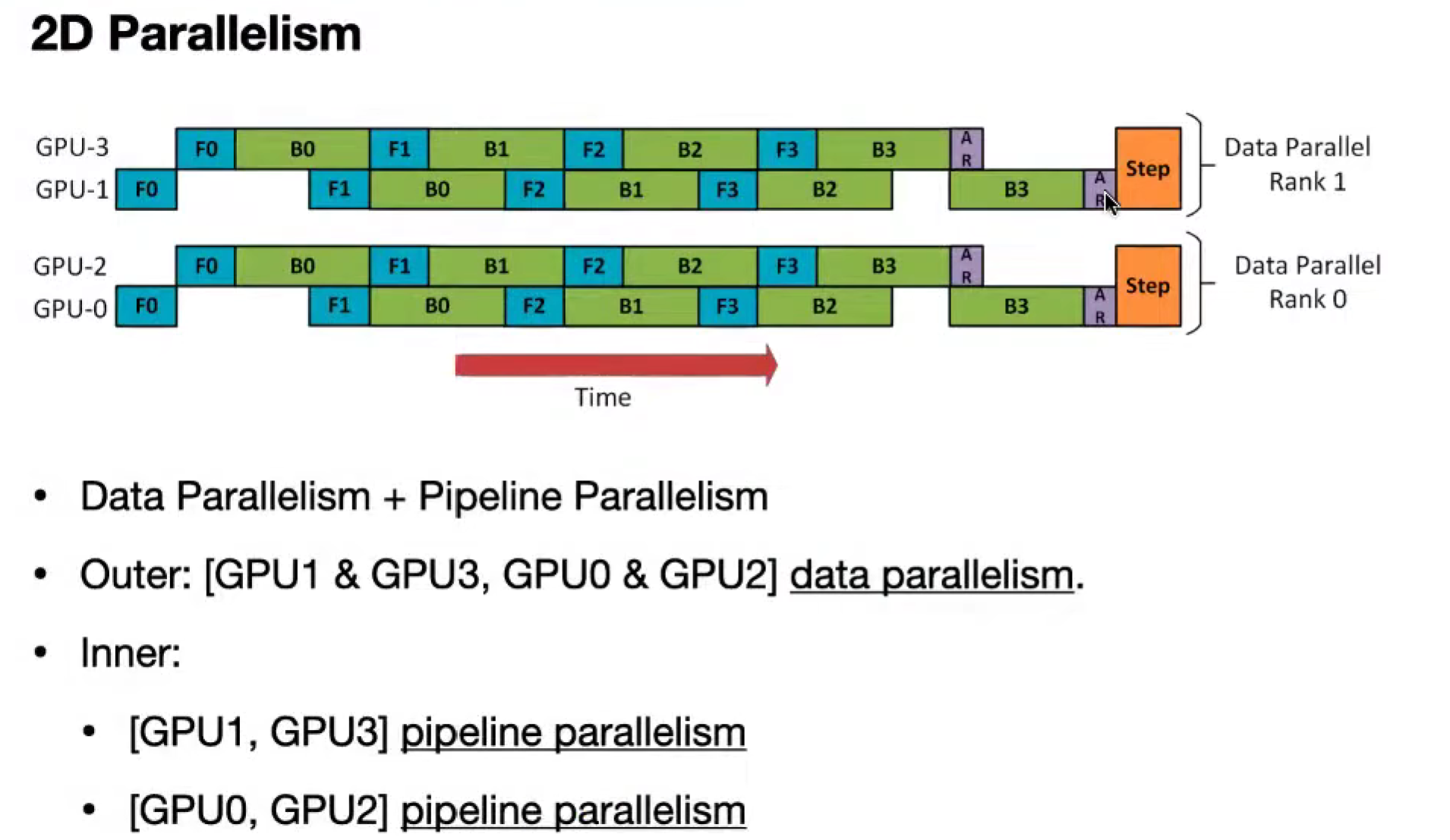
3D Parallelism
- PP + TP + DP
How to Auto Parallelize
模型太大,不能放单机;PP
模型层太大,不能方单机;TP
Alpa: A Unified Compiler for Distributed Training
搜索空间大,分层搜索空间 Hierarchical Space。
Inter-op Parallelism
Intra-op Parallelism
Cost,计算成本、通信成本、数据重分布成本
(那还有说法吗?这个设计)
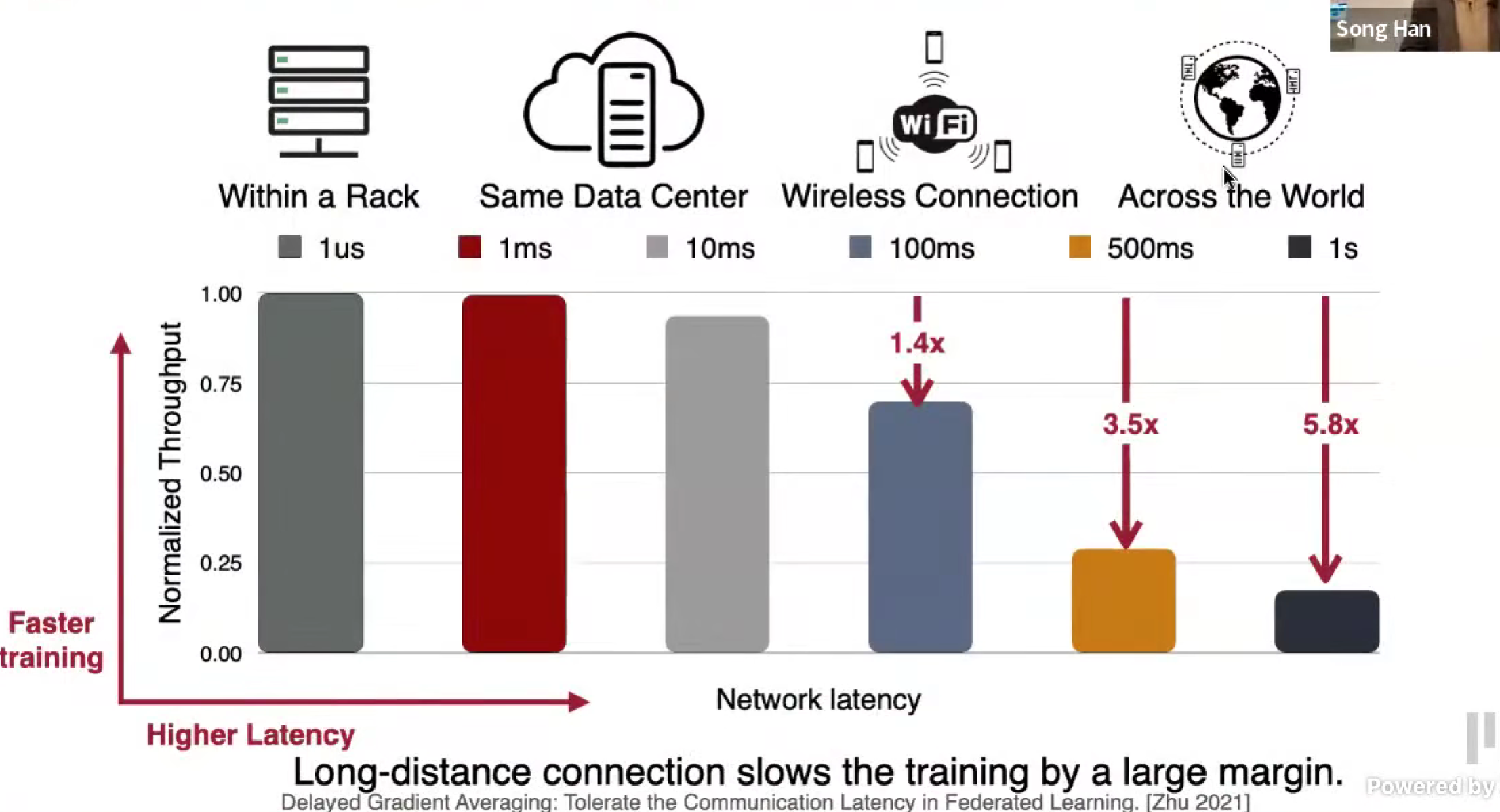
Understand the bandwidth and latency bottleneck of distributed training
通信很重要。

估算延迟
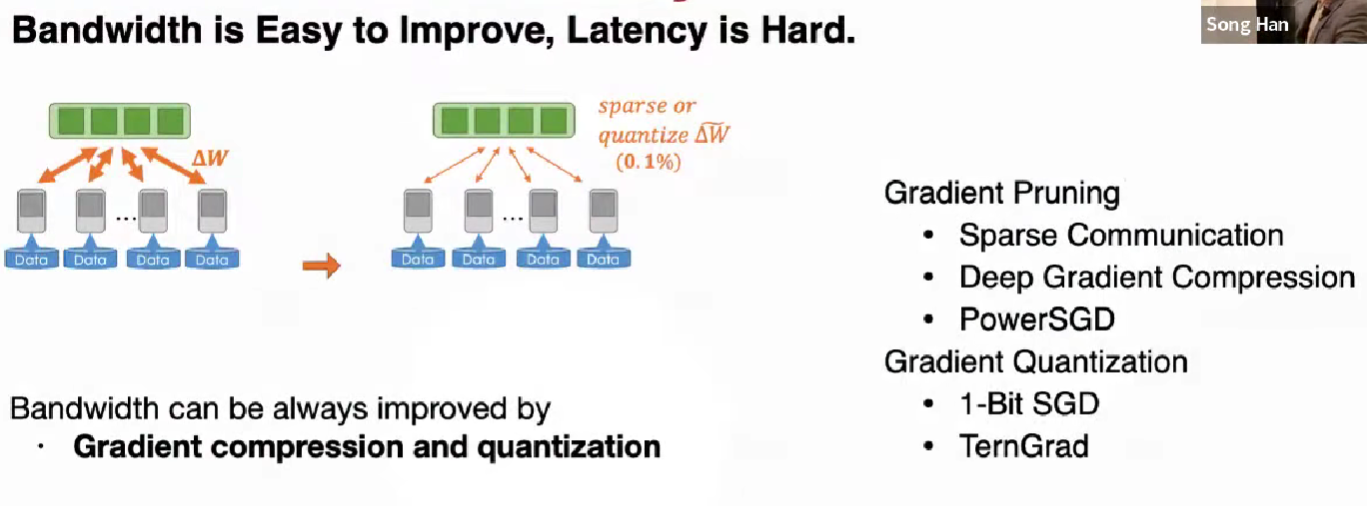
Gradient compression: overcome the bandwidth bottleneck
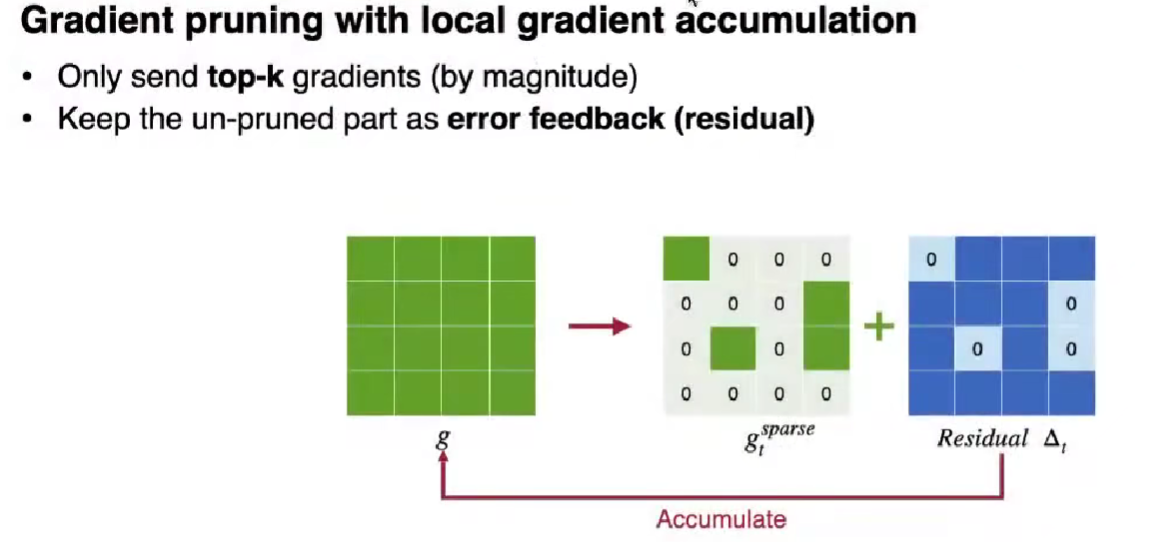
Gradient Prunning
Sparse Communication 稀疏通信
结合局部梯度累积的梯度剪枝
只 send top-k 梯度 by magnitude
保持未 send(没有到 top-k 的)作为 error feedback (residual)
保留残差,直到累积到阈值 (梯度裁切)
导致性能下降。
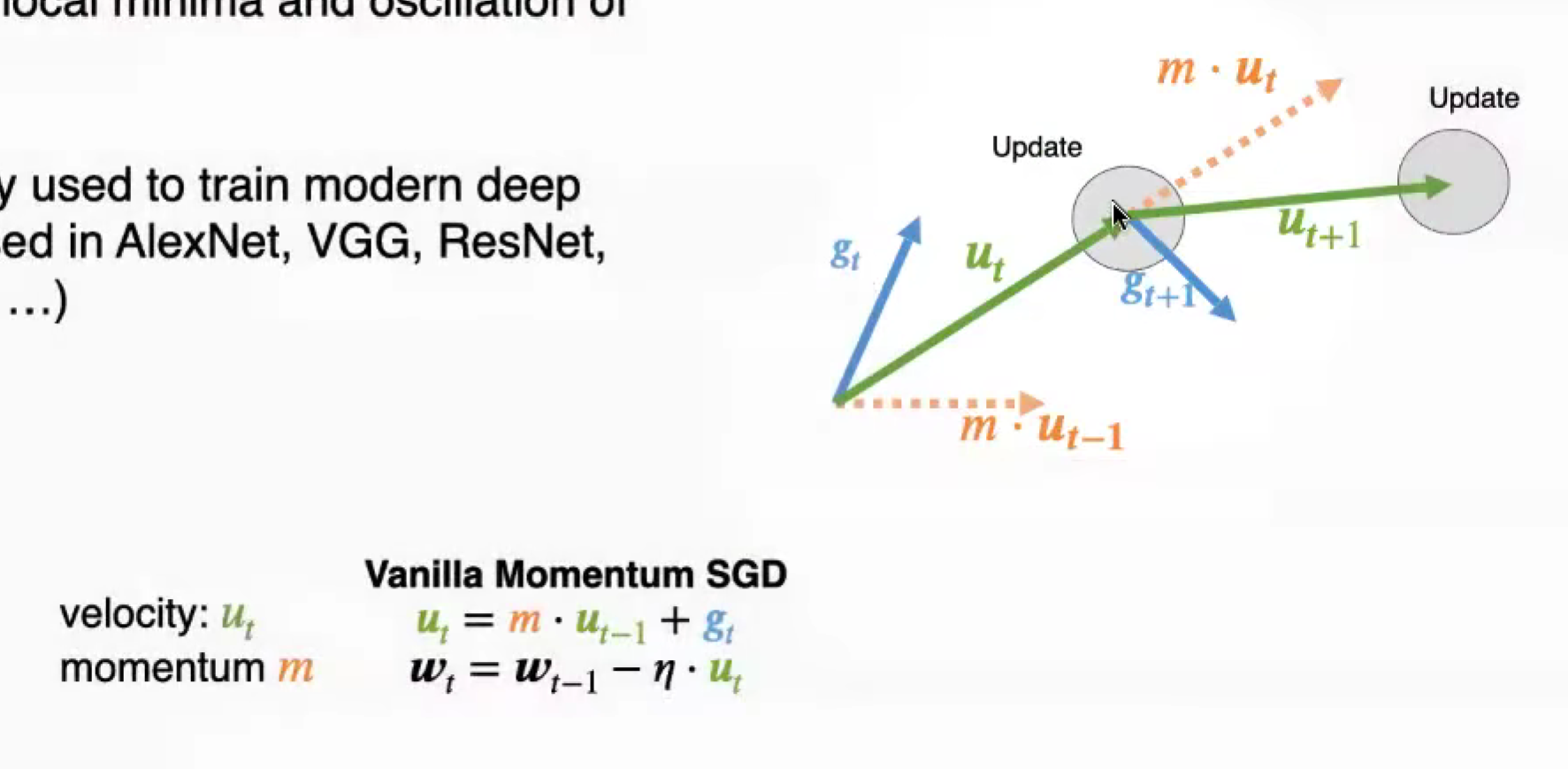
Momentum 动量机制
直接累积梯度,会导致优化方向的偏移
应该累积速度,而非梯度

Deep Gradient Compression
warm up training
在训练早期,权重改变大;warm up learning rate
累积梯度会加剧问题;warm up sparsity
指数逐渐增大,保持稳定。
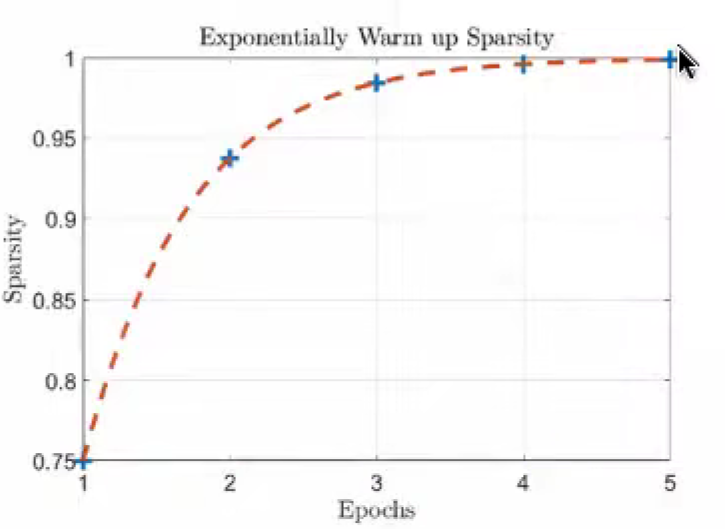
梯度压缩比可以到很高,99.9%,没有1000x?索引开销、bias 偏置没有剪枝,偏置对残差训练很重要。
PowerSGD: Low-Rank Gradient Compression
问题:稀疏梯度,在 all-reduce 环节会变得越来密集
采用固定稀疏模式,粗粒度稀疏。
用低秩分解,来固定稀疏模式,粗粒度稀疏。
Gradient Quantization
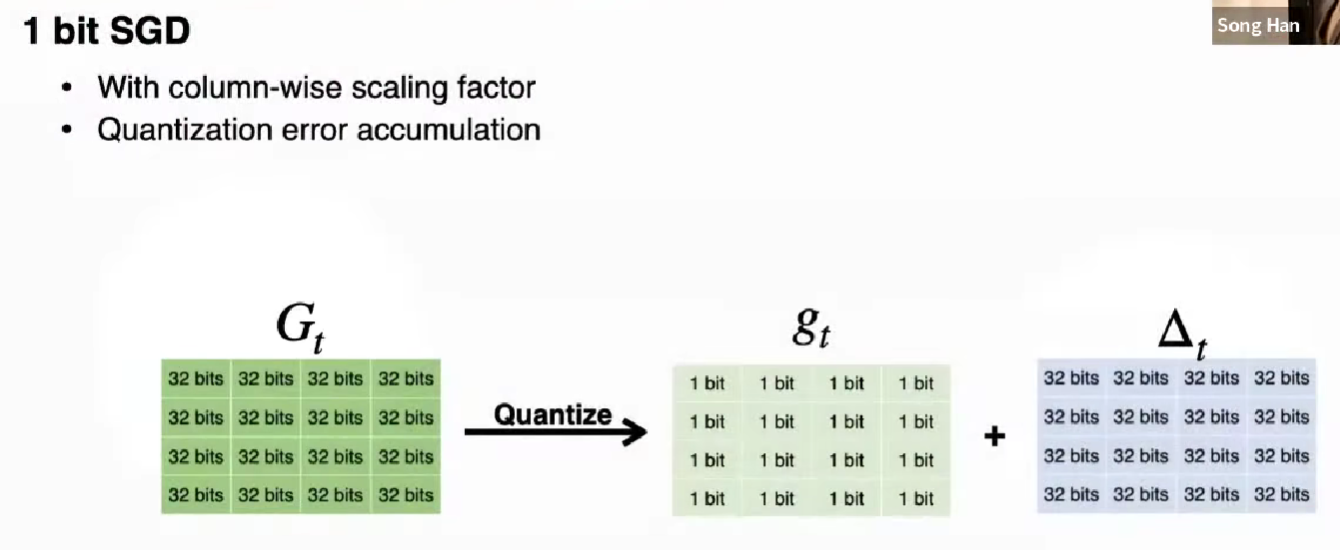
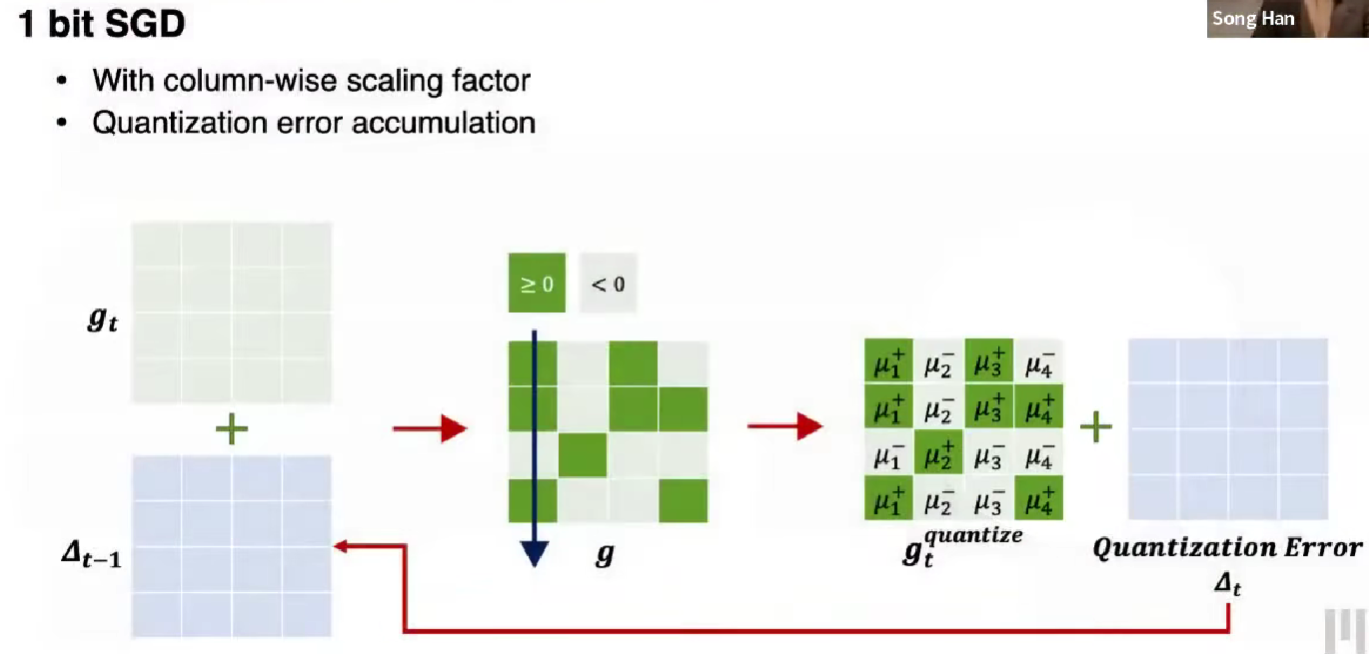
1-Bit SGD
把梯度量化为 1 bit,零阈值,同时保留 delta 值作为残差,缓解误差(累积到阈值,直接加回)。
每一列都增加一个 fp32 的缩放因子
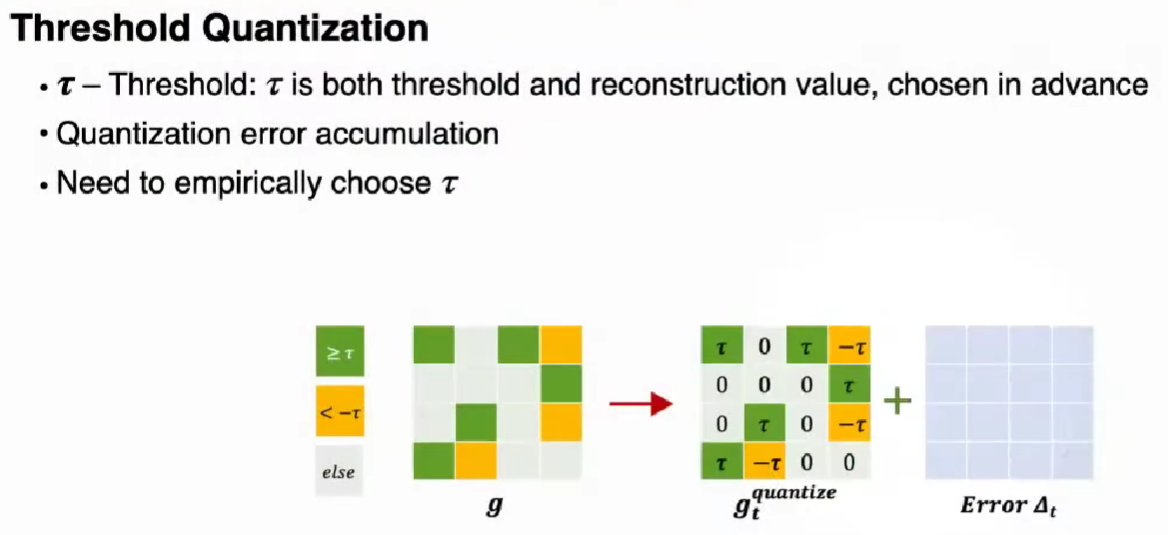
Threshold Quantization
设置 tau,大于 tau 为 tau,小于 -tau 为 -tau,之间为 0
需要经验选择 tau 值,同样有累积误差的机制
TernGrad
量化 g_i / max(g) 为 0, 1, -1 ,以概率来随机量化,期望一致,不需要累积误差。

Delayed gradient update: overcome the latency bottleneck
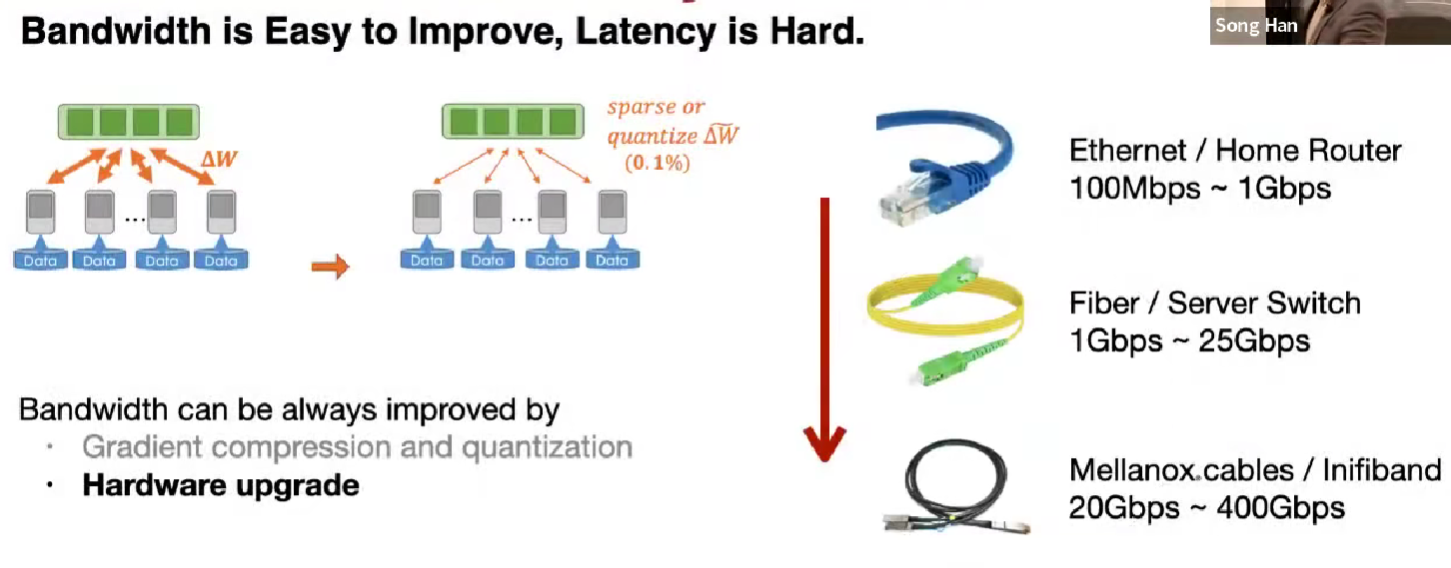
Bandwidth vs. Latency
带宽容易提升,剪枝量化、硬件提升;
延迟由物理限制,被光速限制
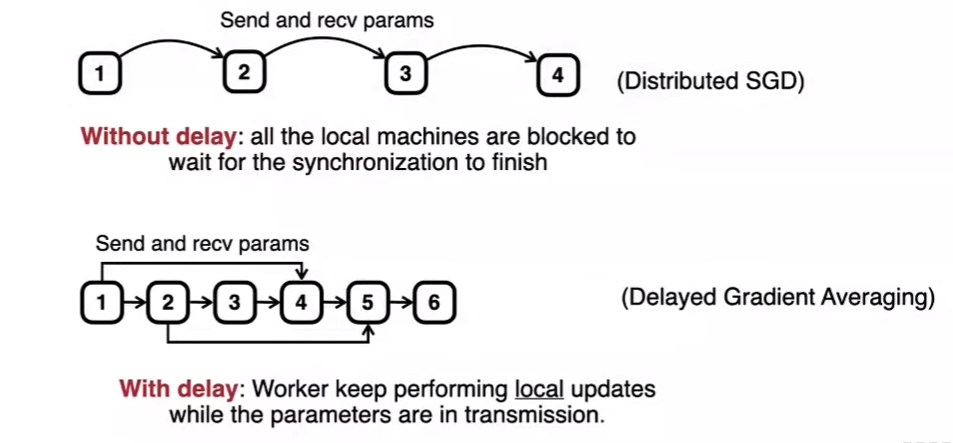
延迟高,同步延迟会变高。
Delayed Gradient Averaging
超过太多步是不行的。
最新的减去当前的来补偿延迟,avg_g 已经有了自己节点的梯度。
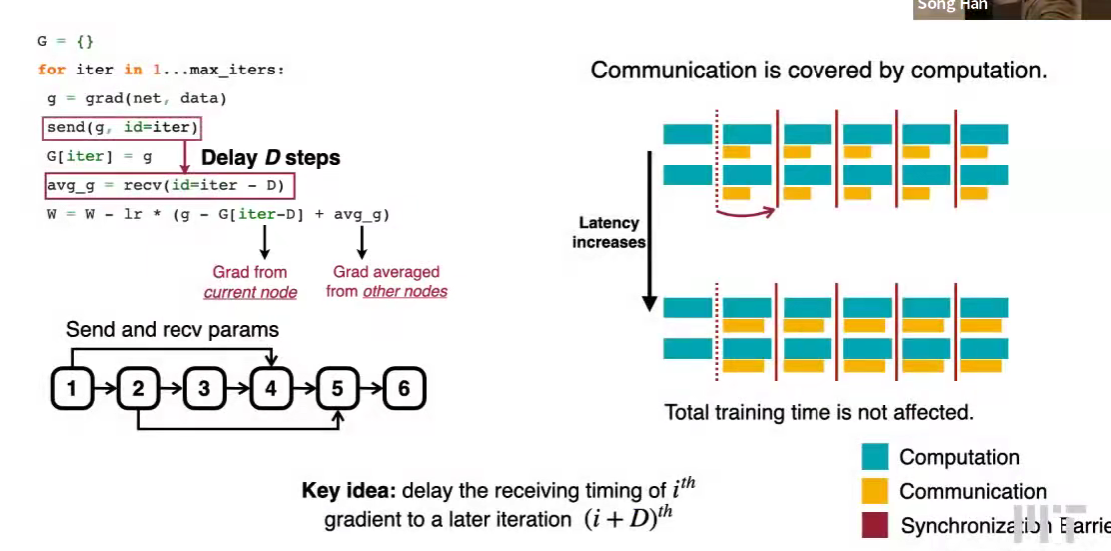
Lec21 On-Device Training and Transfer Learning
Deep leakage fram gradients, gradient is not safe to share
Federated learning 联邦学习
FedAvg algorithm,只传送权重/梯度
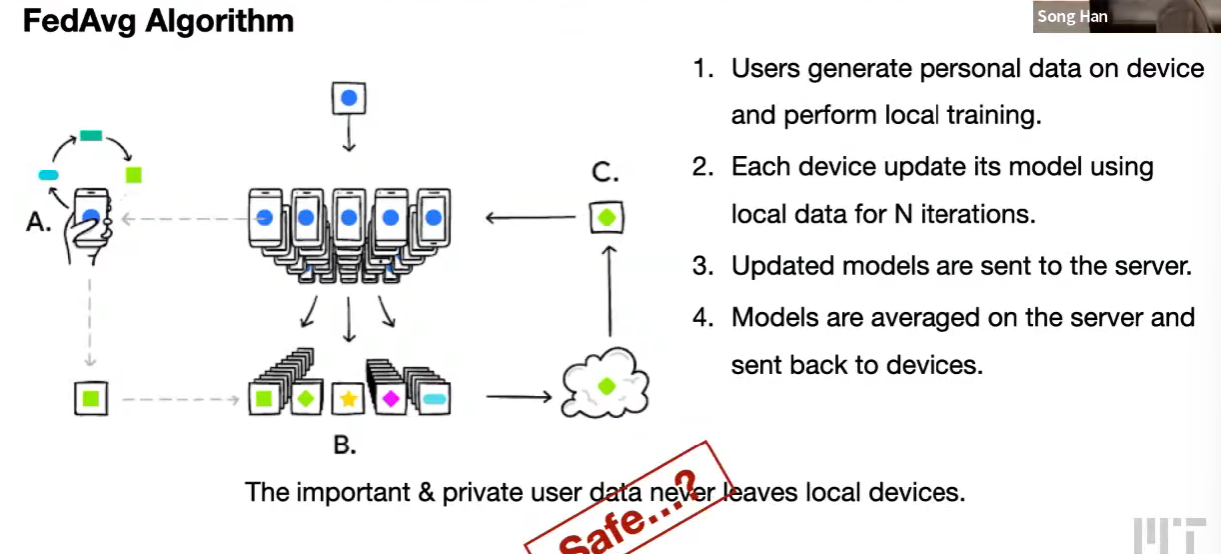
- Membership Inference,指出可以用梯度判断某个记录是否在批次中使用
- Property Inference,指出可以用梯度判断有特定属性的样本是否在批次中
Deep Leakage Attack
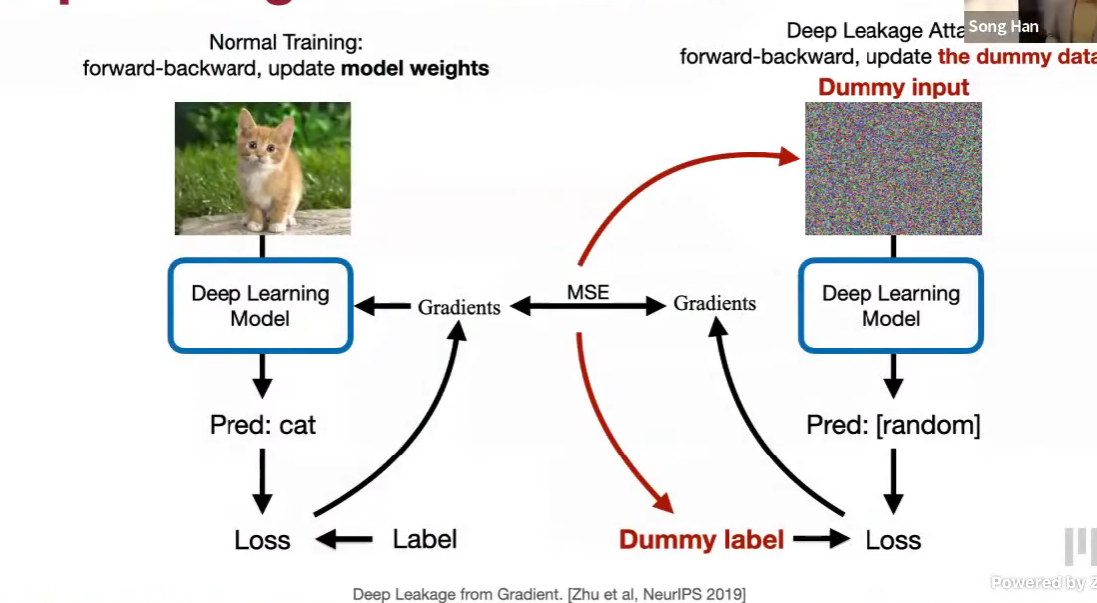
一张图片ok,一个批次多个图片,也是可以的,顺序可能不确定,但是内容可以
防御策略
增加 Gaussian / laplacian noise,过小没有用,过大破坏模型
梯度压缩,剪枝比例到 70% 基本不泄露,保持性能
只有很少的梯度泄露,复原不出来。
Memory bottleneck of on-device training
训练的内存占用大,因为批次大、需要存储中间激活值
(checkpoint 来计算换空间)
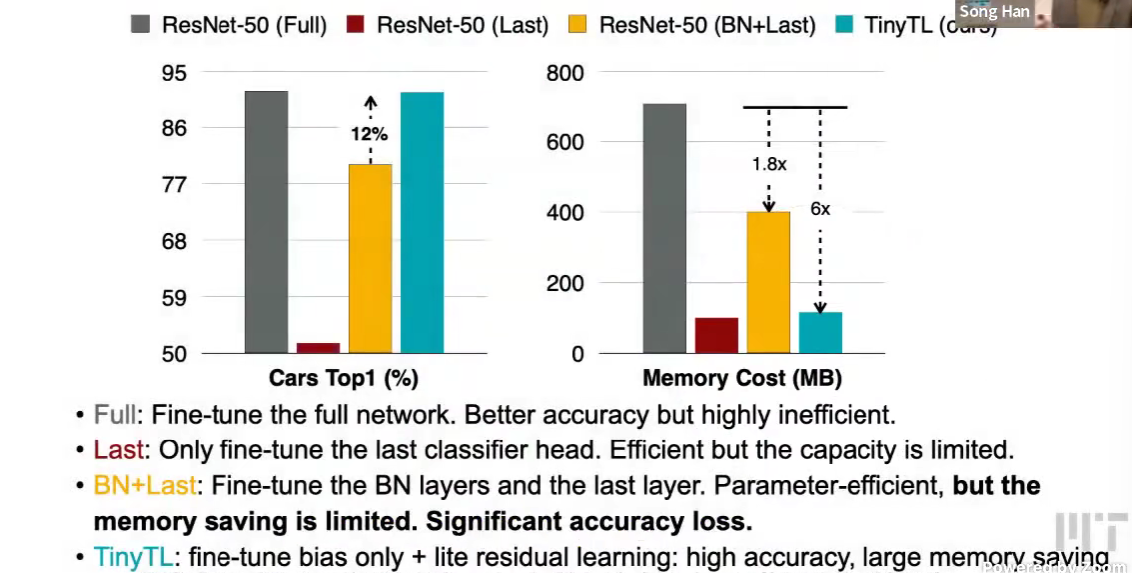
- Last 只微调最后一层?准确率下降很多
- BN + Last
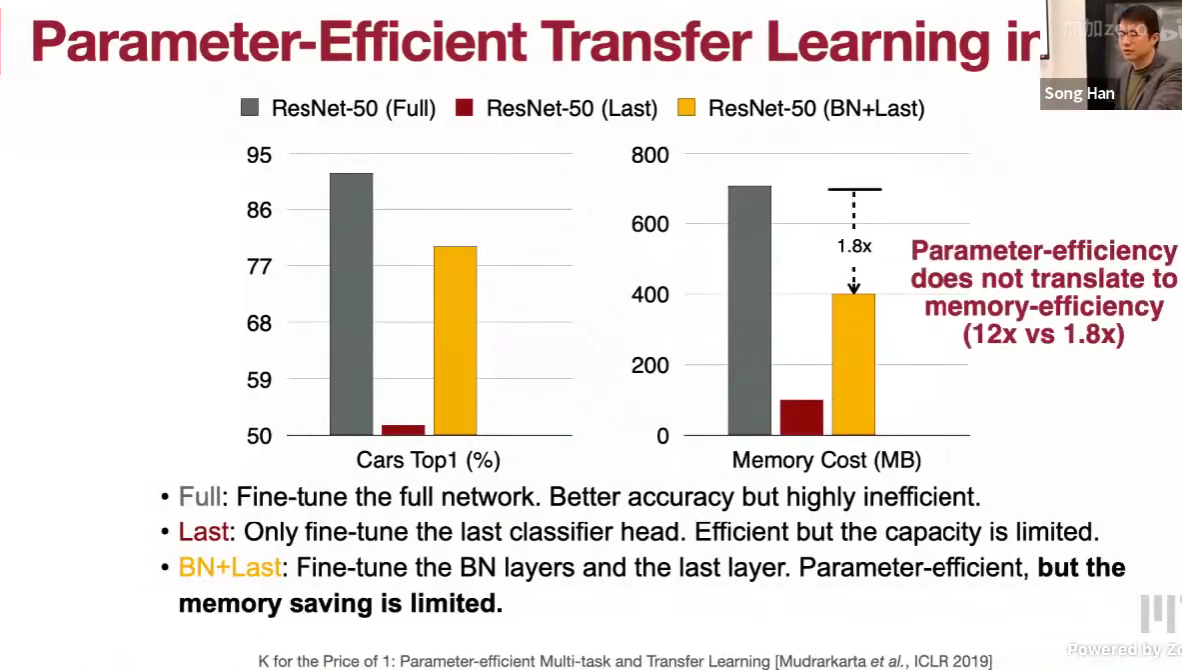
代价很大,效果不好
Tiny tansfer learning (TinyTL)
反向传播更新权重需要激活值,bias偏置不需要激活值
只微调偏置,Bias + Last
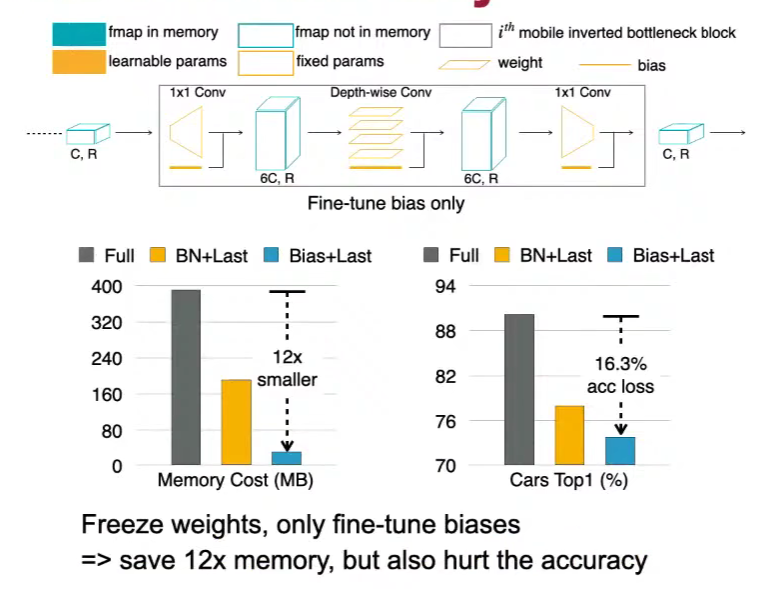
引入轻量分支
比剪枝激活值更有效
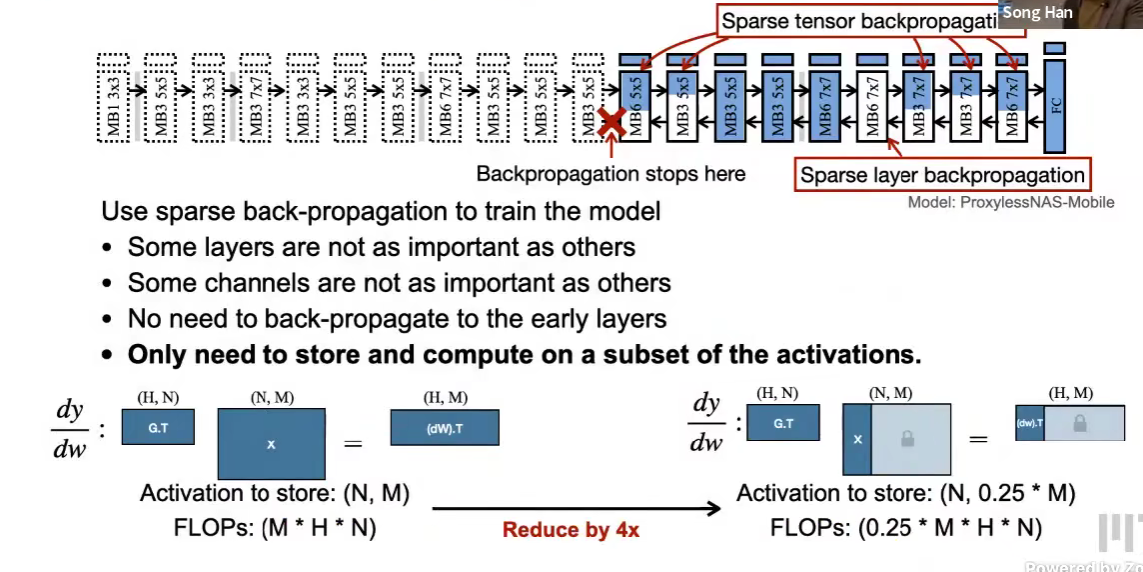
Sparse back-propagation (SparseBP)
从生物学出发的方法。
只更新一部分层(深度深的高级特征)
只更新一层中的一部分参数
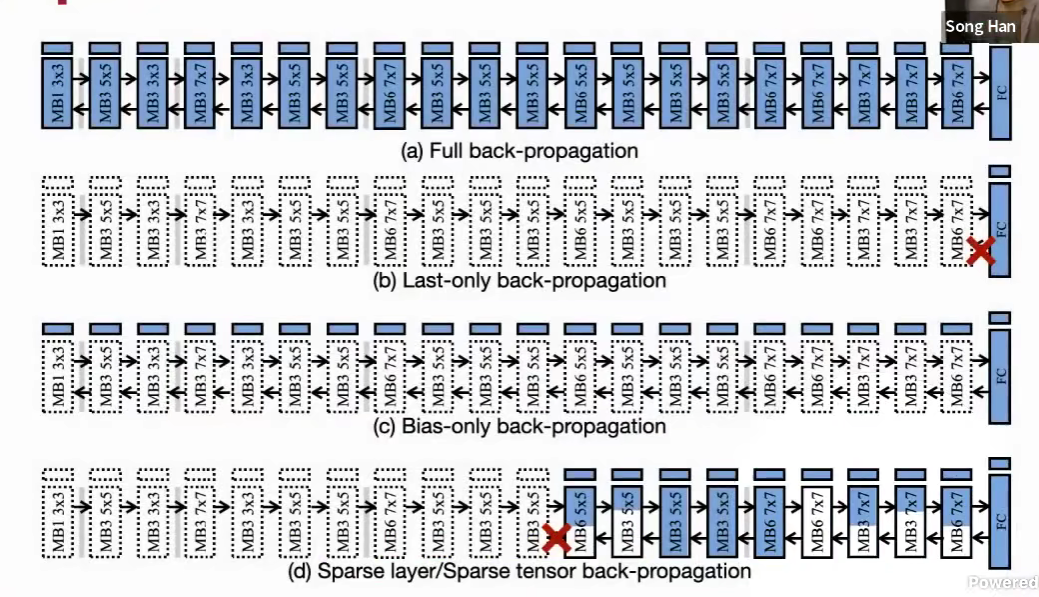
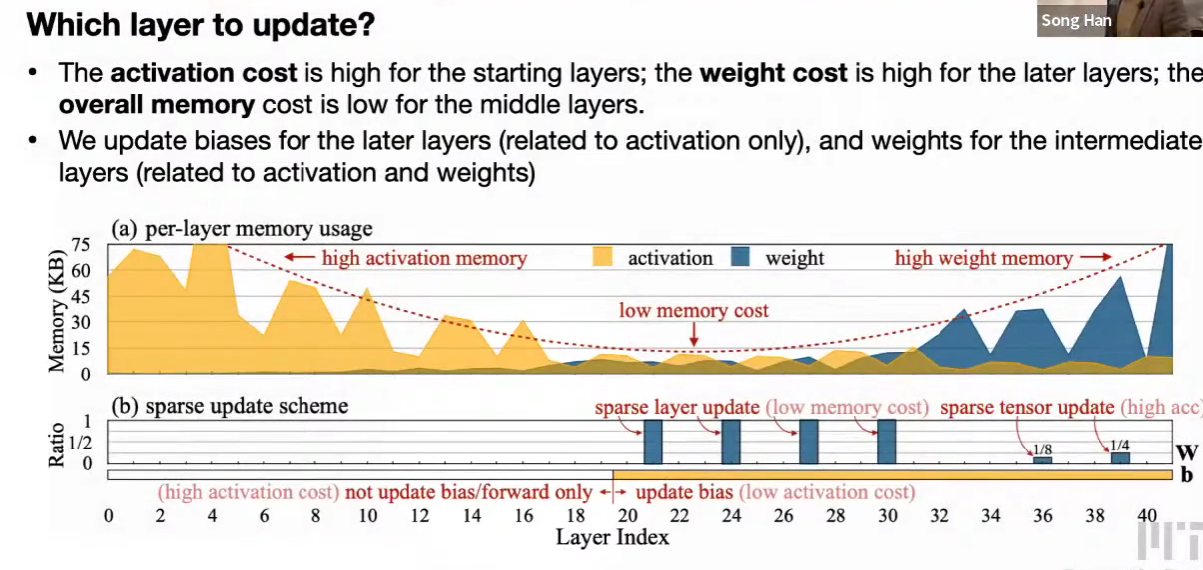
怎么选择?
起始分辨率高,后面通道数多
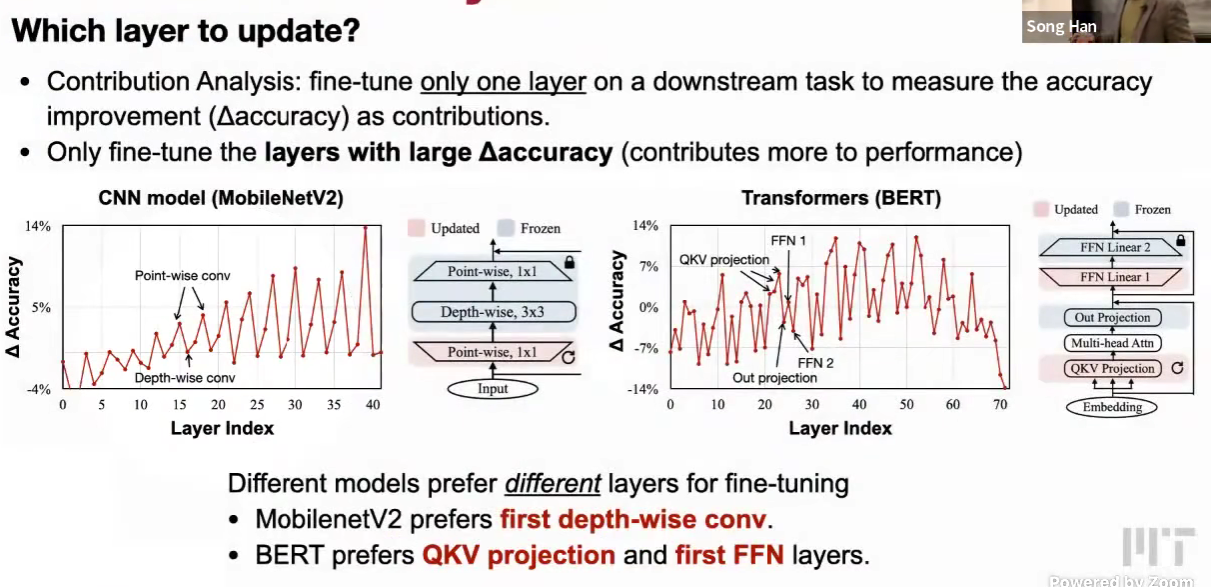
contribution analysis 贡献分析
自动求解器,类似敏感度分析
只更新前面的层,acc 甚至变差。
发现重复的起伏,peak是点卷积,curve是深度卷积
更新比例。
用进化算法搜索。
SparseBP 的输出会更长?待研究。

Quantized training with quantization aware scaling (QAS)
在 int8 下,梯度值过小
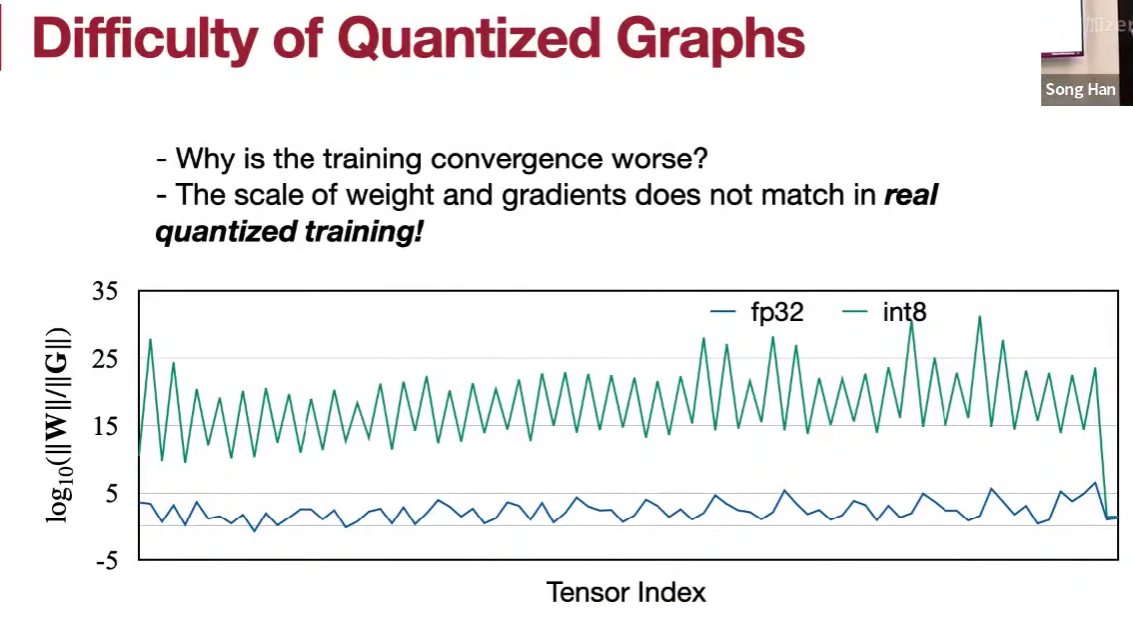
修正缩放因子

PockEngine: system support for sparse back-propagation
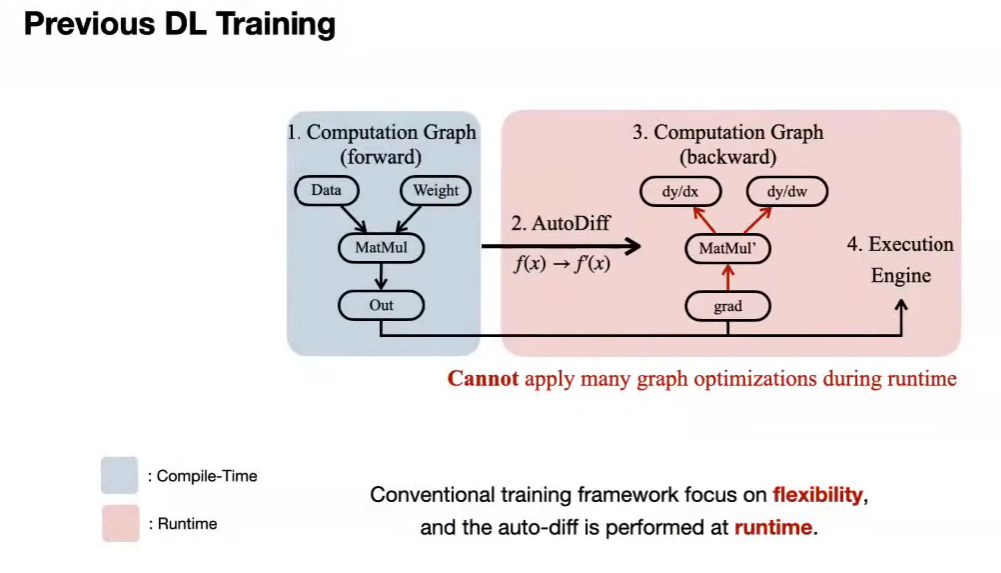
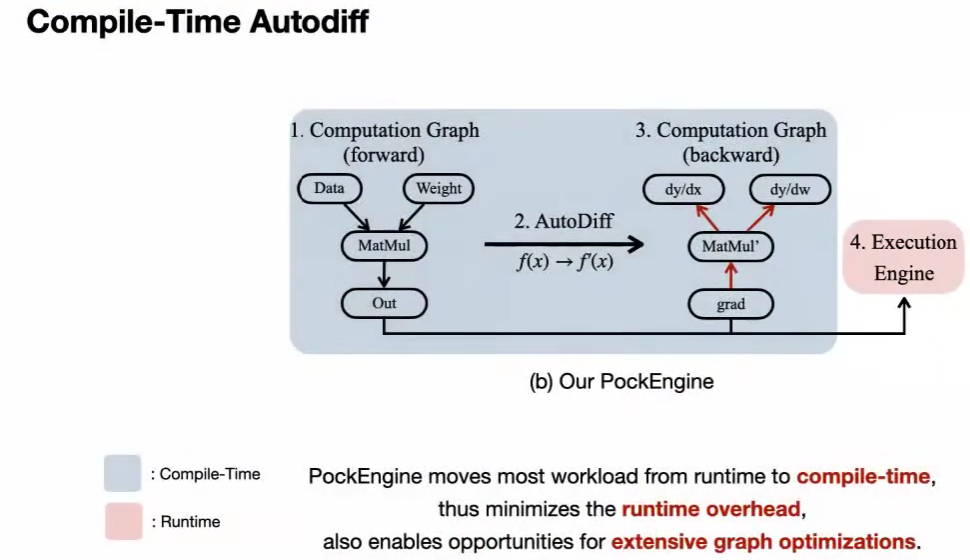
多种芯片,编译中,运行轻,训练优化。
Lec22 Quantum Machine Learning 1
解码量子纠错代码
Noisy Intermediate-Scale Quantum (NISQ)
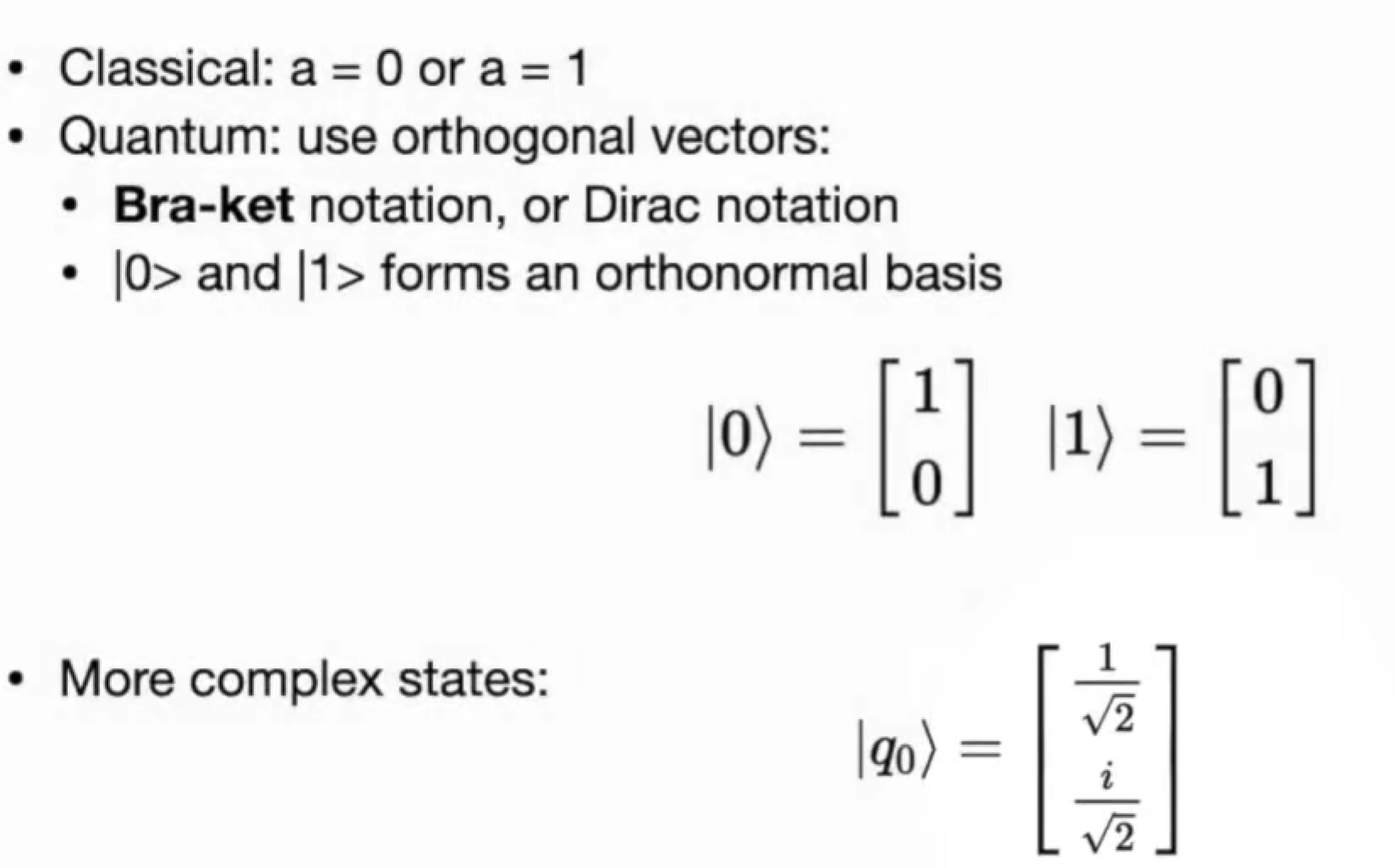
Single qubit state and gates
Single qubit state
basic component => Quantum Bit (Qubit)
state => statevector
Bra-ket notation 狄拉克符号
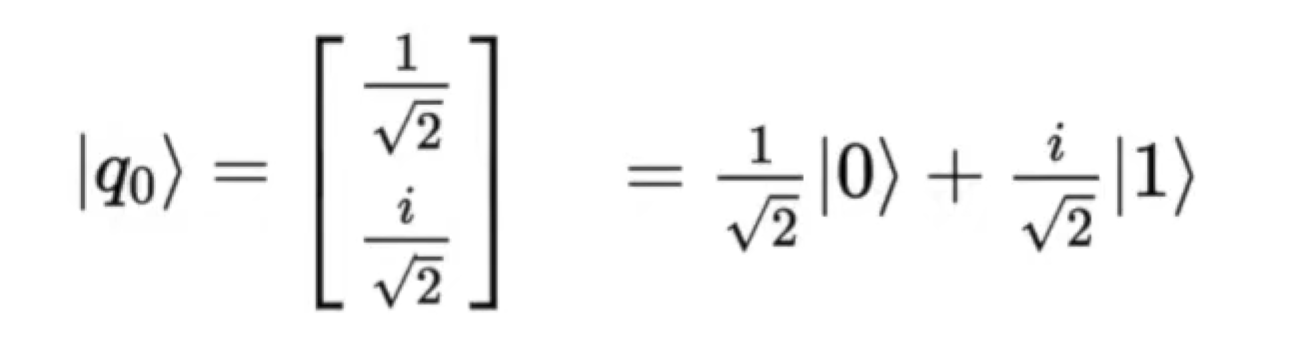
Measurement

Bloch Sphere 布洛赫球
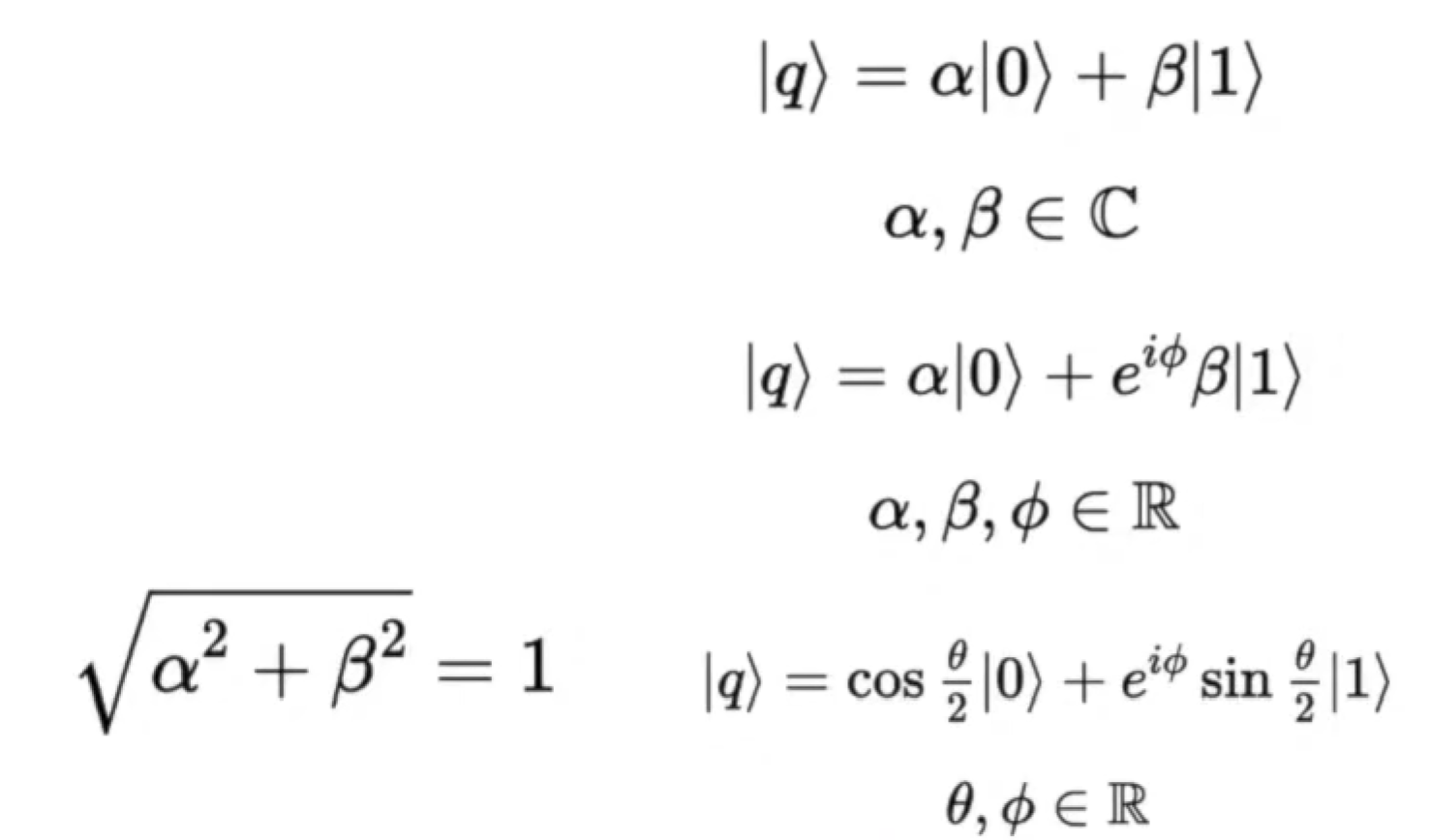
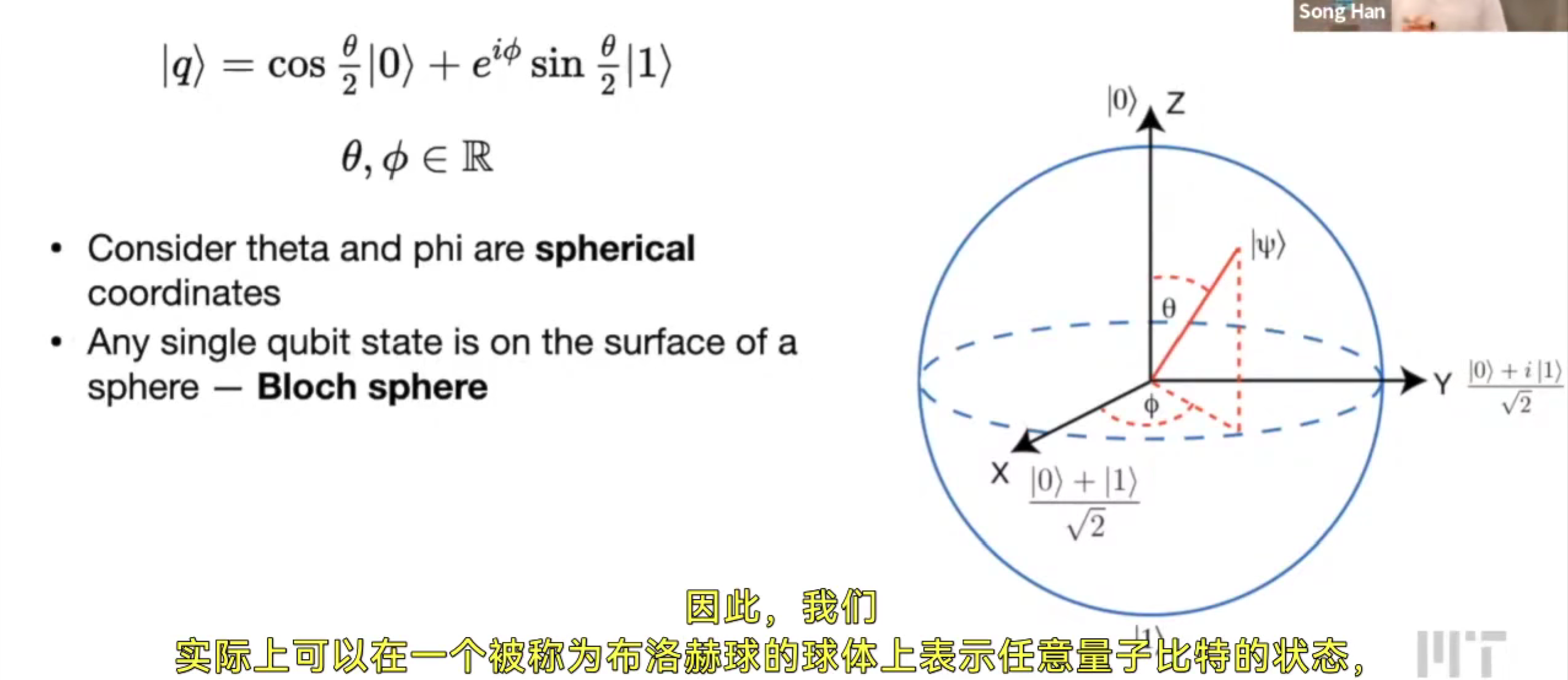
用布洛赫球去表示任意量子比特的状态
Single Qubit Gates
所有 Quantum gates 量子门 都是 reversible 可逆的(保证能量是一致的)
最简单的量子门是恒等映射
可逆门可用矩阵、布洛赫球的旋转
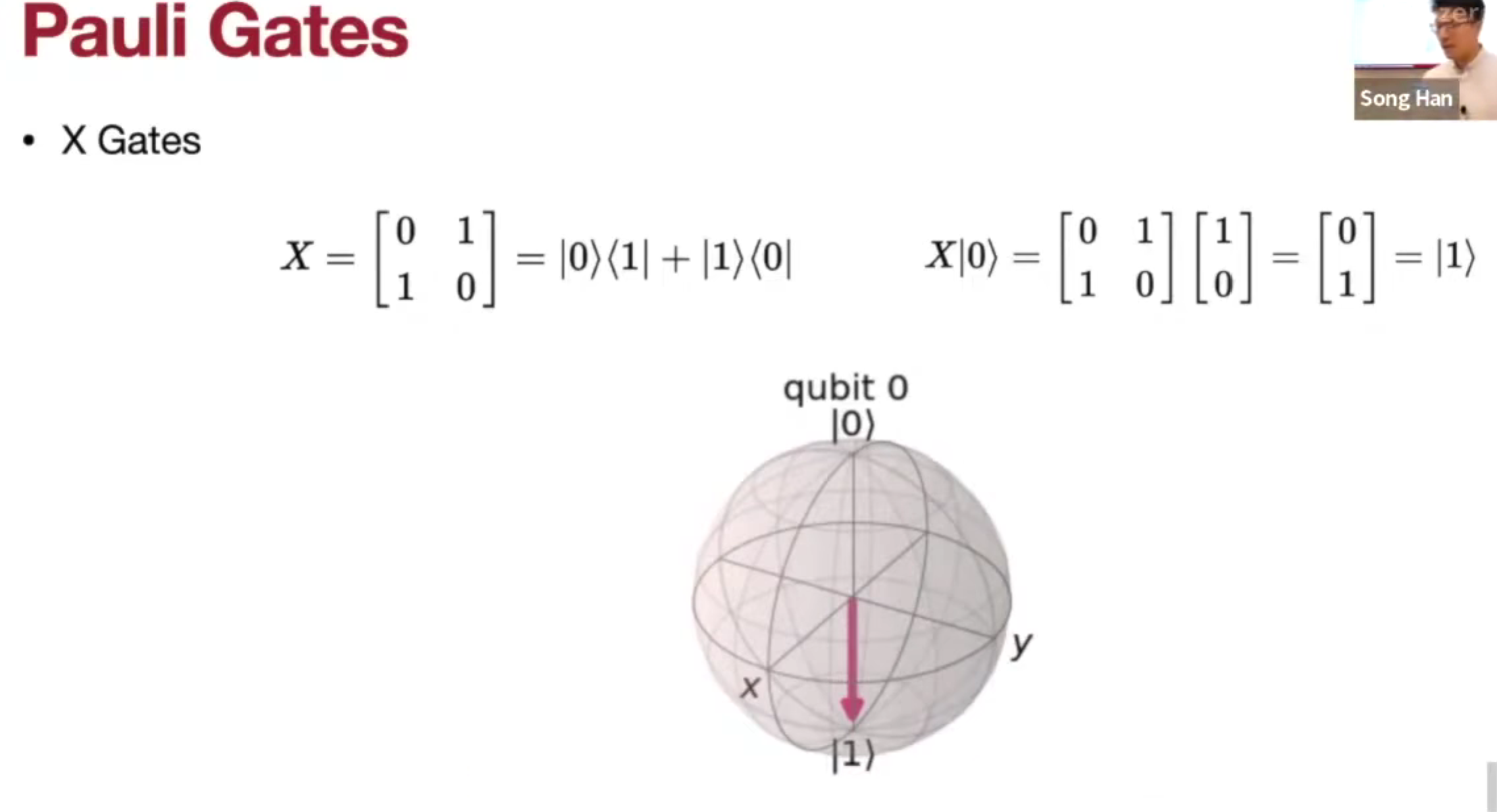
Pauli Gates
- X Gate (Not Gate)
- Y Gate
- Z Gate,0 => 0, 1 => -1, 全局相位 phase,常规无法测量,所以也认为一致
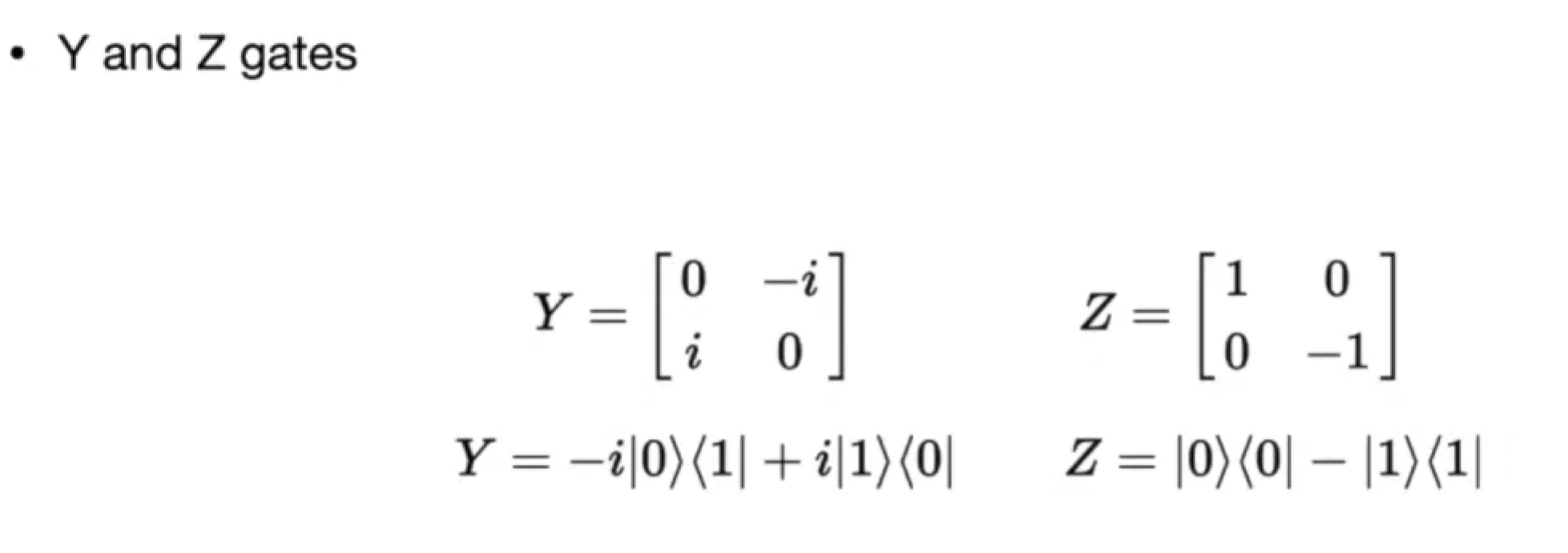

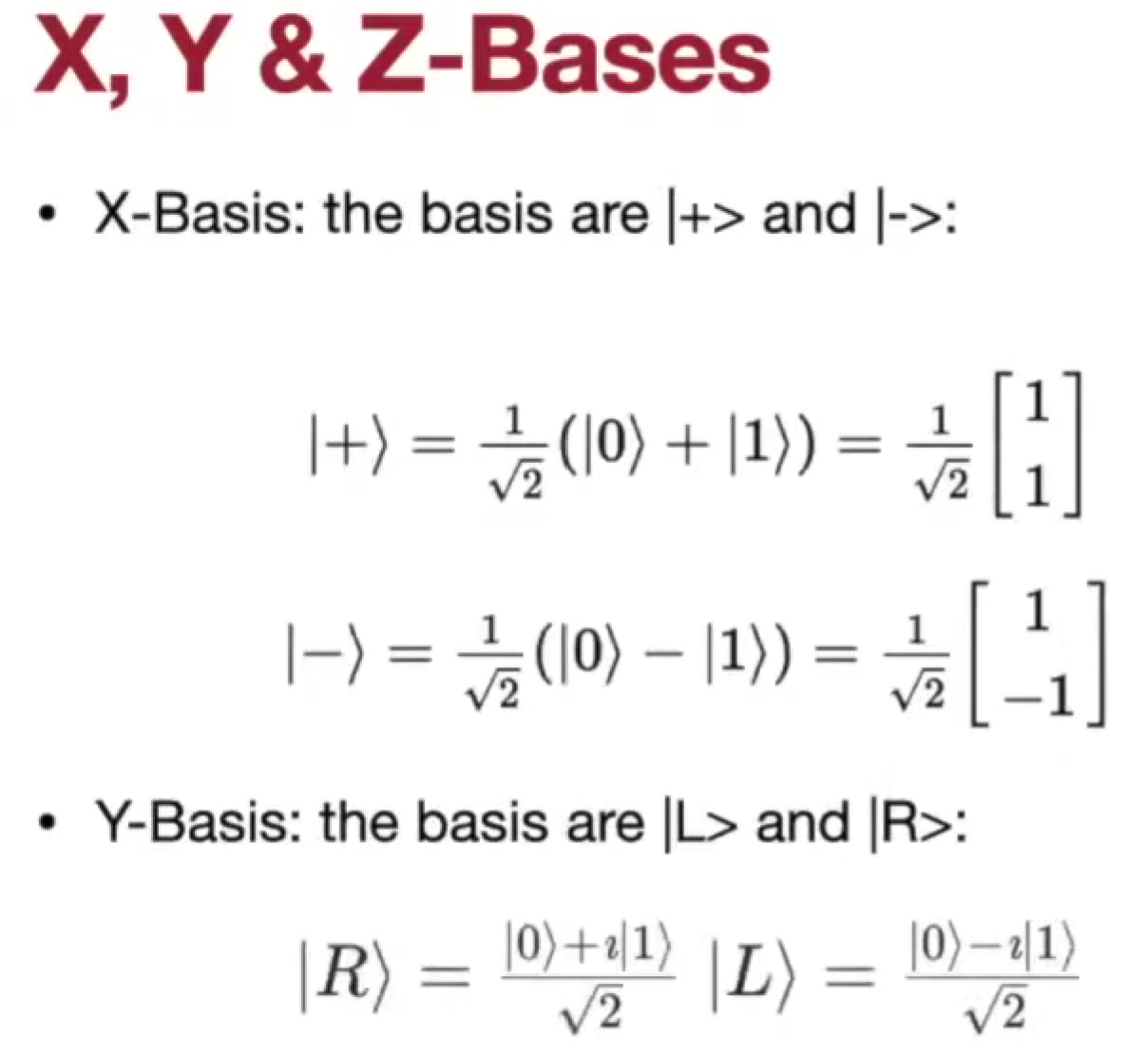
Hadamard Gate
创建叠加态

Other Gates
- Phase Gate
- S Gate
- S dagger Gate

U Gate
可以表示所有,通用门

Multiple-qubit state and gates
Multiple-qubit state
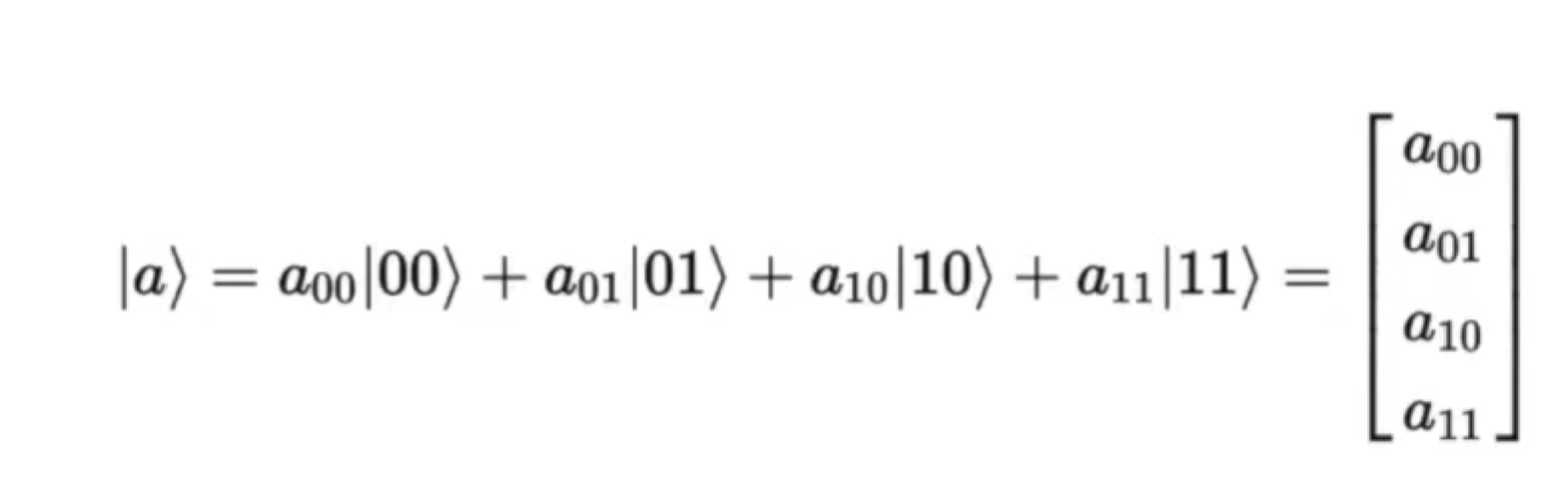

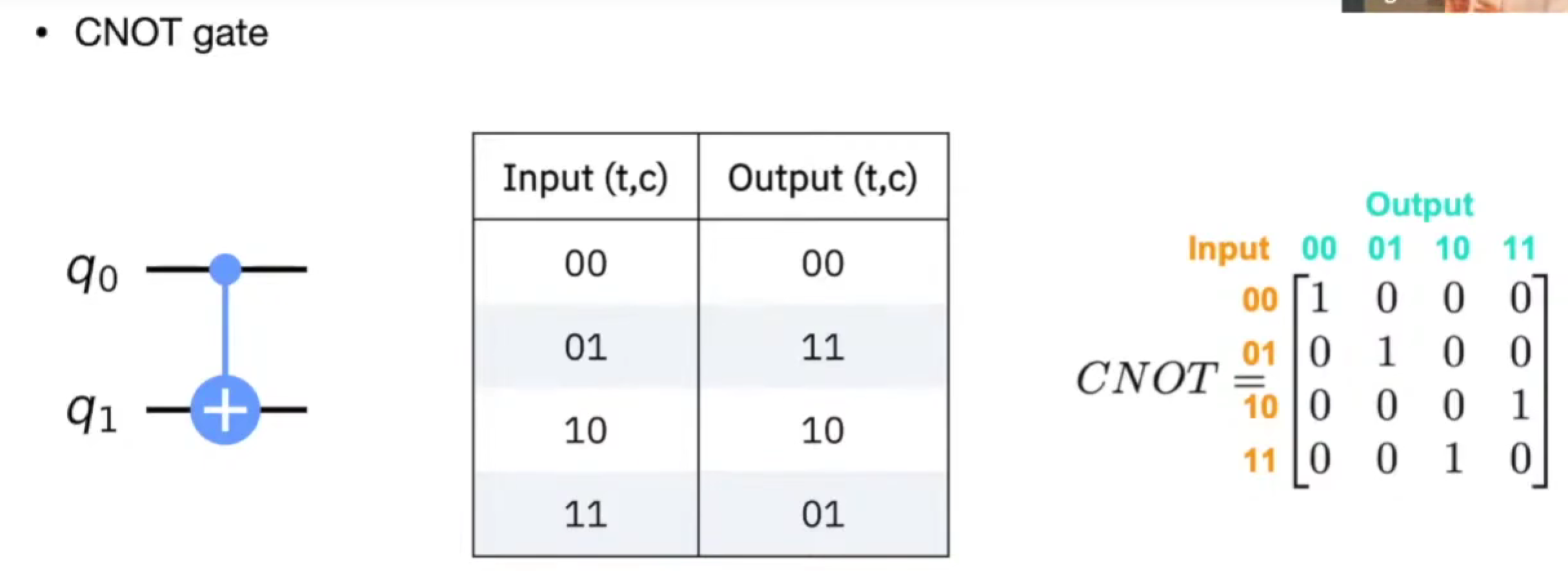
Multiple-qubit gates
- CNOT Gate
- …
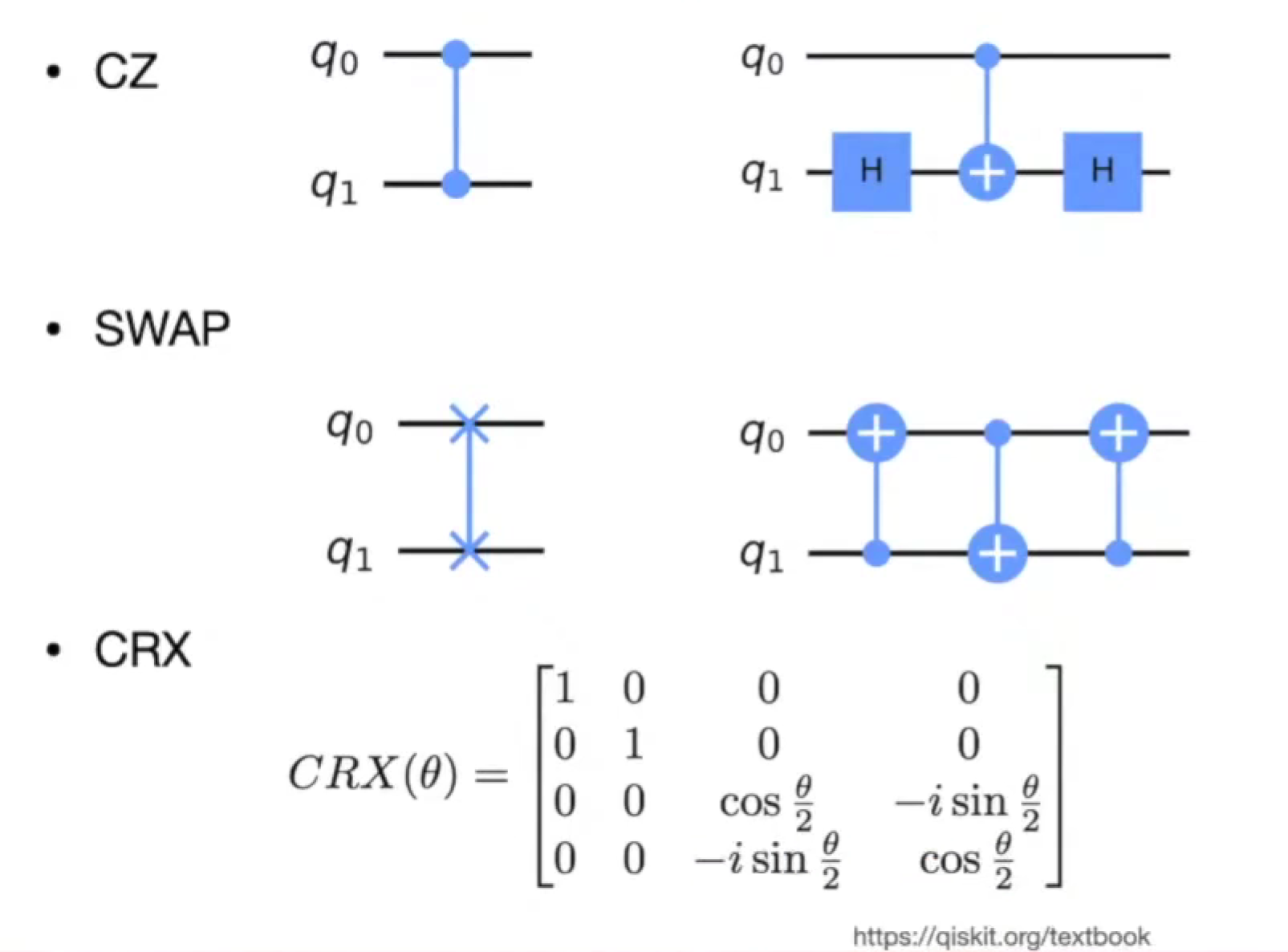
quantum circuit
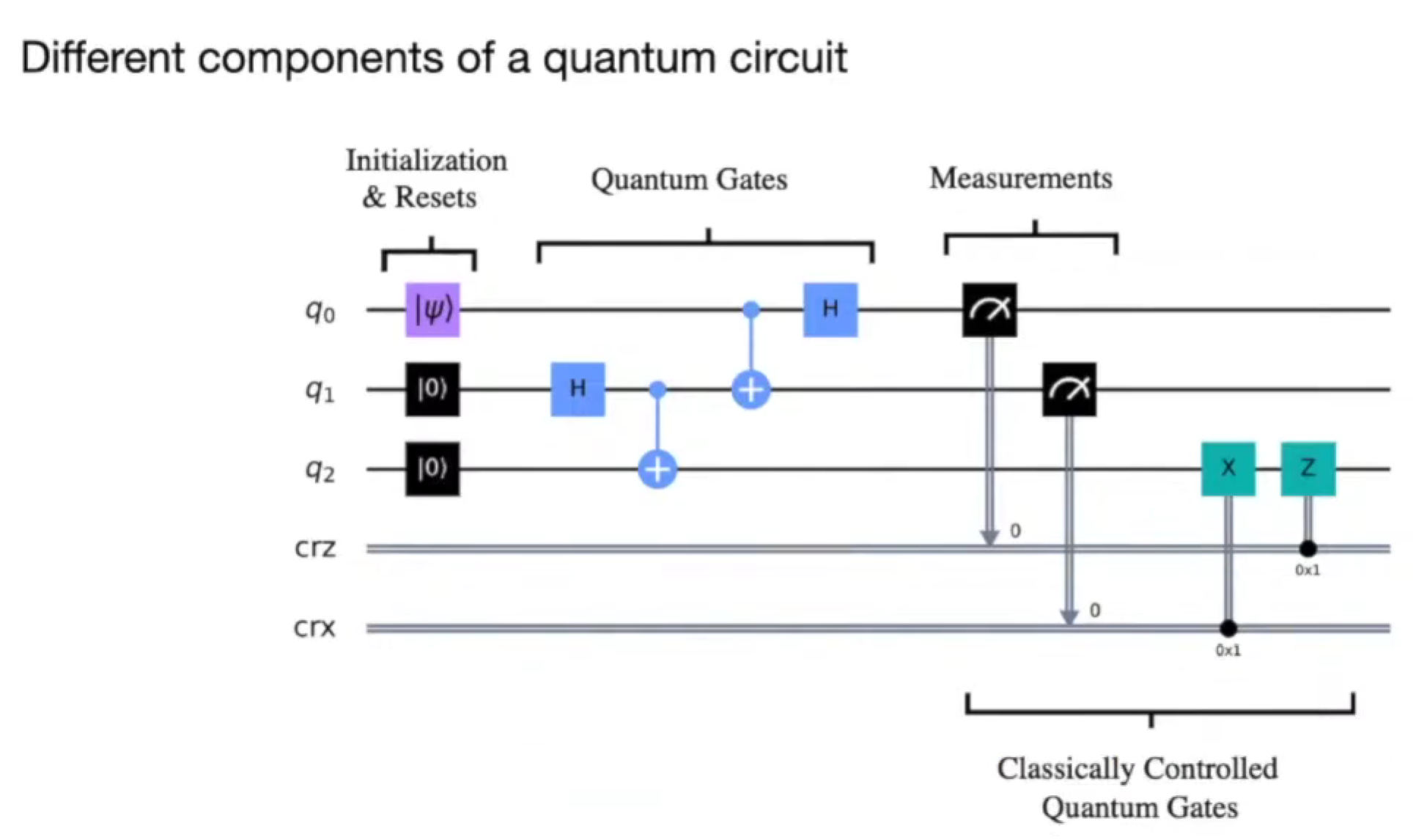
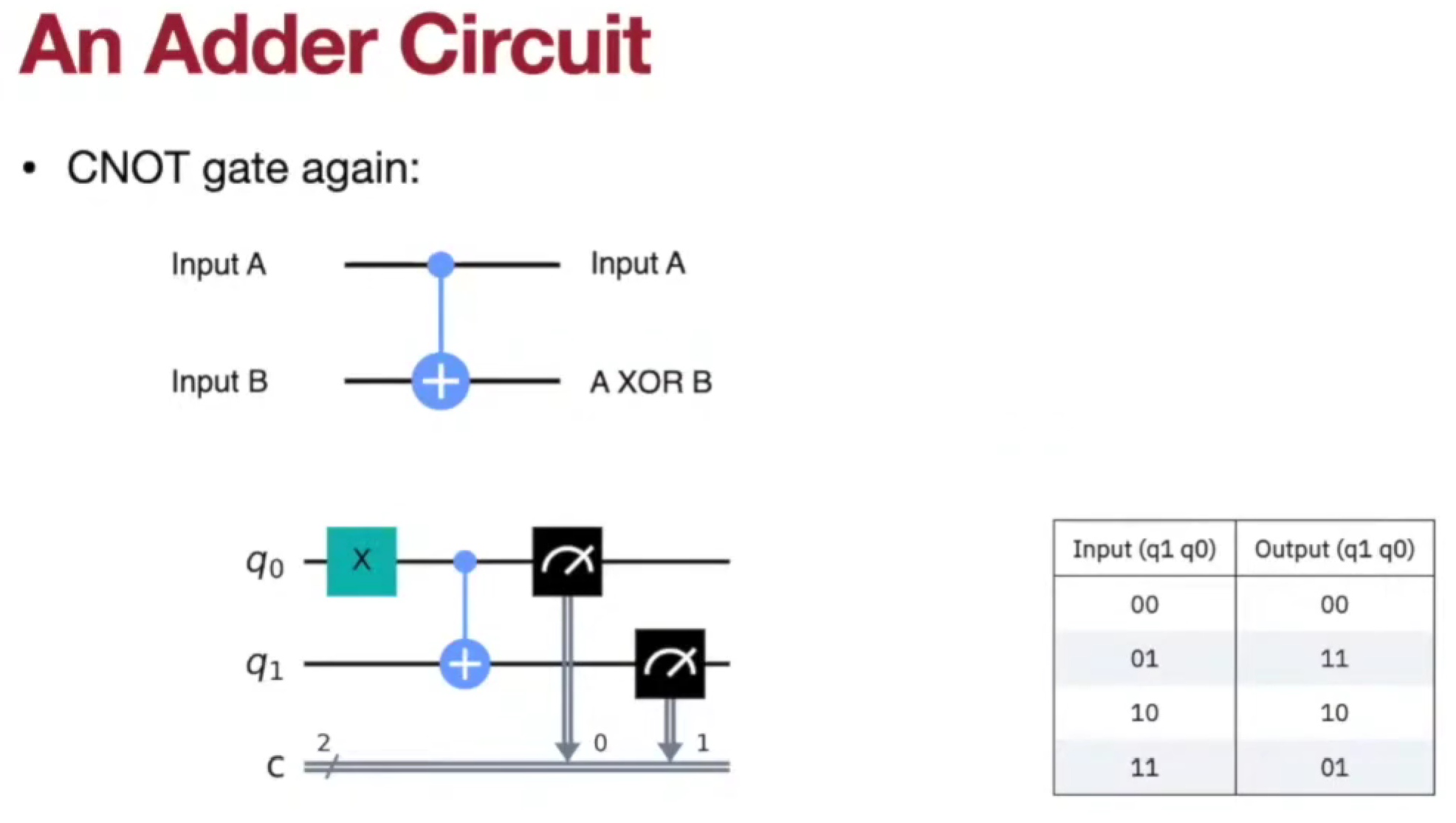
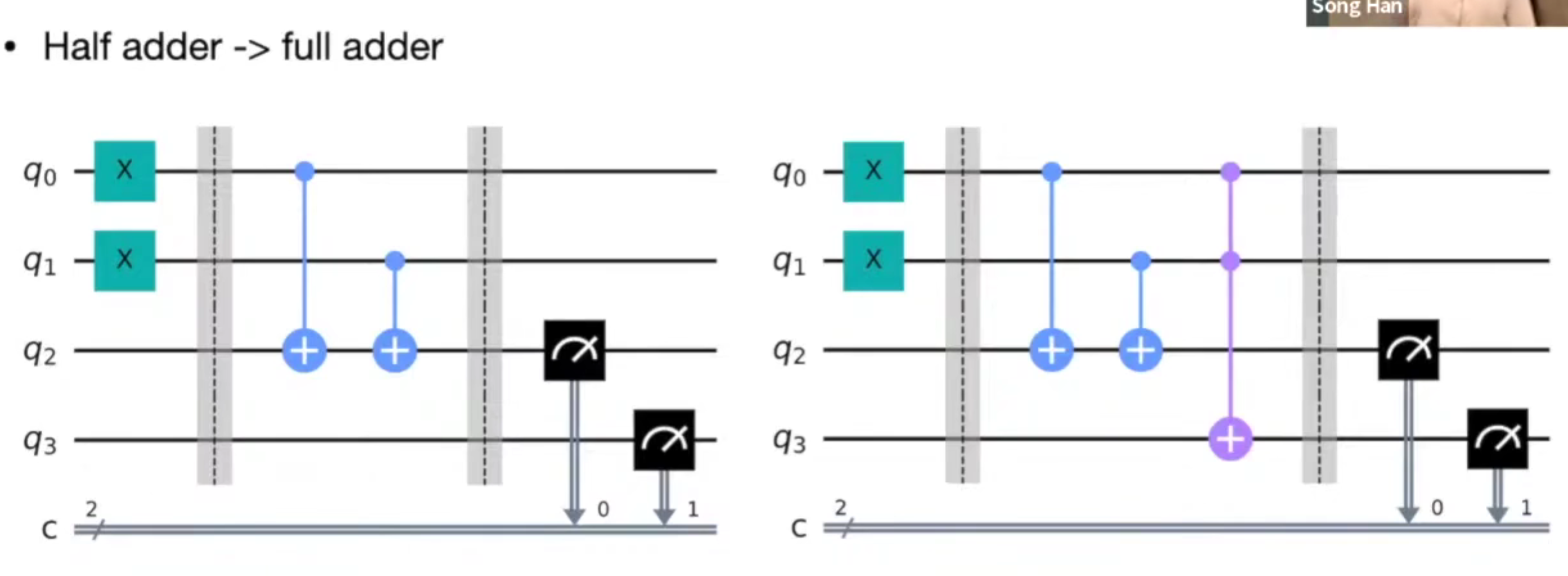
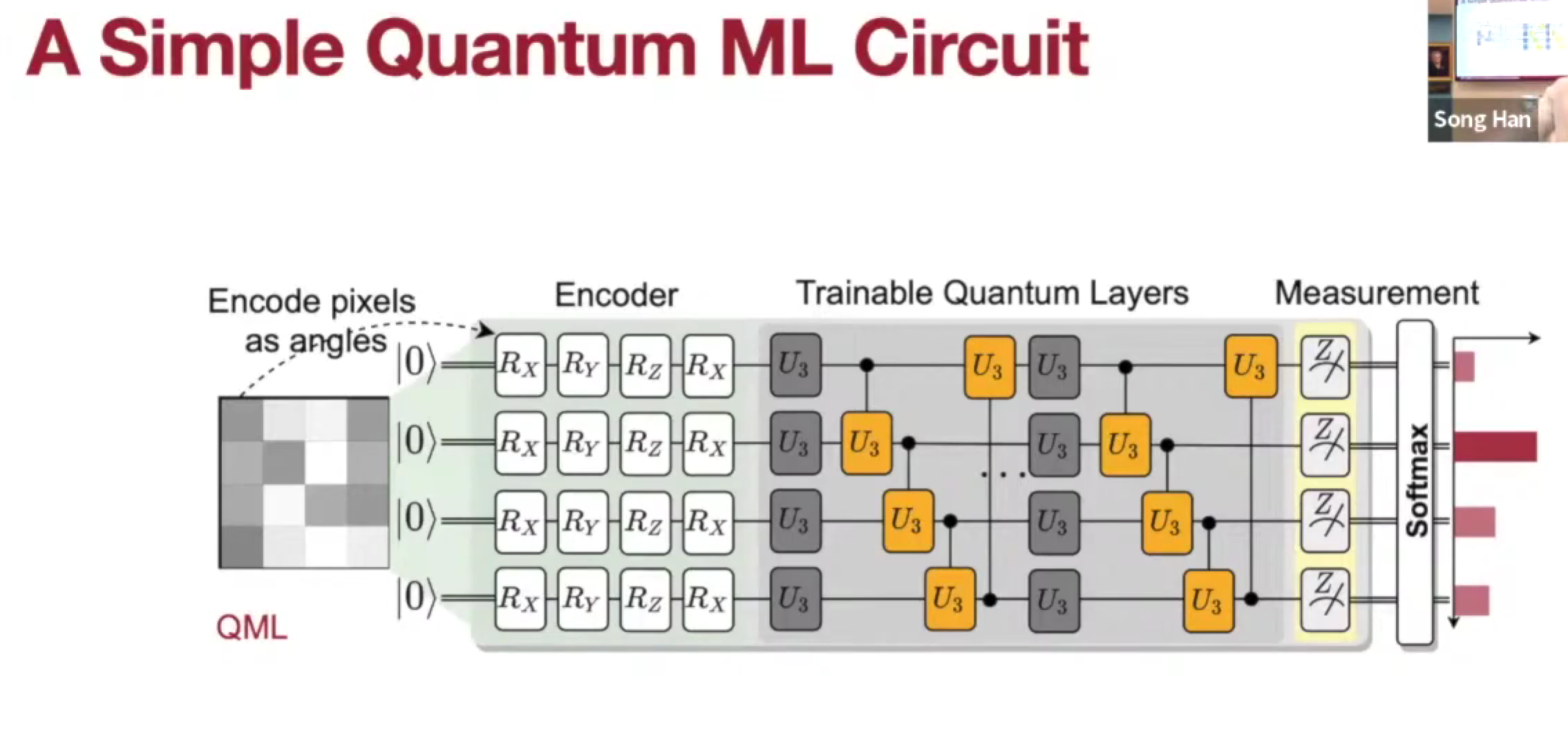
数据编码/上传代价是现在的主要瓶颈。
the NISQ era and compilation problems


Single-qubit X error rate => 1.718e-3
CNOT error rate => 6.973e-2
不同量子比特的性能可能不同,误差率。
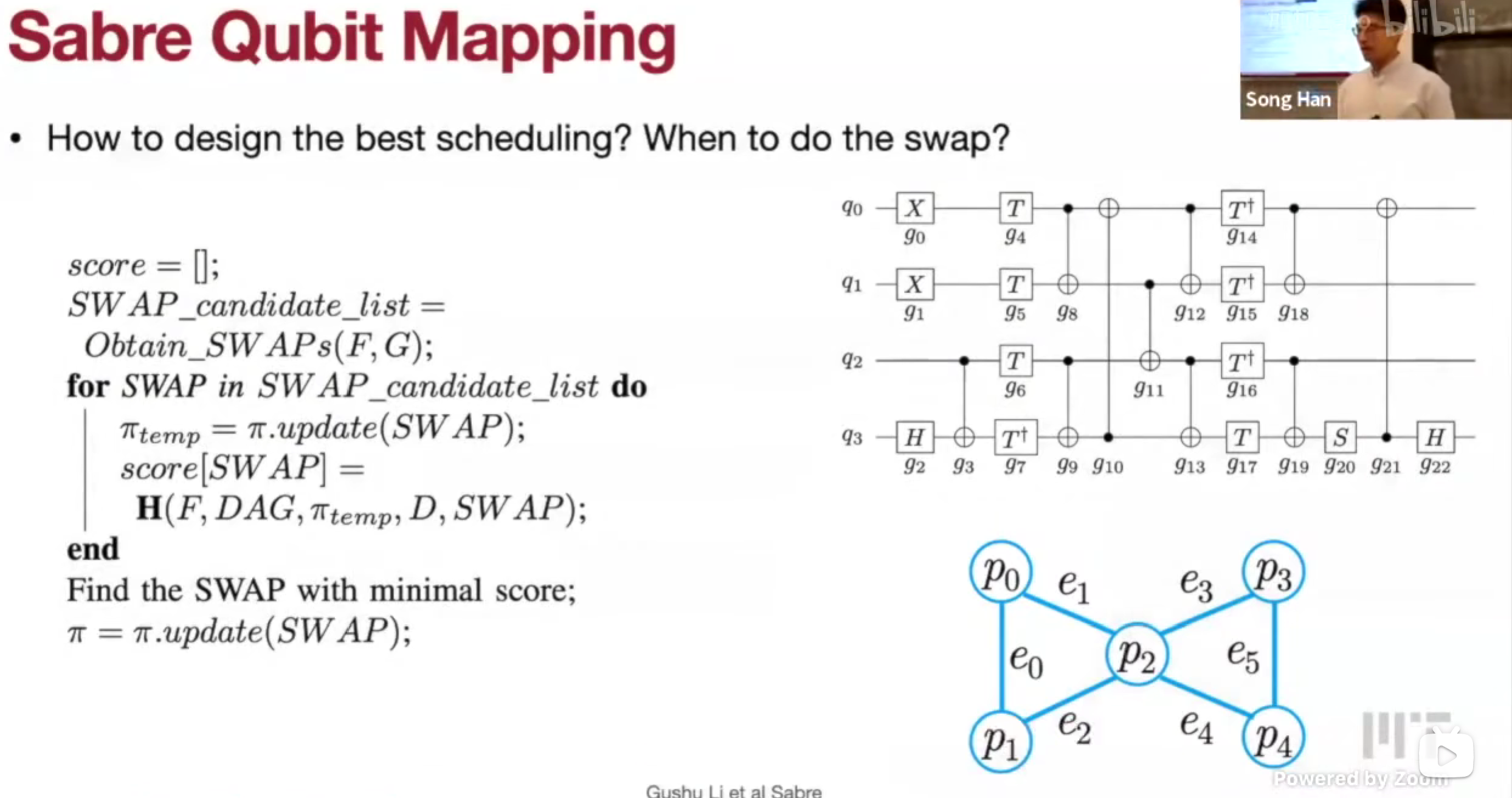
Sabre Qubit Mapping
看交换后能执行的门,启发式交换
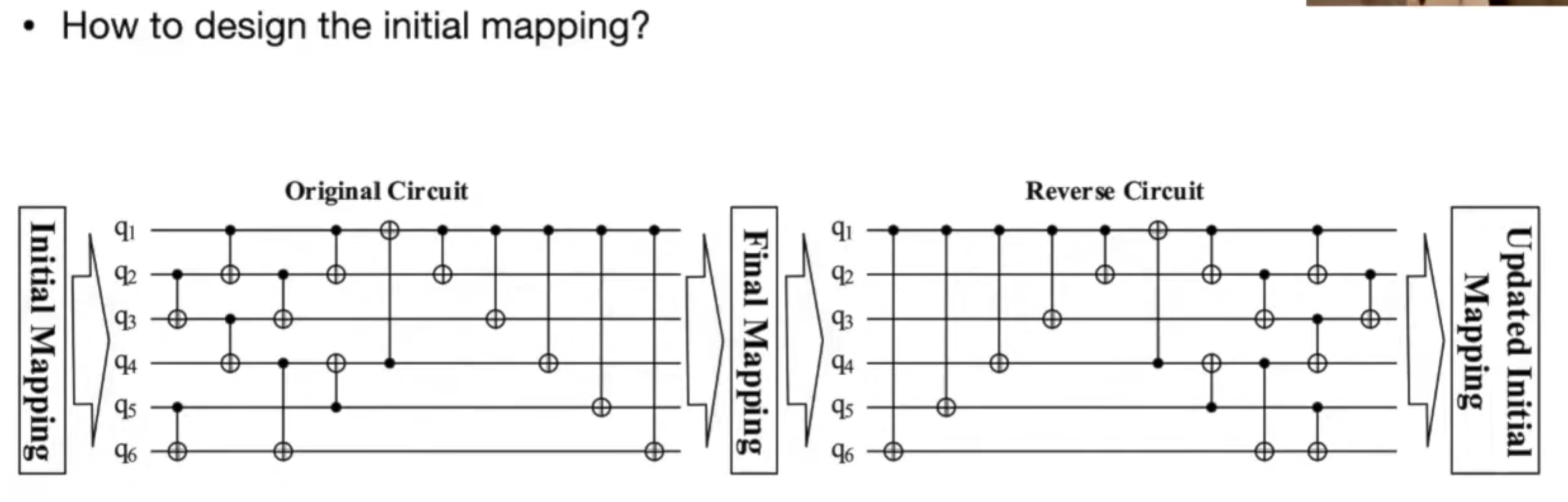
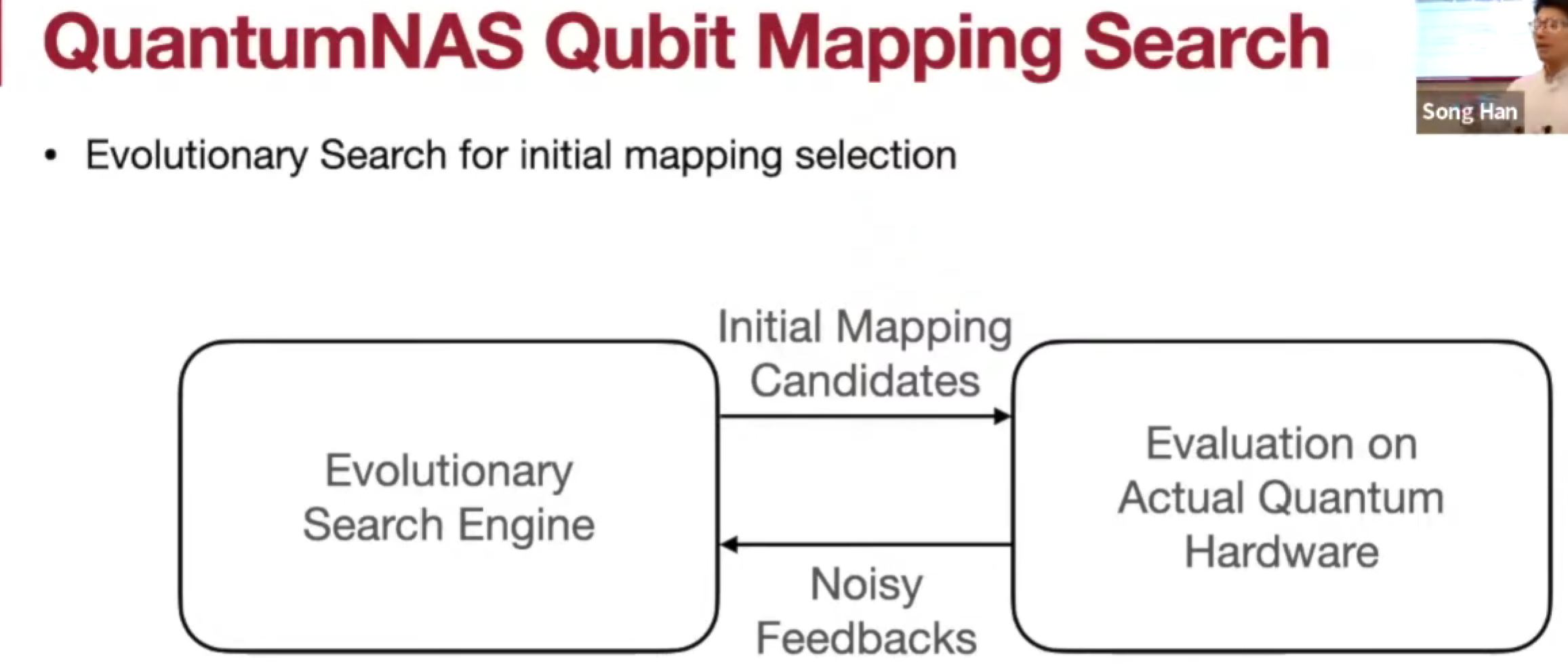
QuantumNAS
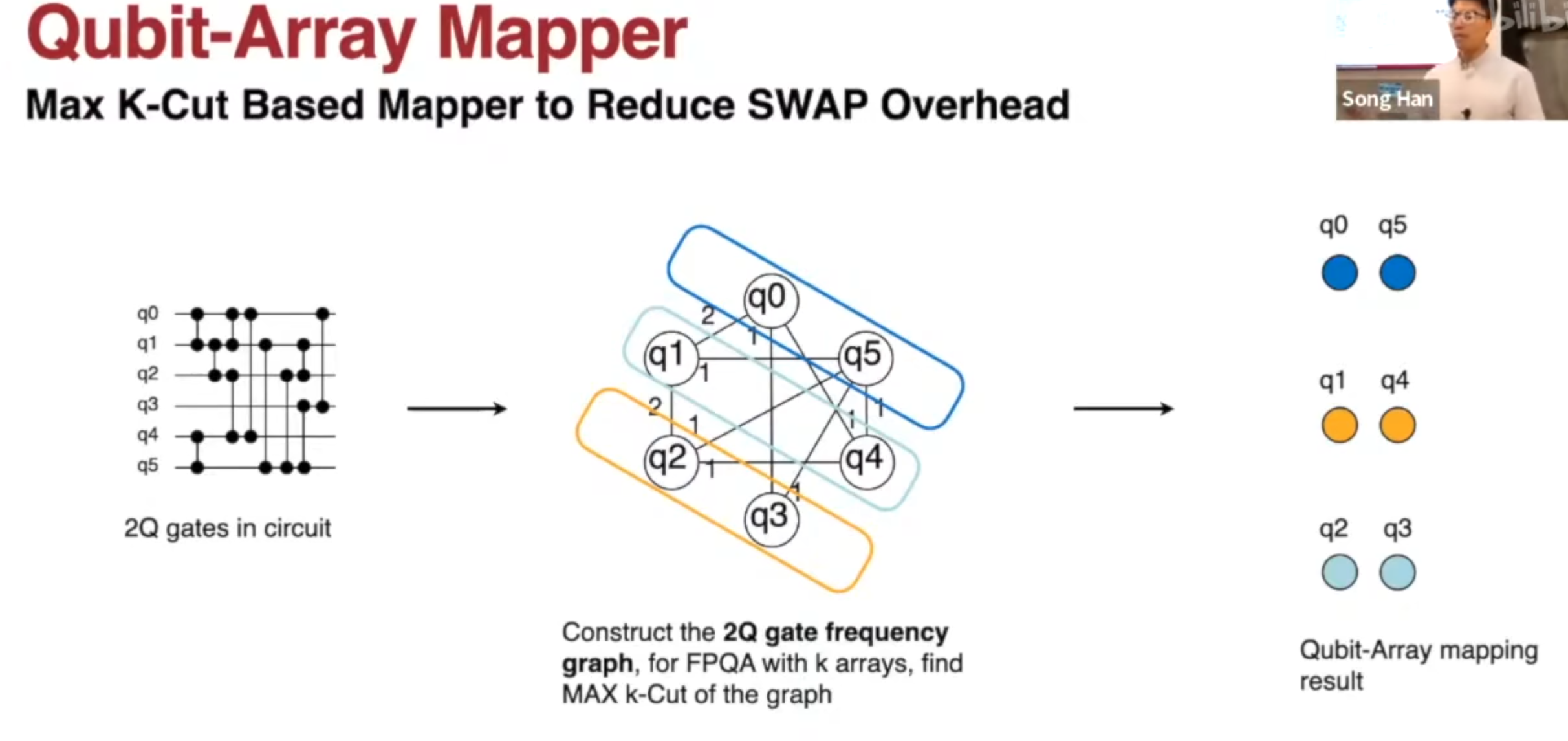
the example workflow and compiler on neutral atom quantum computer

最大 k 割去优化编译
Lec23 Quantum Machine Learning 2
TBD.

Parameterized Quantum Circuit (PQC)
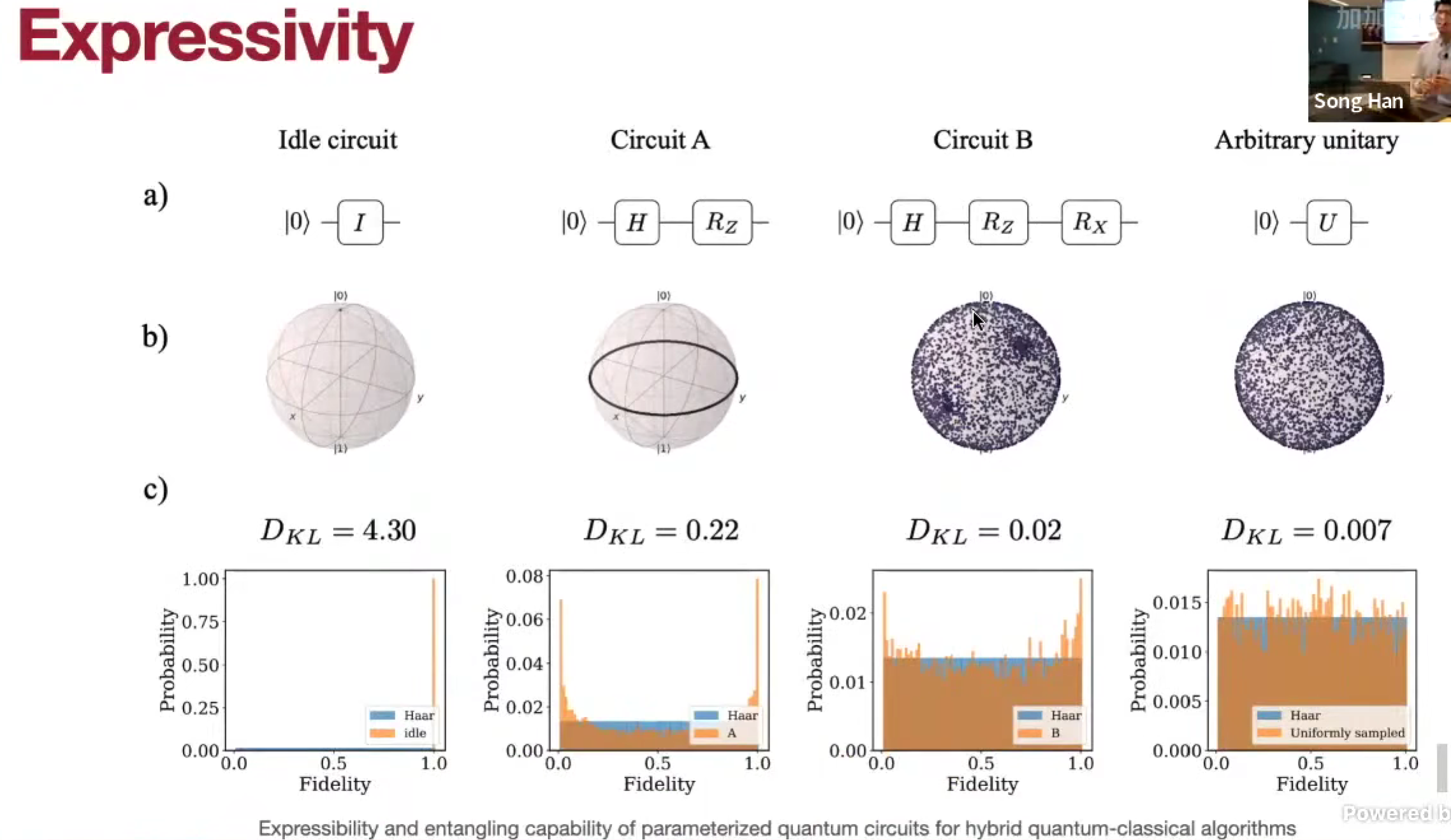
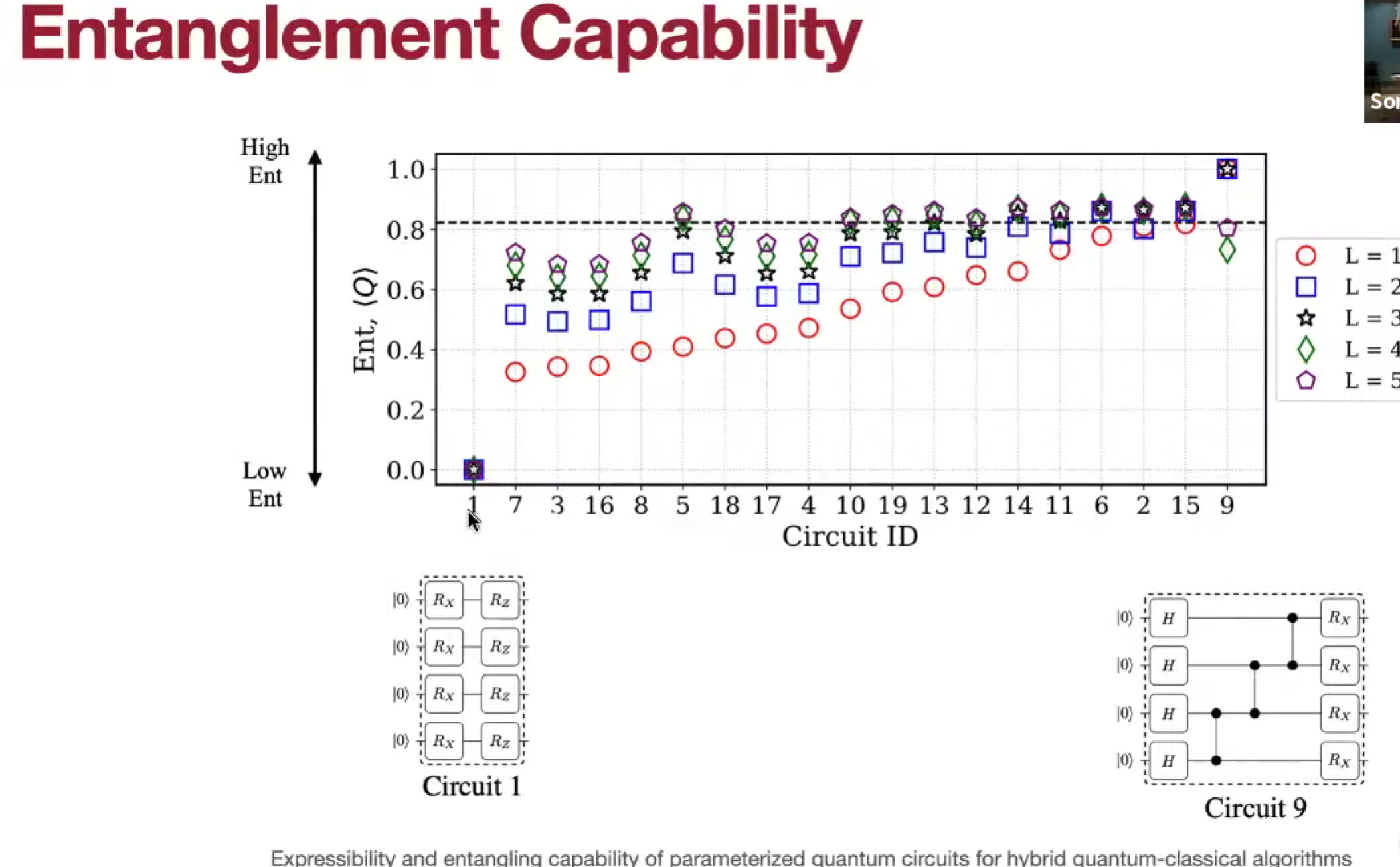
硬件效率